Downloaded 56 times






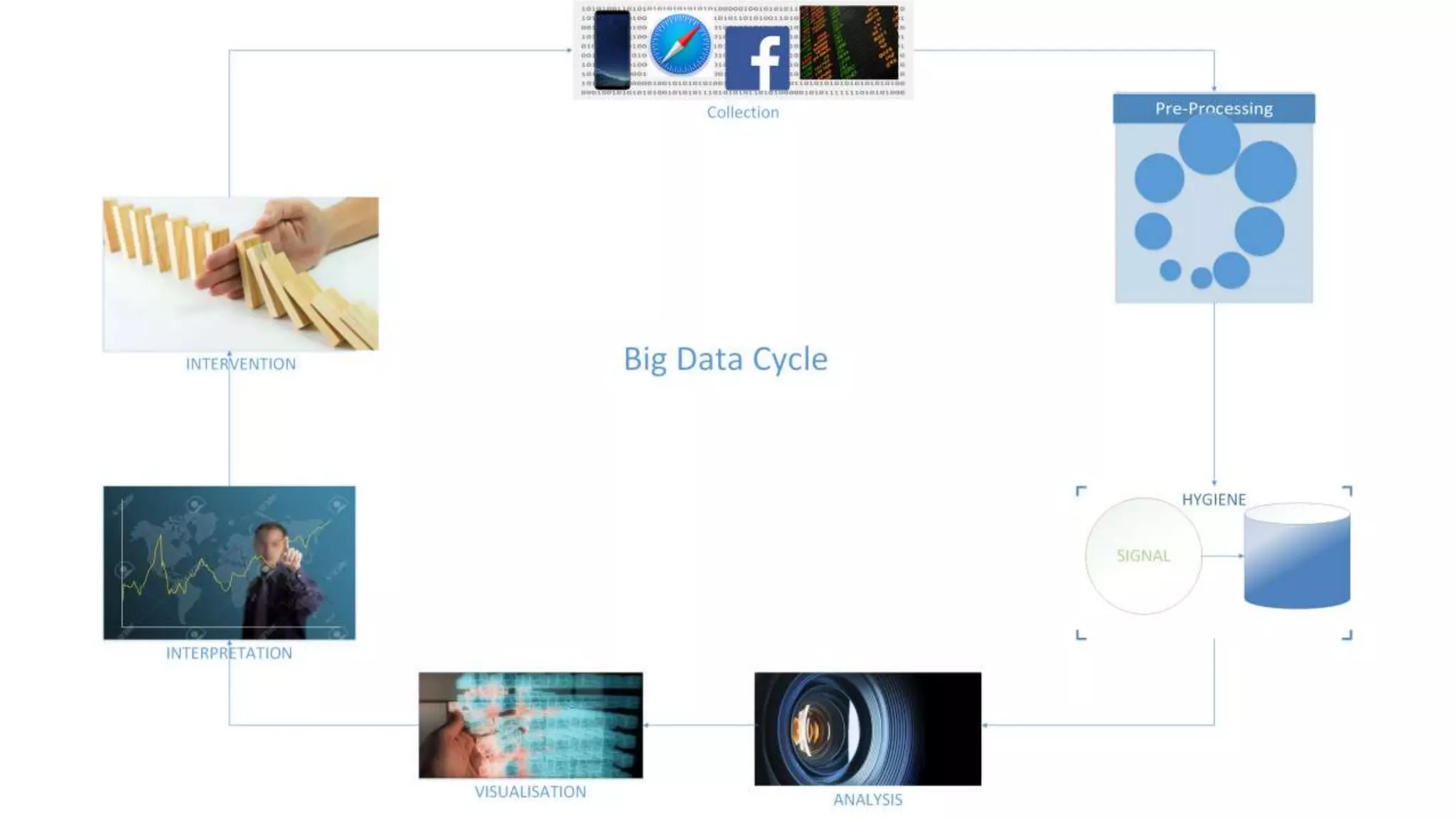
