Download to read offline


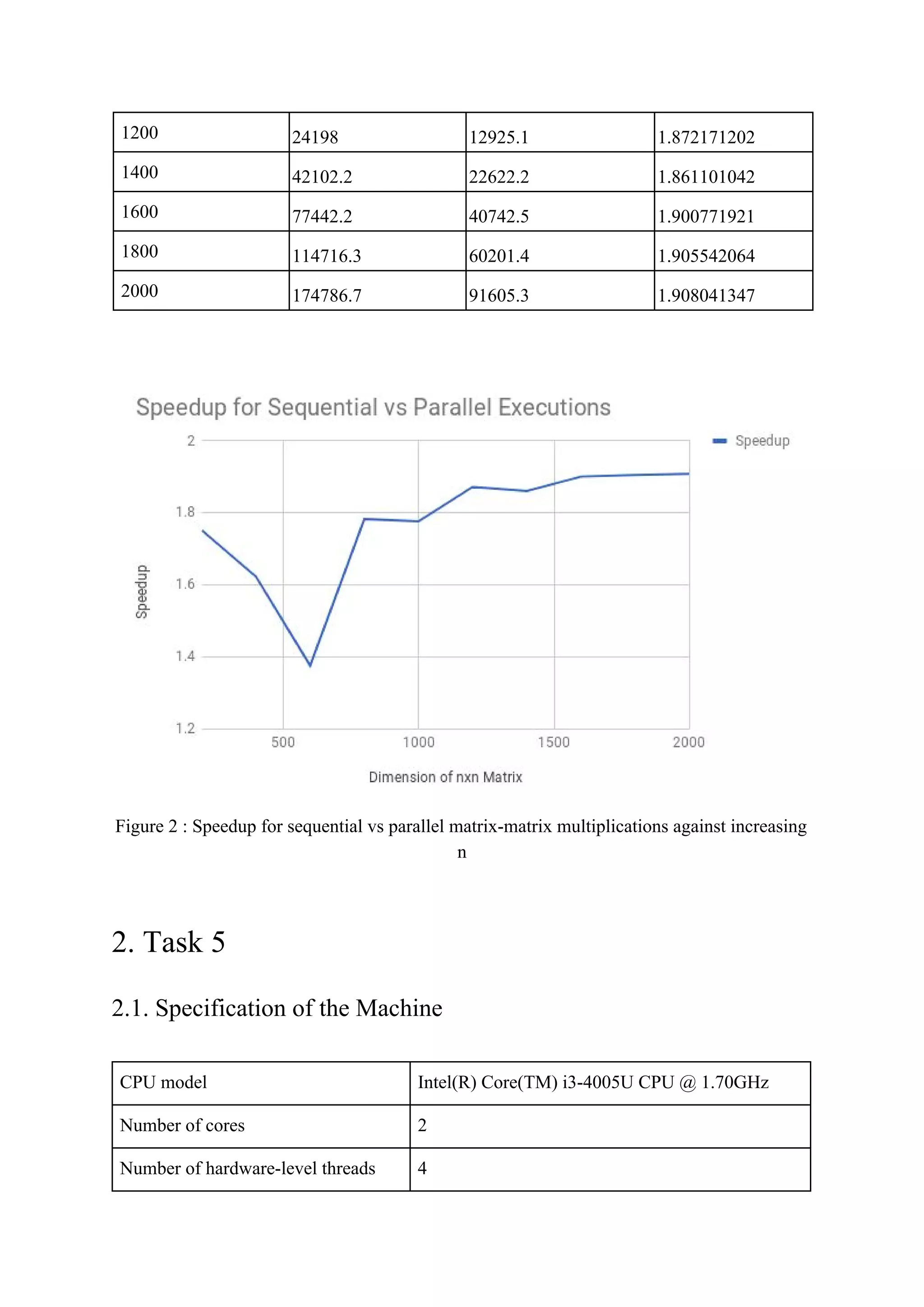




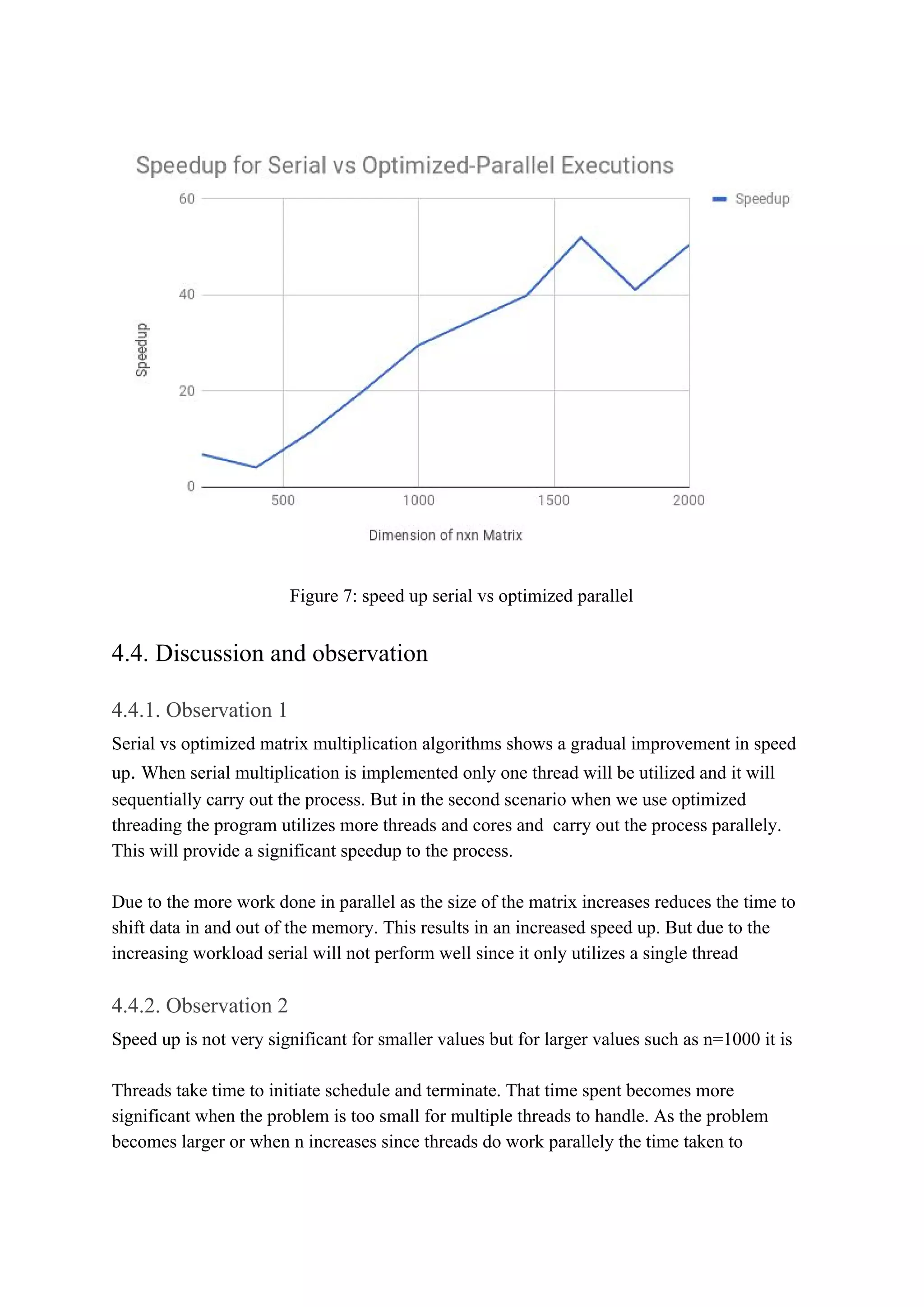
![schedule becomes less noteworthy. Therefore speedup is very significant when n is larger
than when n is smaller
4.4.3. Observation 3
We expect a gradual increase in speed up against increasing ‘n’
