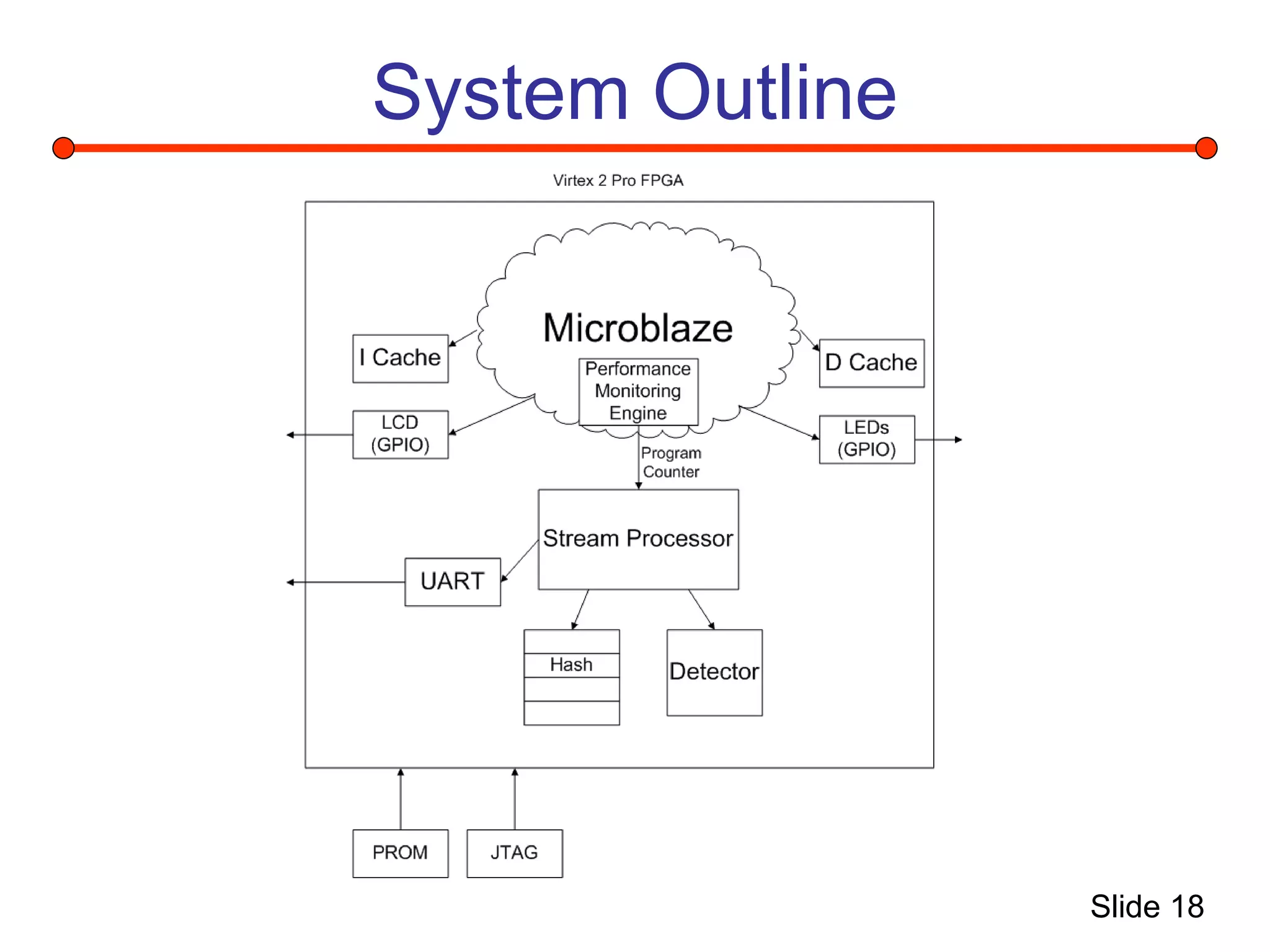
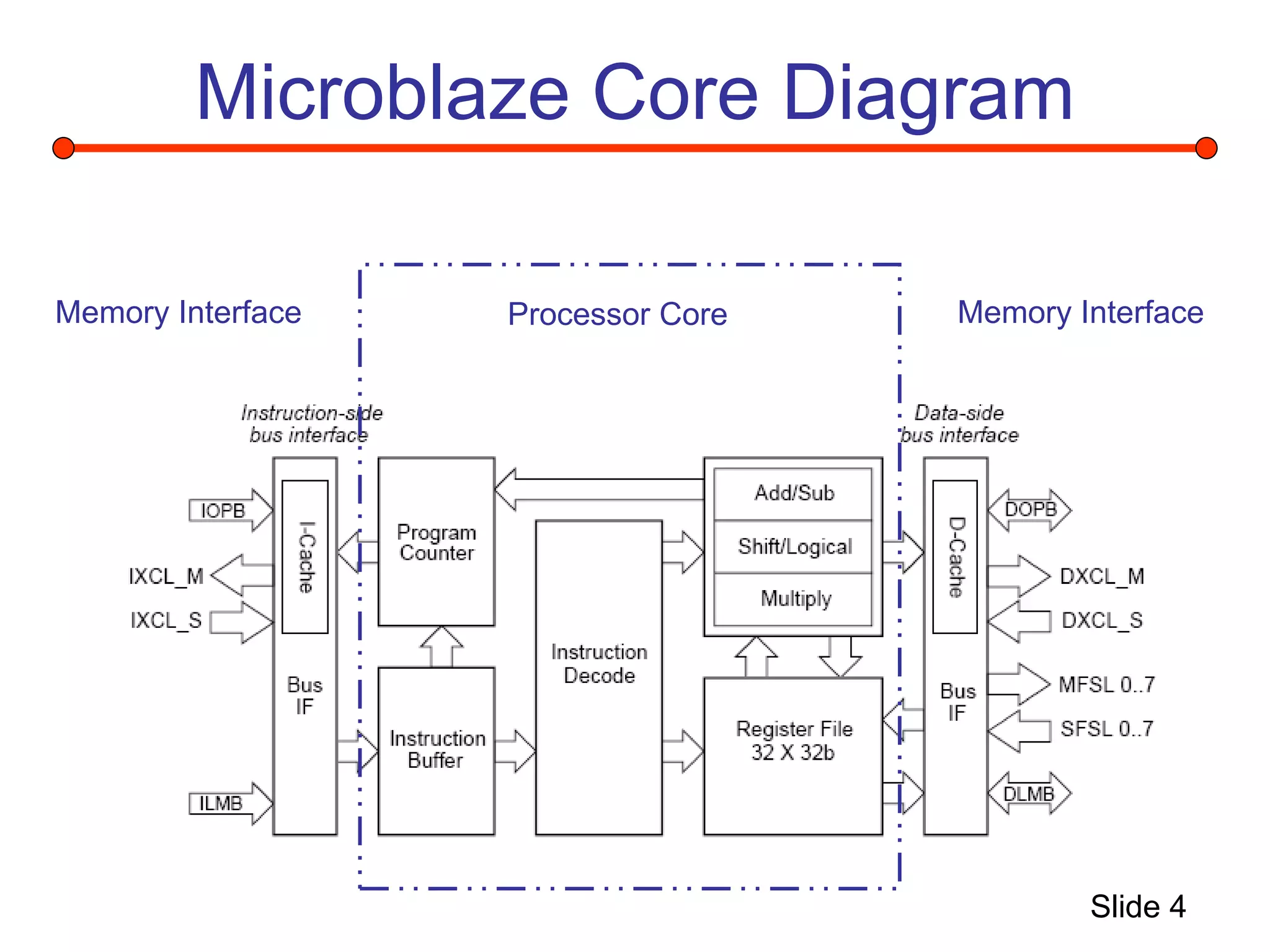
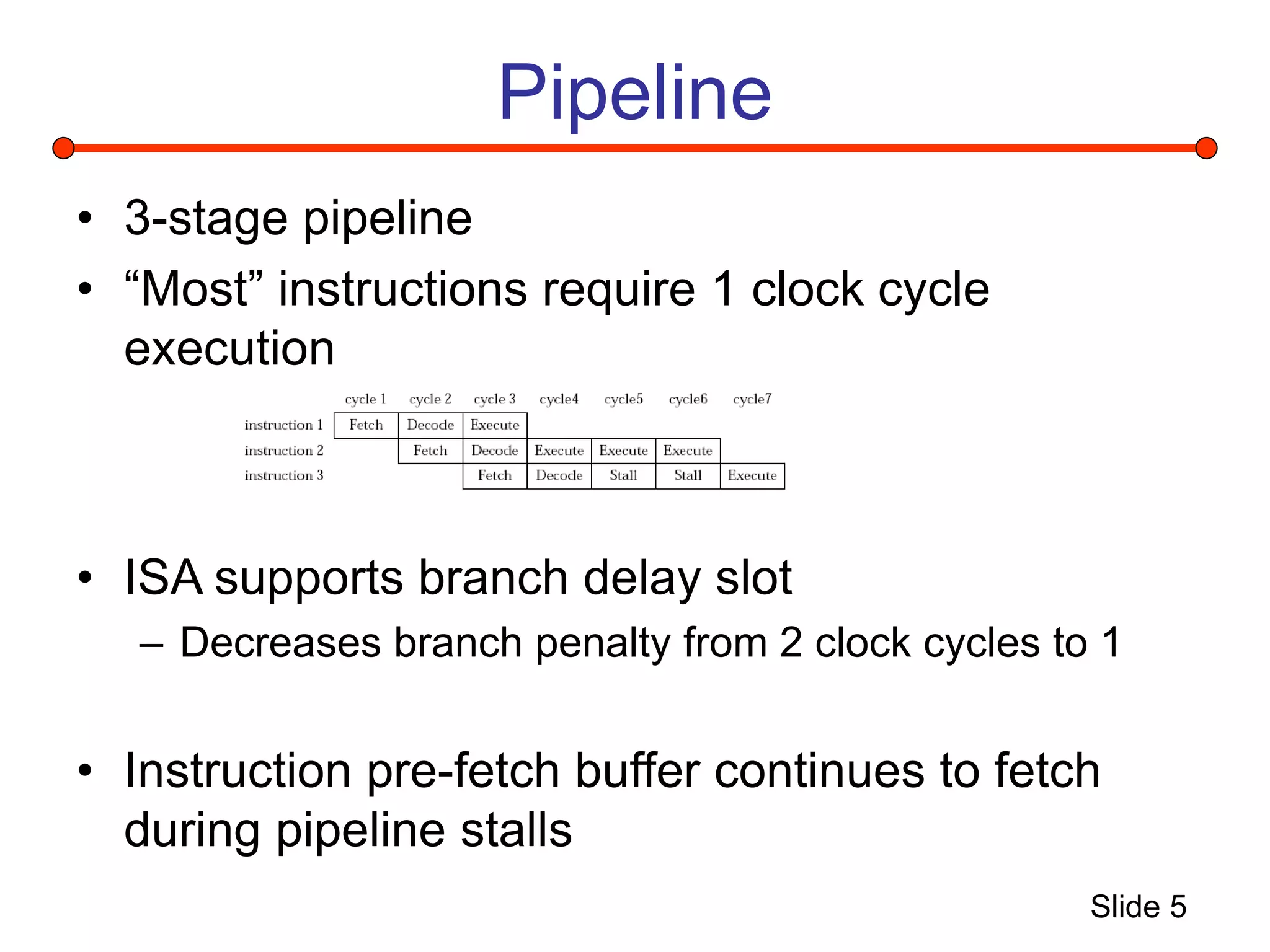
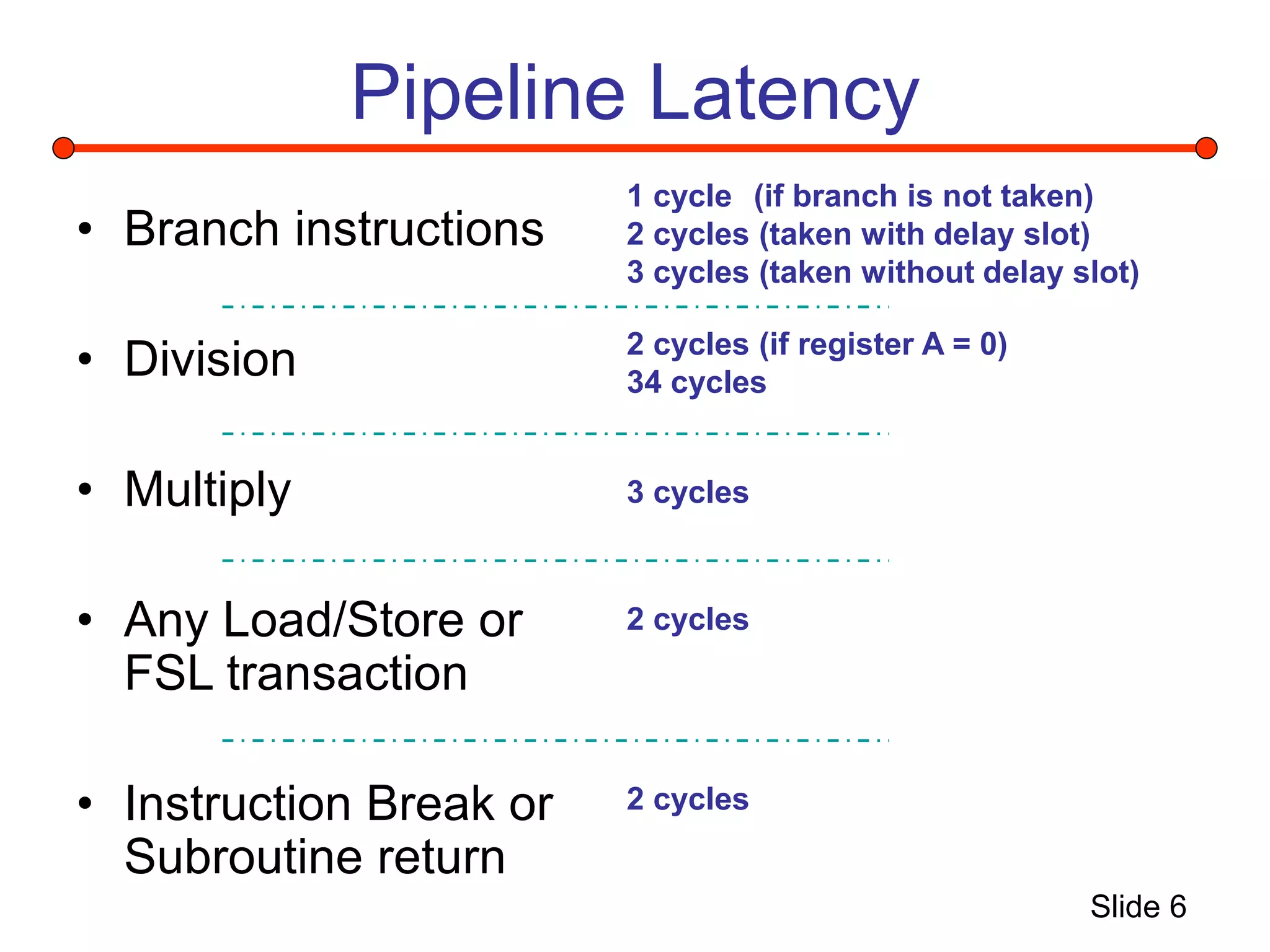
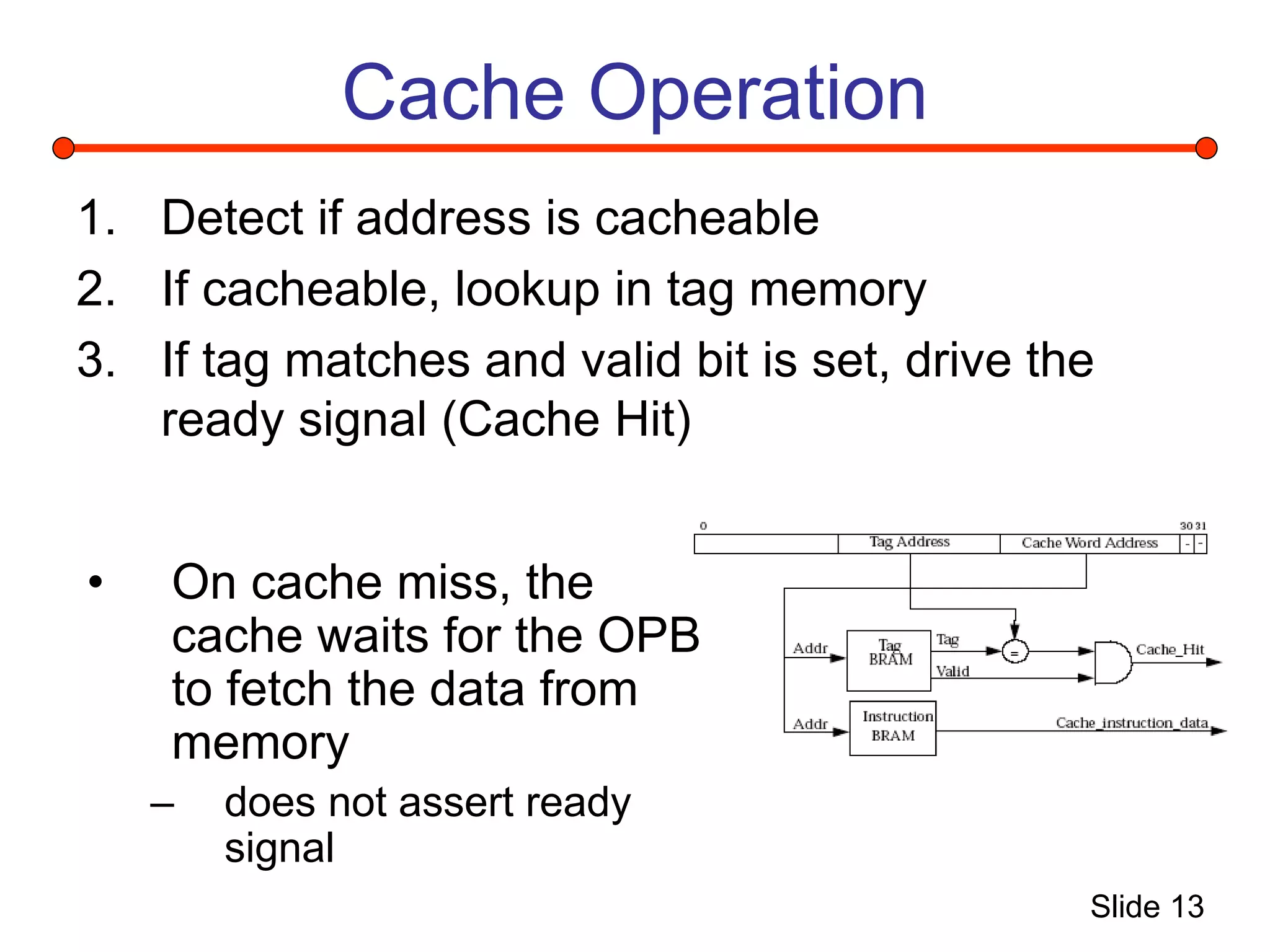