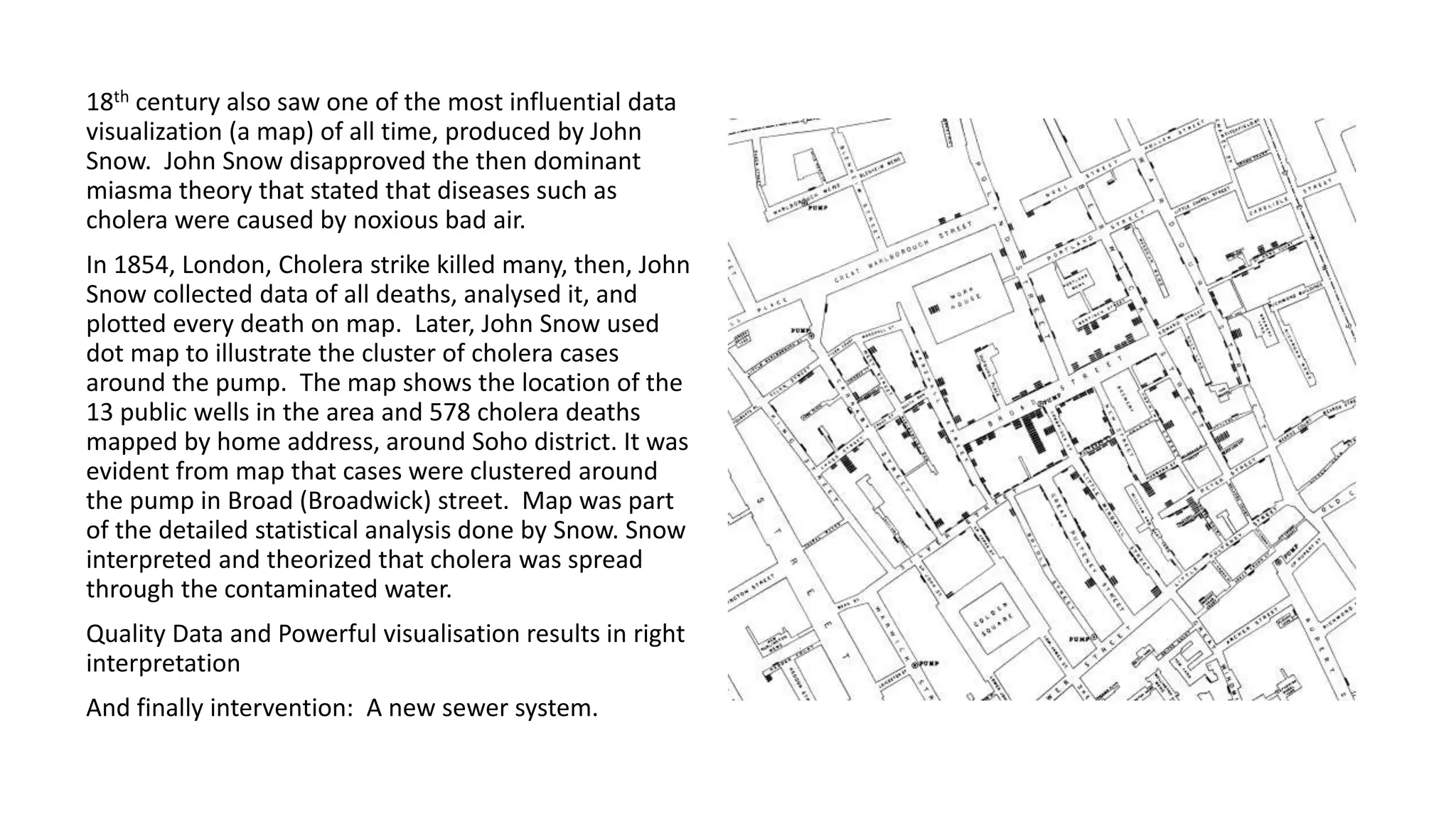


