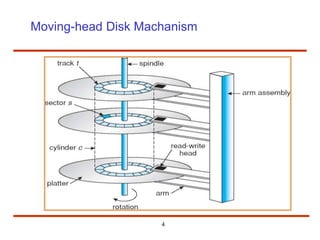
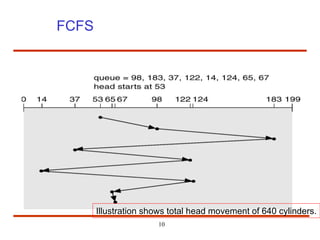
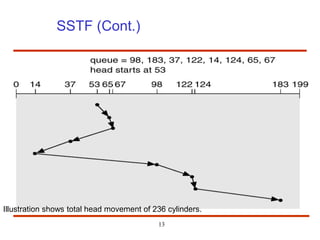
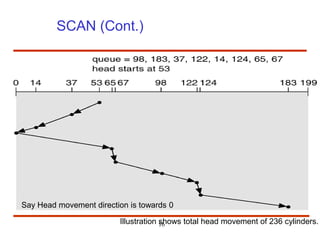
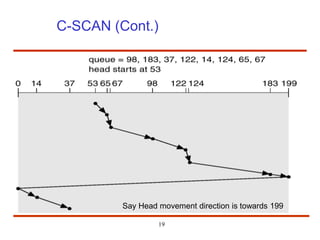
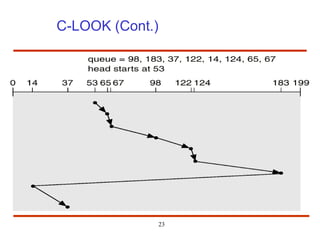
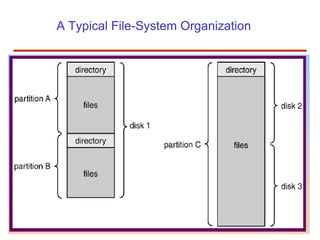
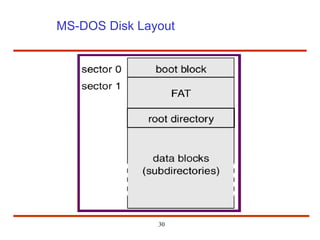
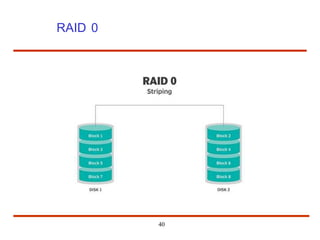
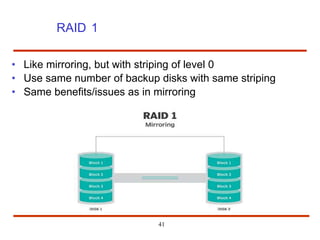
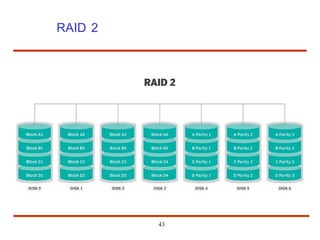
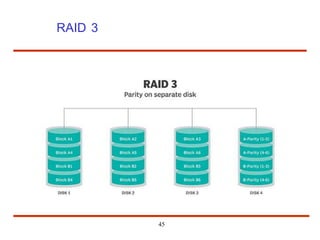
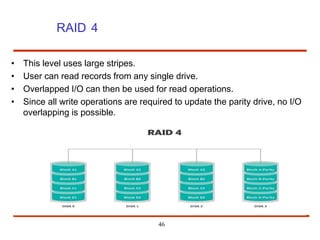
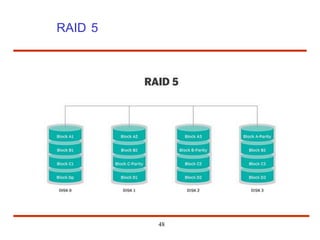
The document discusses the management and structure of secondary storage in computer systems, emphasizing the importance of disks for virtual memory management and file storage. It outlines various disk scheduling algorithms, disk formatting, partitioning, RAID systems, and the implications of bad blocks on disk reliability. The document also examines swap-space management as part of memory management, highlighting different perspectives on the allocation of swap space.













































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)









