04/05/2025 1
Machine learning& Data Mining Applications
Machine Learning
• Basics of ML(Machine Learning)
• Types of Machine Learning
• Machine Learning Algorithms
Data Mining Applications
• Introduction
• Data Mining Algorithms
•
2.
04/05/2025 2
Basics ofML(Machine Learning)
Defn: Machine Learning(ML)
is a system of computer algorithms that can learn from
example through self-improvement without being
explicitly coded by a programmer.
optimizes performance criterion using example data or
past experience.
is a part of artificial Intelligence which combines data
with statistical tools to predict an output which can be
used to make actionable insights.
Machine learning is closely related to data mining and
Bayesian predictive modeling.
3.
04/05/2025 3
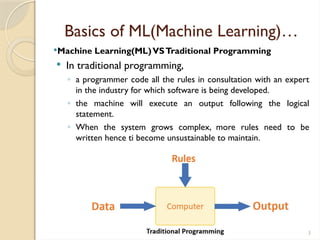
Basics ofML(Machine Learning)…
Machine Learning(ML)VSTraditional Programming
In traditional programming,
◦ a programmer code all the rules in consultation with an expert
in the industry for which software is being developed.
◦ the machine will execute an output following the logical
statement.
◦ When the system grows complex, more rules need to be
written hence ti become unsustainable to maintain.
4.
04/05/2025 4
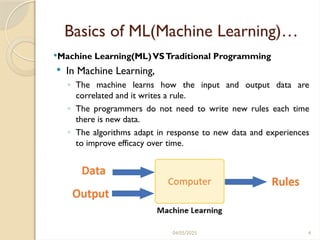
Basics ofML(Machine Learning)…
Machine Learning(ML)VSTraditional Programming
In Machine Learning,
◦ The machine learns how the input and output data are
correlated and it writes a rule.
◦ The programmers do not need to write new rules each time
there is new data.
◦ The algorithms adapt in response to new data and experiences
to improve efficacy over time.
5.
Basics of ML(MachineLearning)…
How well does a learned model generalize from the
data it was trained on to a new test set?
Training set (labels known) Test set (labels
unknown)
Slide credit: L. Lazebnik
Example 1.
Consider the following images
6.
04/05/2025 6
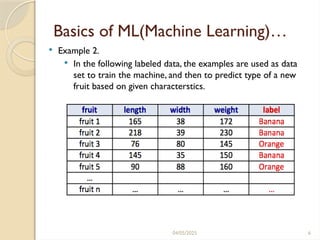
Basics ofML(Machine Learning)…
Example 2.
In the following labeled data, the examples are used as data
set to train the machine, and then to predict type of a new
fruit based on given characterstics.
7.
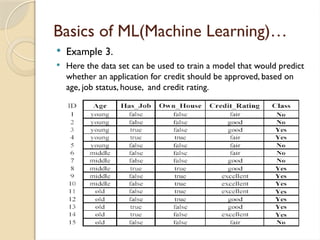
Basics of ML(MachineLearning)…
Example 3.
Here the data set can be used to train a model that would predict
whether an application for credit should be approved, based on
age, job status, house, and credit rating.
8.
Basics of ML(MachineLearning)…
From the above example 3, a model will be built
and then it will be used for prediction of new un-
seen future data?
◦ Learn a classification model from the data
◦ Use the model to classify future loan applications into
Yes (approved) and
No (not approved)
What is the class for following case/instance?
9.
04/05/2025 9
Basics ofML(Machine Learning)…
In the above Example 3, in predicting the new future’s
data classification, it could be rated to majority class
which gives accuracy of 9/15=60% this is without
training or machine learning.
But the machine will attempt to do better than 60%
10.
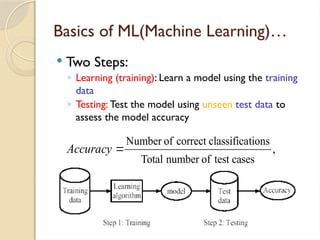
Basics of ML(MachineLearning)…
Two Steps:
◦ Learning (training): Learn a model using the training
data
◦ Testing: Test the model using unseen test data to
assess the model accuracy
,
cases
test
of
number
Total
tions
classifica
correct
of
Number
Accuracy
11.