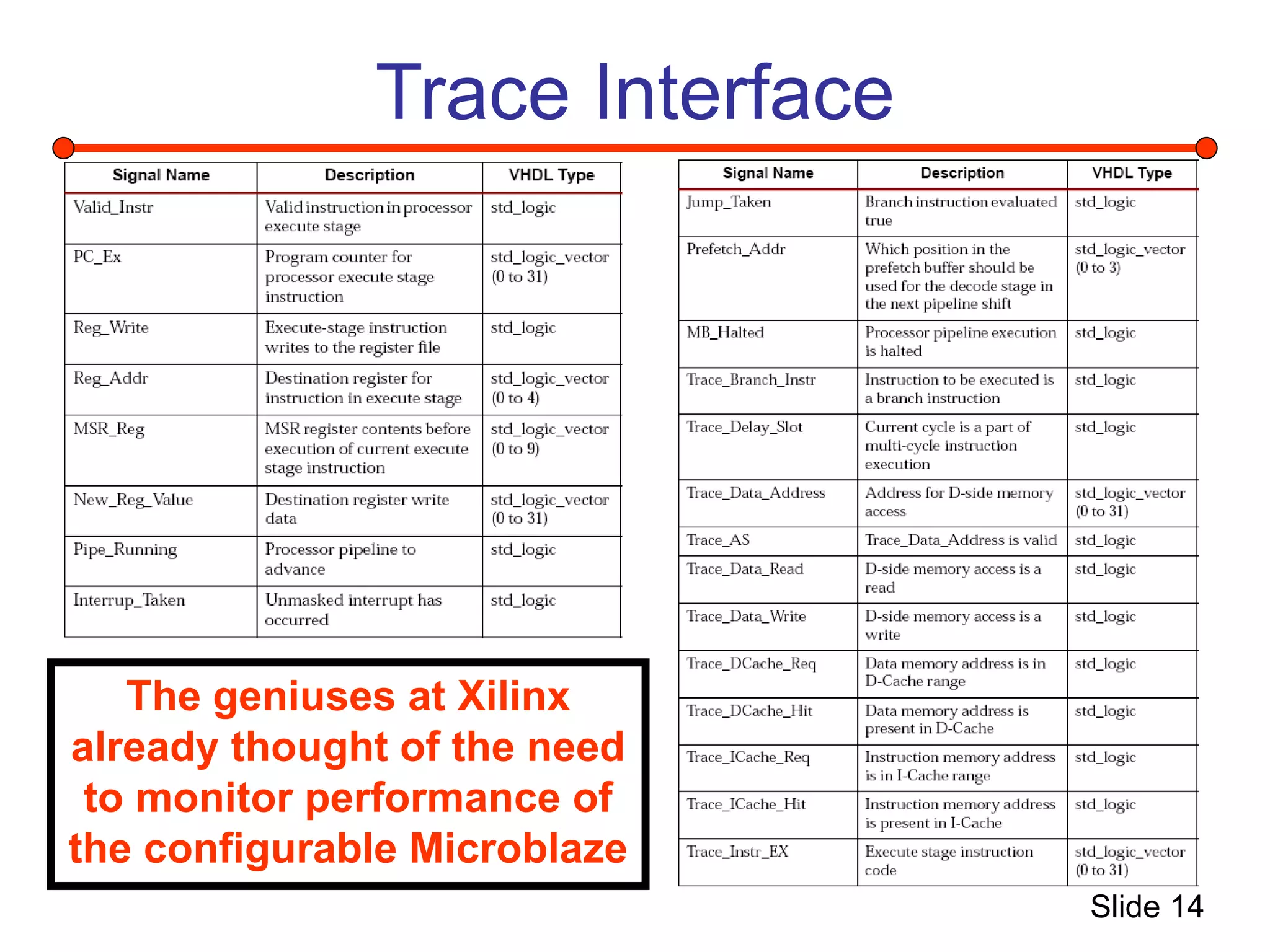
This document summarizes a project to implement a Microblaze soft processor on a Xilinx Virtex 2 Pro FPGA board and connect it to a performance monitoring engine. It describes the Microblaze architecture, implementing the system using Xilinx tools, and connecting a stream processing engine to monitor performance and detect instruction streams. Problems fitting the entire system on the FPGA due to resource limitations are discussed, along with solutions attempted like reducing block RAM usage and decreasing the processor clock.










![Slide 16
What is a Stream
• A stream is a block of instructions stored
consecutively in memory and executed
without branches
for (i=0; i<30; i++)
a += c[i];
Initialize
Execute
Terminate
Stream 1
Stream 2
Stream 3
Functional Blocks Streams](https://image.slidesharecdn.com/microblazeperformancemonitoringengine-230116200639-bfaf51b3/75/Microblaze-Performance-Monitoring-Engine-ppt-16-2048.jpg)