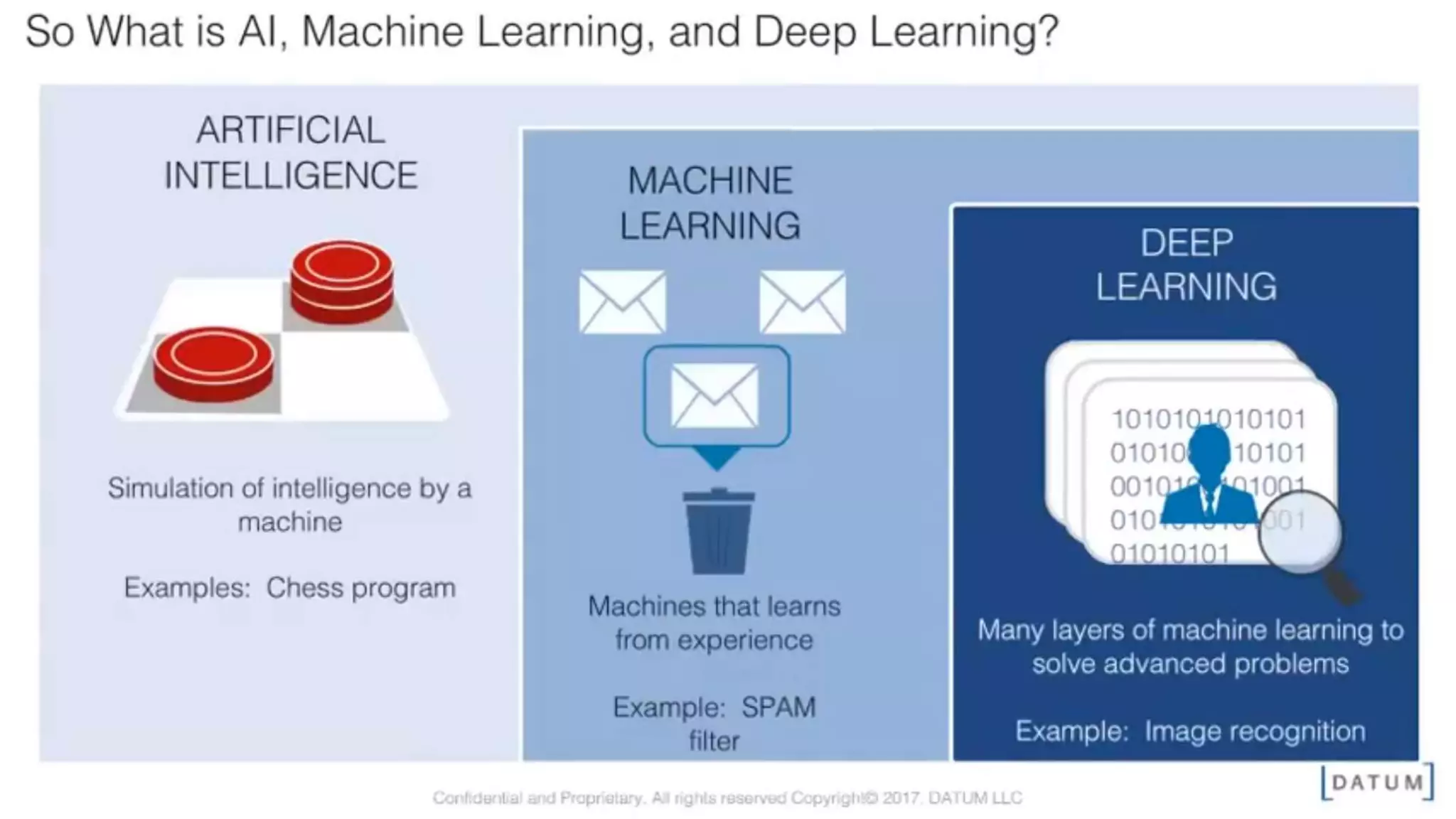