04/05/2025 11
Basics ofML(Machine Learning)…
Consider the following is sample data for test from the
previous dataset example
If the model predicts the classes in the following
manner, then what is the Accuracy of the model?
Age Has_Job Own_House Credit_Rating
Actual
Class
Old TRUE FALSE Good Yes
Old TRUE FALSE excellent Yes
Old FALSE FALSE Fair No
Age Has_Job Own_House Credit_Rating
Predicte
d Class
Old TRUE FALSE Good Yes
Old TRUE FALSE excellent No
Old FALSE FALSE Fair Yes
12.
04/05/2025 12
Basics ofML(Machine Learning)…
The accuracy =1/3(True classications/TotalTest Data)
The confusion matrix is used to visualizes the accuracy of
a classifier by comparing the actual and predicted classes.
The binary confusion matrix is composed of squares:
It evaluates the performance of the classification models,
when they make predictions on test data, and tells how
good our classification model is.
13.
04/05/2025 13
Basics ofML(Machine Learning)…
The confusion matrix: is a performance measurement technique for
Machine learning classification.
It is a kind of table which helps to describe the performance of the
classification model on a set of test data .
True Negative: Model has given prediction No, and the real or actual value
was also No.
True Positive: The model has predicted yes, and the actual value was also true.
False Negative: The model has predicted no, but the actual value wasYes, it is
also called as Type-II error.
False Positive: The model has predictedYes, but the actual value was No. It is
also called a Type-I error.
n=Total Preductions
Actual
Yes No Total
Predicted
Yes TP FP P'
No FN TN N'
P N P+N
14.
04/05/2025 14
Basics ofML(Machine Learning)…
Hence for the above test data the confusion matrix
looks like:
=(1+0)/(1+0+1+1)===1/3
◦ =1/(1+1)=1/2
n=3
Actual
Yes No Total
Predicted
Yes 1 1 P‘=2
No 1 0 N‘=1
P=2 N=1 P+N=3
15.
Basics of ML(MachineLearning)…
Testing
Training
Generalization Error
Number of Training Examples
Error
Fixed prediction model
Slide credit: D. Hoiem
As the data set(training & test data) increases the
model’s error would decrease and vise versa.
16.
04/05/2025 16
Types ofMachine Learning
Machine learning can be grouped into two
broad learning tasks: Supervised and Unsupervised.
◦1/ Supervised Learning
An algorithm uses training data and feedback from humans to
learn the relationship of given inputs to a given output.
It uses labelled dataset to class catageries.
◦ There are two categories of supervised
learning:
Classification task
Regression task
17.
04/05/2025 17
Types ofMachine Learning…
Classification
◦ Imagine you want to predict the gender of a customer for a commercial.
◦ You will start gathering data on the height, weight, job, salary, purchasing
basket, etc. from your customer database.
◦ You know the gender of each of your customer, it can only be male or
female.
◦ The objective of the classifier will be to assign a probability of being a
male or a female (i.e., the label) based on the information (i.e., features
you have collected).
◦ When the model learned how to recognize male or female, you can use
new data to make a prediction.
◦ For instance, you just got new information from an unknown customer,
and you want to know if it is a male or female. If the classifier predicts
male = 70%, it means the algorithm is sure at 70% that this customer is a
male, and 30% it is a female.
18.
04/05/2025 18
Types ofMachine Learning…
Regression
◦ When the output is a continuous value, the task is a
regression.
◦ For instance, a financial analyst may need to forecast
the value of a stock based on a range of feature like
equity, previous stock performances, macroeconomics
index.
◦ The system will be trained to estimate the price of
the stocks with the lowest possible error.
19.
04/05/2025 19
Types ofMachine Learning…
Regression Example
Consider the values of two variables for eg. Income (y) and
investment(x) is which is obtained from campany dataset is
mapped on a graph as shown below.
The machine can be trained to develop a regular pattern or
formula that will represent the income in terms of investment:
y=a + bx [Where y=income, x=investment,a=constant, b=coeffecient]
20.
