Download as PDF, PPTX


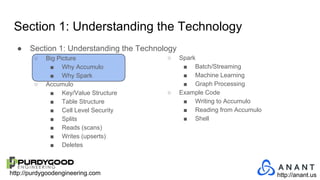

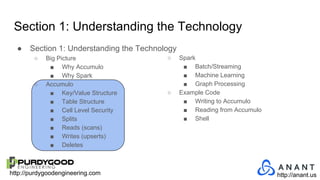
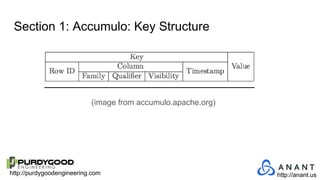
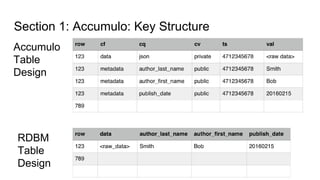






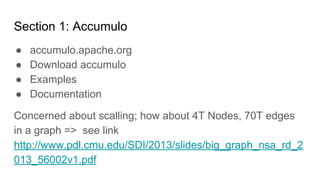
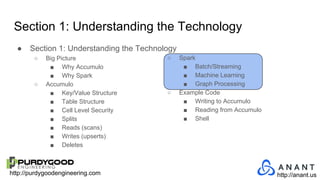



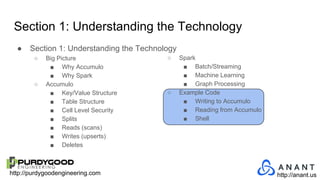

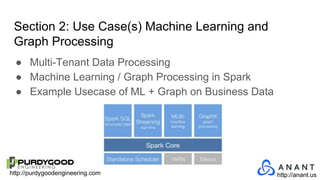
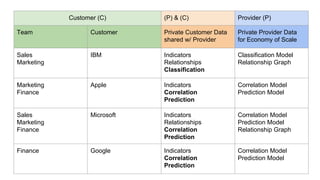
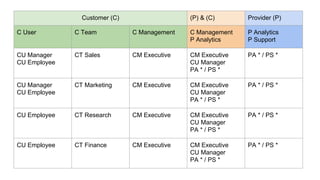


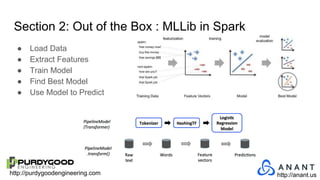


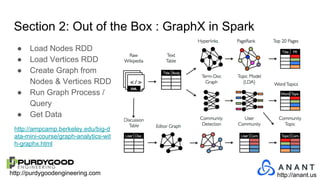




The document provides an overview of Accumulo and Spark technologies, detailing their key features, such as Accumulo's scalable key/value storage with cell-level security and Spark's general-purpose compute capabilities for batch and streaming data processing. It discusses specific use cases, including multi-tenant data processing and applications in machine learning and graph processing. Additionally, the document includes example code snippets and contact information for further inquiries.































































![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)