These may occur due to
● Threading
● Underlying CPU processes
● Cache misses
But even though there are minor fluctuations th graph offers a gradual increase in speed up
against increasing n
5. References
1] Uniprocessor Optimization of Matrix Multiplications and BLAS -
http://web.cs.ucdavis.edu/~bai/ECS231/optmatmul.pdf
2] optimizing for serial processors-
www.sdsc.edu/~allans/cs260/lectures/matmul.ppt](https://image.slidesharecdn.com/lab4-180303154839/75/Concurrent-Programming-14-2048.jpg)

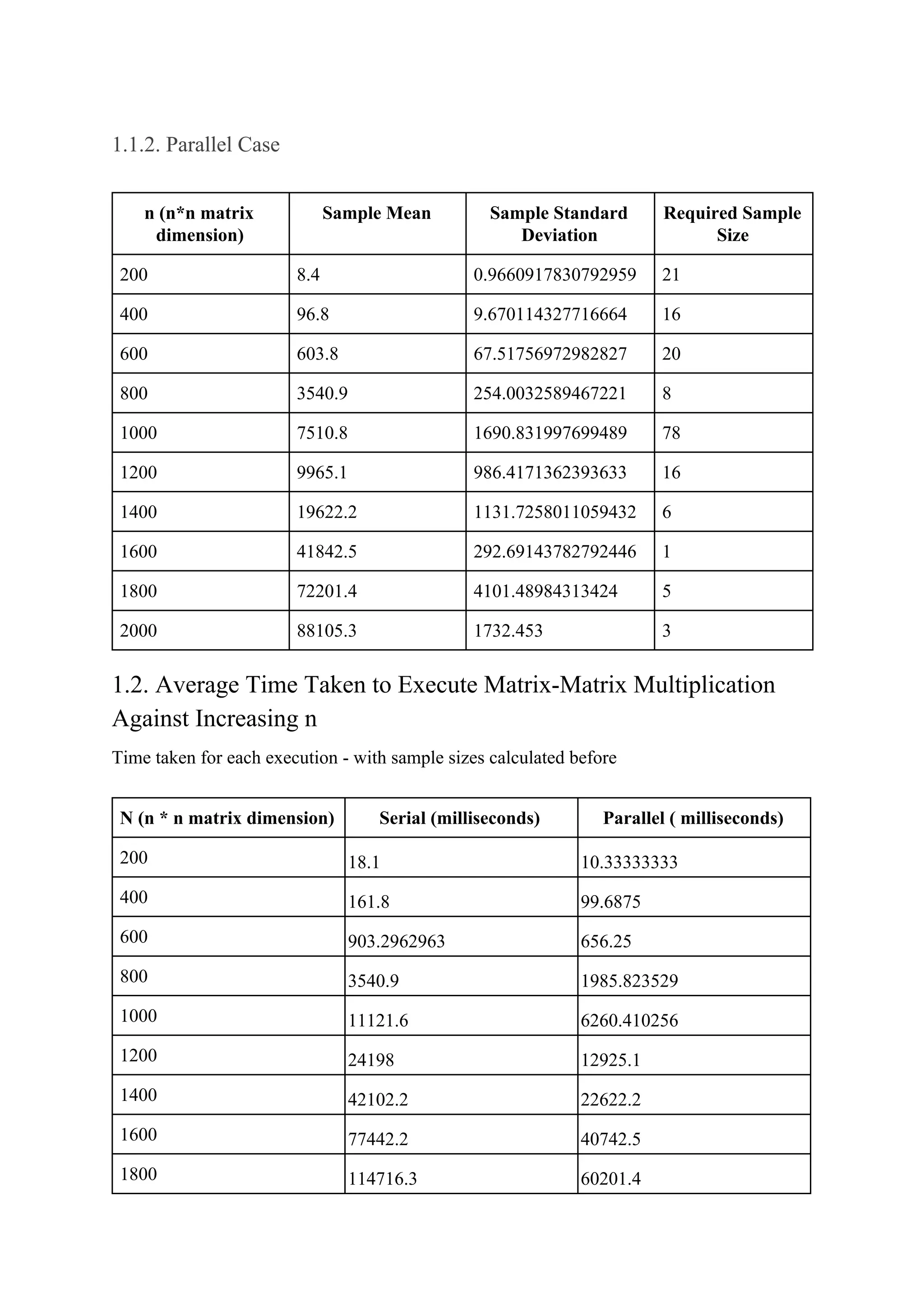
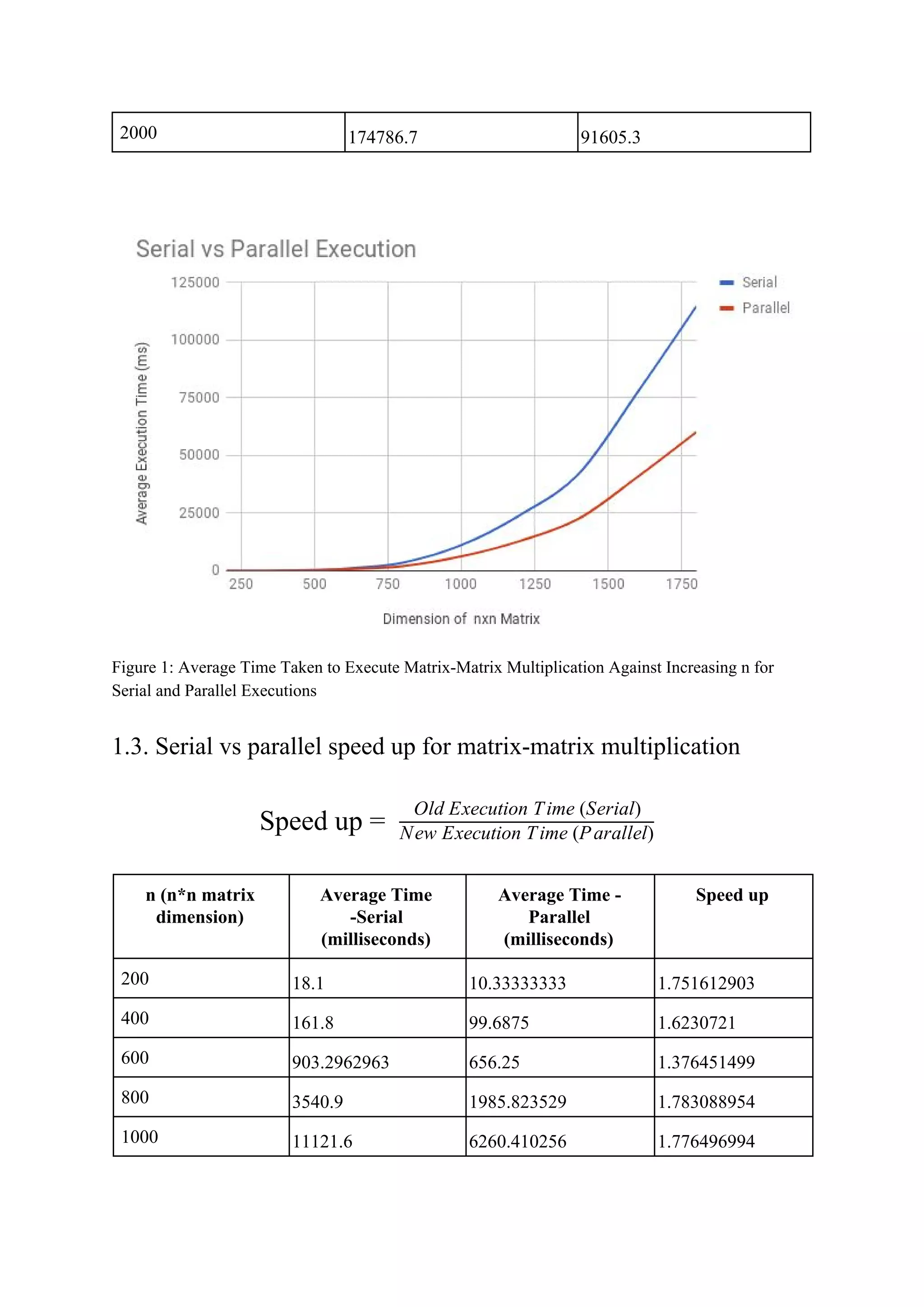