04/05/2025 20
Types ofMachine Learning…
Unsupervised learning
◦ Learning a model from unlabeled data.(e.g., explores
customer demographic data to identify patterns)
◦ You can use it when you do not know how to
classify the data, and you want the algorithm
to find patterns and classify the data for you
◦ Eg. Clustering: segmenting data set according
to their features.
21.
04/05/2025 21
Machine LearningAlgorithms
Following are examples of Algorithms that support
supervised Machine Learning
22.
04/05/2025 22
Machine LearningAlgorithms…
Following are examples of Algorithms that support
Unsupervised Machine Learning
23.
04/05/2025 23
Machine LearningAlgorithms…
Linear Regression
◦ is type of supervised machine learning that uses predictor
variable and dependant variable.
◦ Applies to variables of continousValues.
Logistic Regression
◦ Logistic regression is one of the most popular machine learning
algorithms for binary classification.
◦ In linear regression theY variable is always a continuous variable.
If suppose, the Y variable was categorical, you cannot use linear
regression model it.
◦ Logistic regression is a classic predictive modelling technique
and still remains a popular choice for modelling binary
categorical variables.
24.
04/05/2025 24
Machine LearningAlgorithms…
Logistic Regression..
◦ Unlike linear regression, the output is transformed into a
probability using the logistic function:
◦ Logistic regression achieves this by taking the log odds of
the event log(P/1-P),
where, P is the probability of event. So P always lies between 0
and 1.
◦ Logistic regressions work with odds which are simply the
ratio of the proportions for the two possible outcomes.
◦ The log odds are modeled as a linear function of the
explanatory variable:
25.
04/05/2025 25
Machine LearningAlgorithms…
Decision Tree
◦ IsType of Supervised Machine learning Algorithm
◦ Creates a model that predicts the value of a target variable, for
which the decision tree uses the tree representation to solve
the problem.
◦ In decision tree the leaf node corresponds to a class label and
attributes are represented on the internal node of the tree.
26.
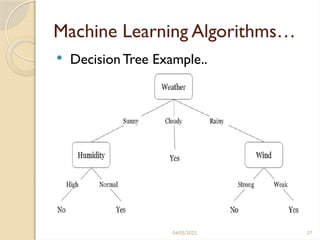
04/05/2025 26
Machine LearningAlgorithms…
DecisionTree Example
Considering the data set below with target
class play, then it will generate a decision tree.
04/05/2025 28
Machine LearningAlgorithms…
Popular DecisionTree algorithms include:
ID3 (extension of D3)
→
C4.5 (successor of ID3)
→
CART (Classification And Regression Tree)
→
CHAID (Chi-square automatic interaction detection Performs
→
multi-level splits when computing classification trees)
MARS (multivariate adaptive regression splines)
→
29.
04/05/2025 29
Machine LearningAlgorithms…
K-Means Clustering
◦ IsType of UnSupervised Machine learning Algorithm
◦ It make inferences from datasets using only input without
referring to known, or labelled, outcomes.
◦ In K means clustering you’ll define a target number k, which
refers to the number of centroids you need in the dataset.
◦ A centroid is the imaginary or real location representing the
center of the cluster.
Every data point is allocated to each of the clusters through
reducing the in-cluster sum of squares.
◦ The ‘means’ in the K-means refers to averaging of the data; that
is, finding the centroid.
30.
04/05/2025 30
Machine LearningAlgorithms…
Aritificial Neural Network
◦ A Neural Network is asystem composed of many simple
processing elements operating in parallel which can acquire, store,
and utilize experiential knowledge.
◦ A nerve cell neuron (in biological neuron) is a special biological
cell that processes information(having similarities with the ANN:
for example dendrites—same to input neuron ,Axions—same to
output neurons in ANN).
◦ The learning algorithm of a neural network can either be
supervised or unsupervised.
◦ A neural net is said to learn supervised, if the desired output is
already known otherwise it is Unspervised.
◦ Unsupervised Learnig algorithms of ANN are more applicable in
vast areas.
31.
04/05/2025 31
Machine LearningAlgorithms…
Aritificial Neural Network
◦ Computational models inspired by the human brain:
Algorithms that try to mimic the brain.
Massively parallel, distributed system, made up of simple
processing units (neurons)
Synaptic connection strengths among neurons are used to
store the acquired knowledge.
Knowledge is acquired by the network from its
environment through a learning process
32.
