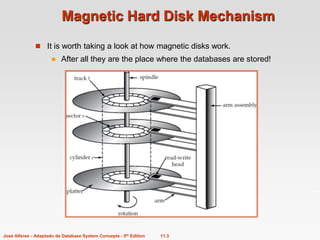
1. Magnetic disks are the primary storage medium for databases due to their large storage capacity and reliability. Disks store data in circular tracks divided into sectors, with read/write heads positioning over tracks to access data.
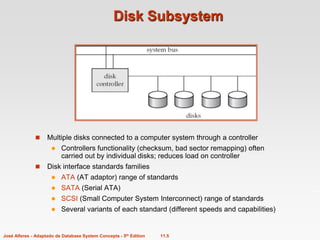
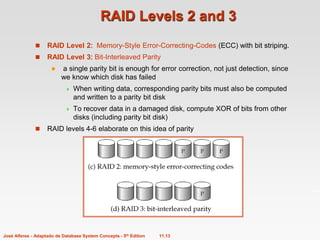
2. RAID (Redundant Arrays of Independent Disks) organizes multiple disks for improved performance, capacity, and reliability. Techniques like mirroring duplicate data across disks for fault tolerance, while striping distributes data across disks to enable parallel access.
3. Database designers must choose an appropriate RAID level based on factors like update frequency, capacity needs, and performance requirements to optimize the physical storage structure.