Download as PDF, PPTX







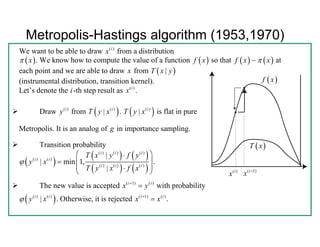









Markov Chain Monte Carlo (MCMC) methods use Markov chains to sample from probability distributions for use in Monte Carlo simulations. The Metropolis-Hastings algorithm proposes transitions to new states in the chain and either accepts or rejects those states based on a probability calculation, allowing it to sample from complex, high-dimensional distributions. The Gibbs sampler is a special case of MCMC where each variable is updated conditional on the current values of the other variables, ensuring all proposed moves are accepted. These MCMC methods allow approximating integrals that are difficult to compute directly.



















































![Human Reproduction [ Reproductive System ] Notes @irfanullah_mehar Irfanullah...](https://cdn.slidesharecdn.com/ss_thumbnails/humanreproductionreproductivesystemnotesirfanullahmeharirfanullahmeharjanantantra-260111172350-56e85778-thumbnail.jpg?width=640&height=640&fit=bounds)