04/05/2025 32
Machine LearningAlgorithms…
An artificial neural network
◦ has dozens of artificial neurons—called units—
arranged in a series of layers.
◦ The input layer receives various forms of
information from the outside world.
◦ This is the data that the network aims to process
or learn about.
◦ From the input unit, the data goes through one or
more hidden units.
◦ The hidden unit’s job is to transform the input
into something the output unit can use.
33.
04/05/2025 33
Machine LearningAlgorithms…
Artificial Neural Network
◦ Training Neural Networks is a NON
CONVEX OPTIMIZATION PROBLEM.
◦ This means we can run into many local
optima during training.
◦ We need to first perform a forward pass
◦ Then, we update weights with a backward
pass(Back ward Prop)
34.
04/05/2025 34
Machine LearningAlgorithms…
ANNs have been widely used in various domains for:
Pattern recognition
Function approximation
Associative memory
35.
04/05/2025 35
Machine LearningAlgorithms…
Properties of ANN
◦ Inputs are flexible
any real values
Highly correlated or independent
◦ Target function may be discrete-valued, real-valued, or
vectors of discrete or real values
Outputs are real numbers between 0 and 1
◦ Long training time & Fast evaluation
36.
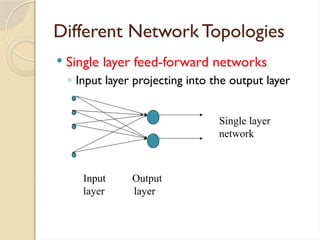
Different Network Topologies
Single layer feed-forward networks
◦ Input layer projecting into the output layer
Input Output
layer layer
Single layer
network
37.
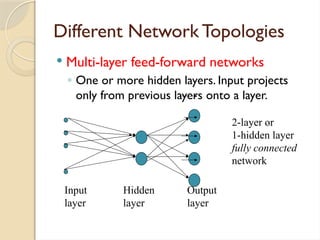
Different Network Topologies
Multi-layer feed-forward networks
◦ One or more hidden layers. Input projects
only from previous layers onto a layer.
Input Hidden Output
layer layer layer
2-layer or
1-hidden layer
fully connected
network
38.
Different Network Topologies
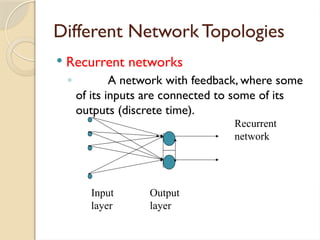
Recurrent networks
◦ A network with feedback, where some
of its inputs are connected to some of its
outputs (discrete time).
Input Output
layer layer
Recurrent
network
39.
04/05/2025 39
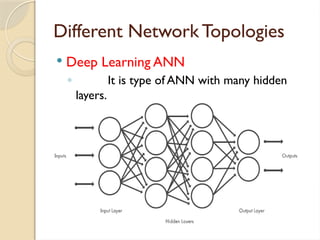
Different NetworkTopologies
Deep Learning ANN
◦ It is type of ANN with many hidden layers.
◦ Deep Learning is nothing but stacking multiple
such hidden layers between the input and the
output layer, hence the name Deep learning
40.
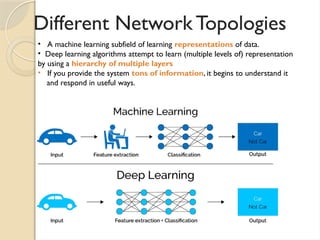
• A machinelearning subfield of learning representations of data.
• Deep learning algorithms attempt to learn (multiple levels of) representation
by using a hierarchy of multiple layers
• If you provide the system tons of information, it begins to understand it
and respond in useful ways.
Different Network Topologies
04/05/2025 42
Different NetworkTopologies
Deep Learning Methods
◦ There are various methods designed to apply deep learning.
◦ Each proposed method has a specific use case like
the kind of data you have, whether it is supervised or
unsupervised learning
type of task you would want to solve with the data.
◦ So depending on these factors, you choose one of the methods
that can best solve your problem.
◦ Some of the deep learning methods are:
Convolutional Neural Network,
Recurrent Neural Network,
Long short-term memory,
43.