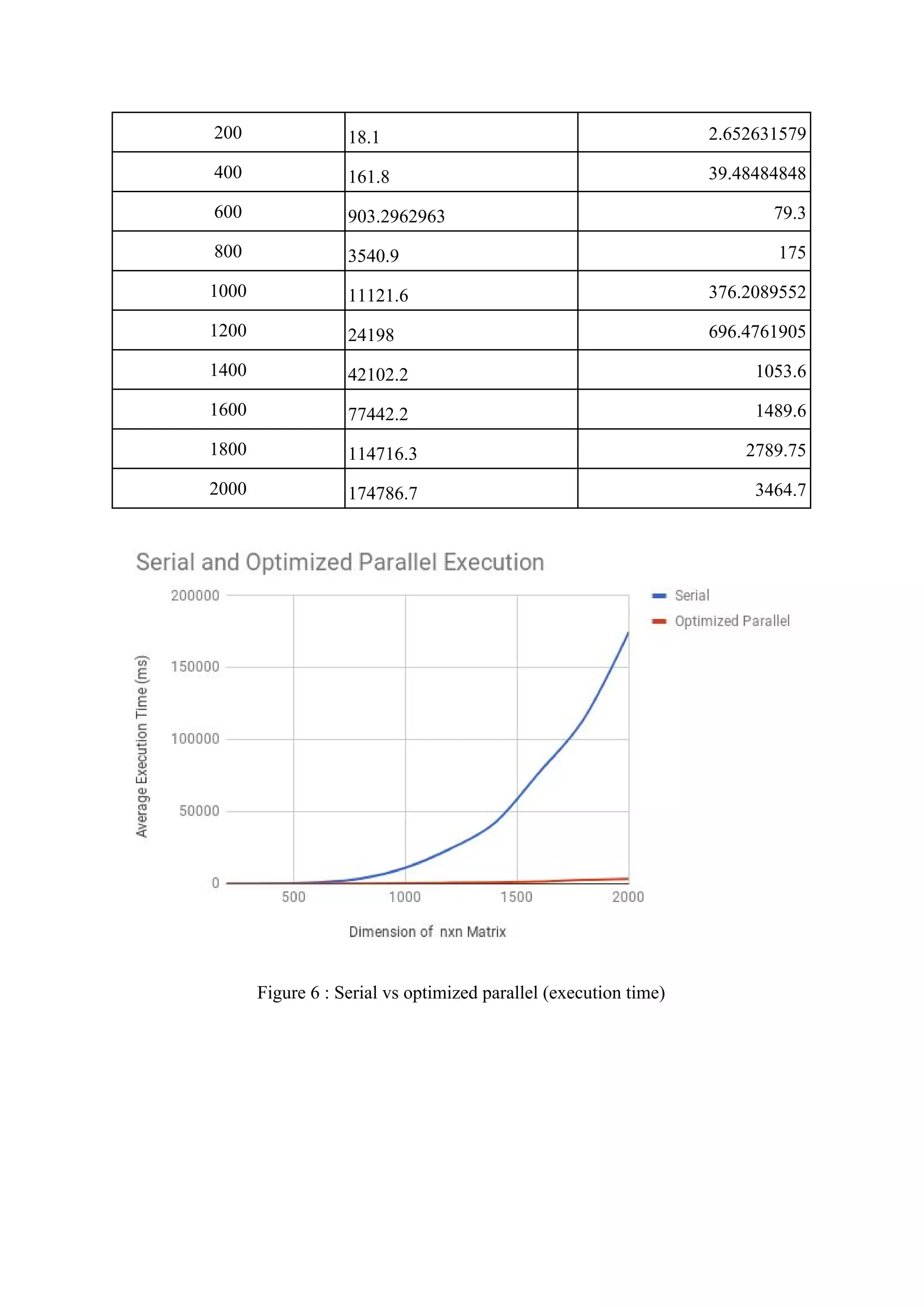
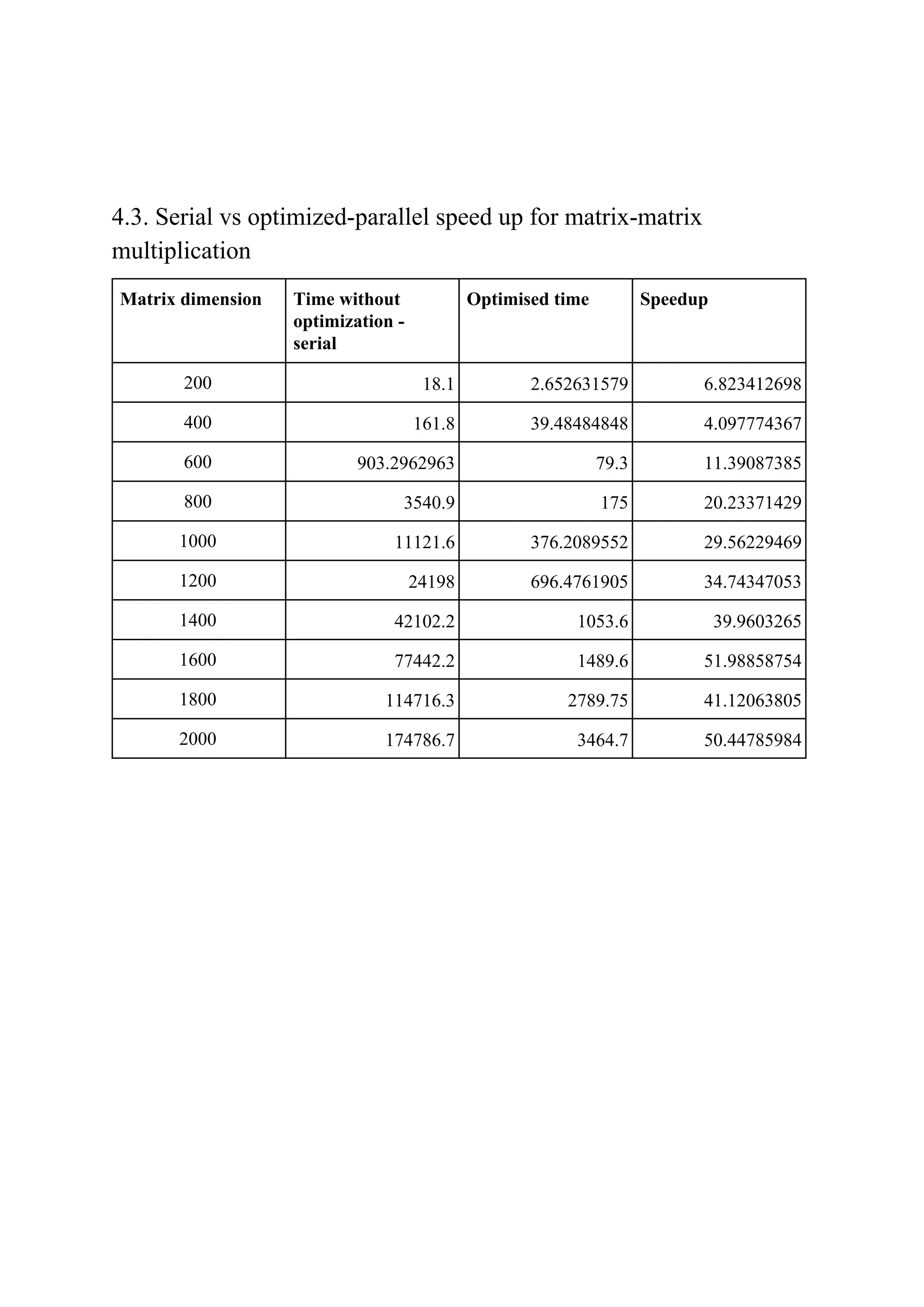
The document consists of a detailed analysis of matrix-matrix multiplication in concurrent programming, outlining various tasks and optimization methods for improving performance. It presents findings on sample sizes, execution times for serial and parallel executions, and speedup comparisons, emphasizing the impact of CPU architecture and threading. The document also discusses observations related to performance optimizations through various techniques, asserting that optimizations significantly enhance speed for larger matrix sizes.

















![[IJCT-V3I2P17] Authors: Sheng Lai, Xiaohua Meng, Dongqin Zheng](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p17-160609055723-thumbnail.jpg?width=640&height=640&fit=bounds)

















