04/05/2025 43
Data Mining--Introducation
Data mining (knowledge discovery from data)
◦ Extraction of interesting (non-trivial, implicit, previously
unknown and potentially useful) patterns or knowledge from
huge amount of data
◦ Data mining: a misnomer?
Alternative names
◦ Knowledge discovery (mining) in databases (KDD),
◦ knowledge extraction,
◦ data/pattern analysis,
◦ data archeology, data dredging, information harvesting, business
intelligence, etc.
44.
CS590D 44
Data Mining—Introducation…
DataMining
Knowledge Mining
Knowledge Discovery
in Databases
Data Dredging
Database Mining
Knowledge Extraction
Data Pattern Processing
Information Harvesting
Siftware
The process of discovering meaningful new correlations, patterns,
and trends by sifting through large amounts of stored data, using
pattern recognition technologies and statistical and mathematical
techniques
Data Archaeology
Alternate Names for Data mining:
45.
46
Data Mining—Introducation…
Datamining is the analysis of (often large) observational
data sets to find unsuspected relationships and to
summarize the data in novel ways that are both
understandable and
useful to the data owner
The relationships and summaries derived through a data
mining exercise are often referred to as models or patterns.
Examples include
◦ linear equations,
◦ rules, clusters,
◦ graphs,
◦ tree structures, and
◦ recurrent patterns in time series.
46.
47
Data Mining—Introducation..
Datamining typically deals with data that have already been
collected for some purpose other than the data mining
analysis (for example, they may have been collected in order
to maintain an up-to-date record of all the transactions in a
bank).
This means that the objectives of the data mining exercise do
not focus on the data collection strategy.
This is one way in which data mining differs from much of
statistics, in which data are often collected by using efficient
strategies to answer specific questions.
For this reason, data mining is often referred to as
"secondary" data analysis.
47.
48
Data Mining—Introducation..
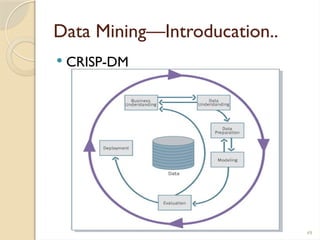
TheCross-Industry Standard Process for Data Mining
(CRISP–DM) [16] was developed in 1996 by analysts
provides a nonproprietary and freely available standard
process for fitting data mining into the general problem-
solving strategy of a business or research unit.
According to CRISP–DM, a given data mining project
has a life cycle consisting of six phases, as illustrated in
Figure below.
50
Data Mining—Introducation..
Classification:predicting an item class
Clustering: finding clusters in data
Associations: e.g.A & B & C occur frequently
Outliner Detection: finding changes
Regression Analysis: predicting a
continuous value
Trend Analysis: finding relationships
…
50.
51
Data mining—Potential Applications
Data analysis and decision support
◦ Market analysis and management
Target marketing, customer relationship management (CRM), market
basket analysis, cross selling, market segmentation
◦ Risk analysis and management
Forecasting, customer retention, improved underwriting, quality
control, competitive analysis
◦ Fraud detection and detection of unusual patterns (outliers)
Other Applications
◦ Text mining (news group, email, documents) andWeb mining
◦ Stream data mining
◦ DNA and bio-data analysis
51.
52
Data mining—Potential Applications..
Market Analysis and Management
◦ Target marketing
Find clusters of “model” customers who share the same
characteristics: interest, income level, spending habits, etc.
Determine customer purchasing patterns over time
◦ Cross-market analysis
Associations/co-relations between product sales, & prediction based
on such association
◦ Customer profiling
What types of customers buy what products (clustering or
classification)
◦ Customer requirement analysis
identifying the best products for different customers
predict what factors will attract new customers
◦ Provision of summary information
multidimensional summary reports
statistical summary information (data central tendency and variation)
52.
53
Data mining—Potential Applications..
Corporate Analysis & Risk Management
◦ Finance planning and asset evaluation
cash flow analysis and prediction
contingent claim analysis to evaluate assets
cross-sectional and time series analysis (financial-ratio, trend
analysis, etc.)
◦ Resource planning
summarize and compare the resources and spending
◦ Competition
monitor competitors and market directions
group customers into classes and a class-based pricing
procedure
set pricing strategy in a highly competitive market
53.
54
Data mining—Potential Applications..
Fraud Detection & Mining Unusual Patterns
◦ Approaches: Clustering & model construction for frauds, outlier
analysis
◦ Applications: Health care, retail, credit card service, telecomm.
Auto insurance: ring of collisions
Money laundering: suspicious monetary transactions
Medical insurance
Professional patients, ring of doctors, and ring of references
Unnecessary or correlated screening tests
Telecommunications: phone-call fraud
Phone call model: destination of the call, duration, time of day or week.
Analyze patterns that deviate from an expected norm
Retail industry
Analysts estimate that 38% of retail shrink is due to dishonest employees
Anti-terrorism
54.
55
Data Mining Algorithms
As Data mining is considered to be the
process of extracting useful information from
a vast amount of data, it employs data
preparation, training, testing and
interperation and deployment steps.
It mainly involves machine learning
techniques.
So while data mining needs machine
learning, machine learning doesn’t necessarily
need data mining.
55.
56
Data Mining Algorithms
Hence the machine learning algorithms
are used also in data mining applications.
These includes:
◦ Decision tree
◦ k-Means
◦ linear regression
◦ ANN(Artificial Neural Networks)
◦ etc.
56.
57
Data Mining& MachineLearning Research
Areas
Following are some thematic areas for
data mining researches:
◦ Fraud Detection(for banks, telecom, etc)
◦ Market Analysis/Stock Market Analysis
◦ Customer trend analysis(CRM)
◦ Financial Analysis(Profit analysis)
◦ Website Evaluation(Web mining)
◦ Weather Forecasting using Data Mining
57.
58
Data Mining& MachineLearning Research Areas…
Fraud Detection
◦ The number of frauds in daily life is increasing in sectors like
banking, finance, and government.
◦ Accurate detection of fraud is a challenge.
◦ Data mining techniques help in anticipation and detection of
fraud.
◦ Data mining tools can be used to spot patterns and detect fraud
transactions.
◦ Through data mining, factors leading to fraud can be determined.
58.
59
Data Mining& MachineLearning Research Areas…
Web Mining
◦ Web Mining is an application of Data Mining and an important
research area.
◦ It is a technique to discover patterns from WWW i.e World
WideWeb.
◦ The information for web mining is collected through browser
activities, page content and server logins.
◦ There are three types ofWeb Mining:
Web Usage Mining
Web Content Mining
Web Structure Mining
59.
60
Data Mining& MachineLearning Research Areas…
Opinion Mining
◦ Opinion mining, also known as sentiment mining, is a natural language
processing method to analyze the sentiments of customers about a
particular product.
◦ It is widely used in areas like surveys, public reviews, social media,
healthcare systems, marketing etc.
◦ Automated opinion mining employs machine learning algorithms to
analyze the sentiments.













![04/05/2025 19
Types of Machine Learning…
Regression Example
Consider the values of two variables for eg. Income (y) and
investment(x) is which is obtained from campany dataset is
mapped on a graph as shown below.
The machine can be trained to develop a regular pattern or
formula that will represent the income in terms of investment:
y=a + bx [Where y=income, x=investment,a=constant, b=coeffecient]](https://image.slidesharecdn.com/selectedtopicsincs-ch-2-250405040456-00a31bdd/85/Selected-Topics-in-CS-CHapter-twooo-pptx-19-320.jpg)





















![48
Data Mining—Introducation..
The Cross-Industry Standard Process for Data Mining
(CRISP–DM) [16] was developed in 1996 by analysts
provides a nonproprietary and freely available standard
process for fitting data mining into the general problem-
solving strategy of a business or research unit.
According to CRISP–DM, a given data mining project
has a life cycle consisting of six phases, as illustrated in
Figure below.](https://image.slidesharecdn.com/selectedtopicsincs-ch-2-250405040456-00a31bdd/85/Selected-Topics-in-CS-CHapter-twooo-pptx-47-320.jpg)





































![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)





