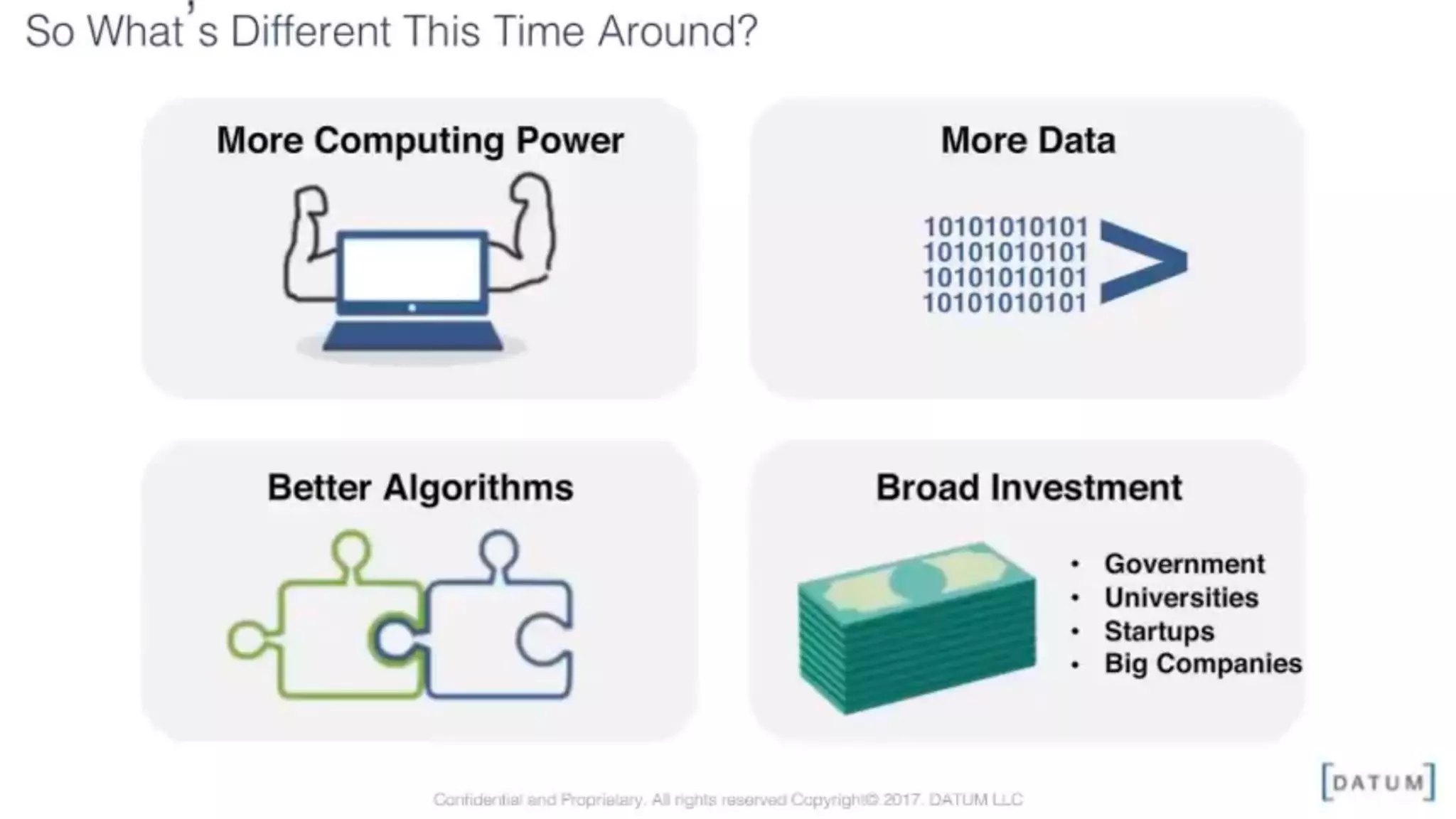



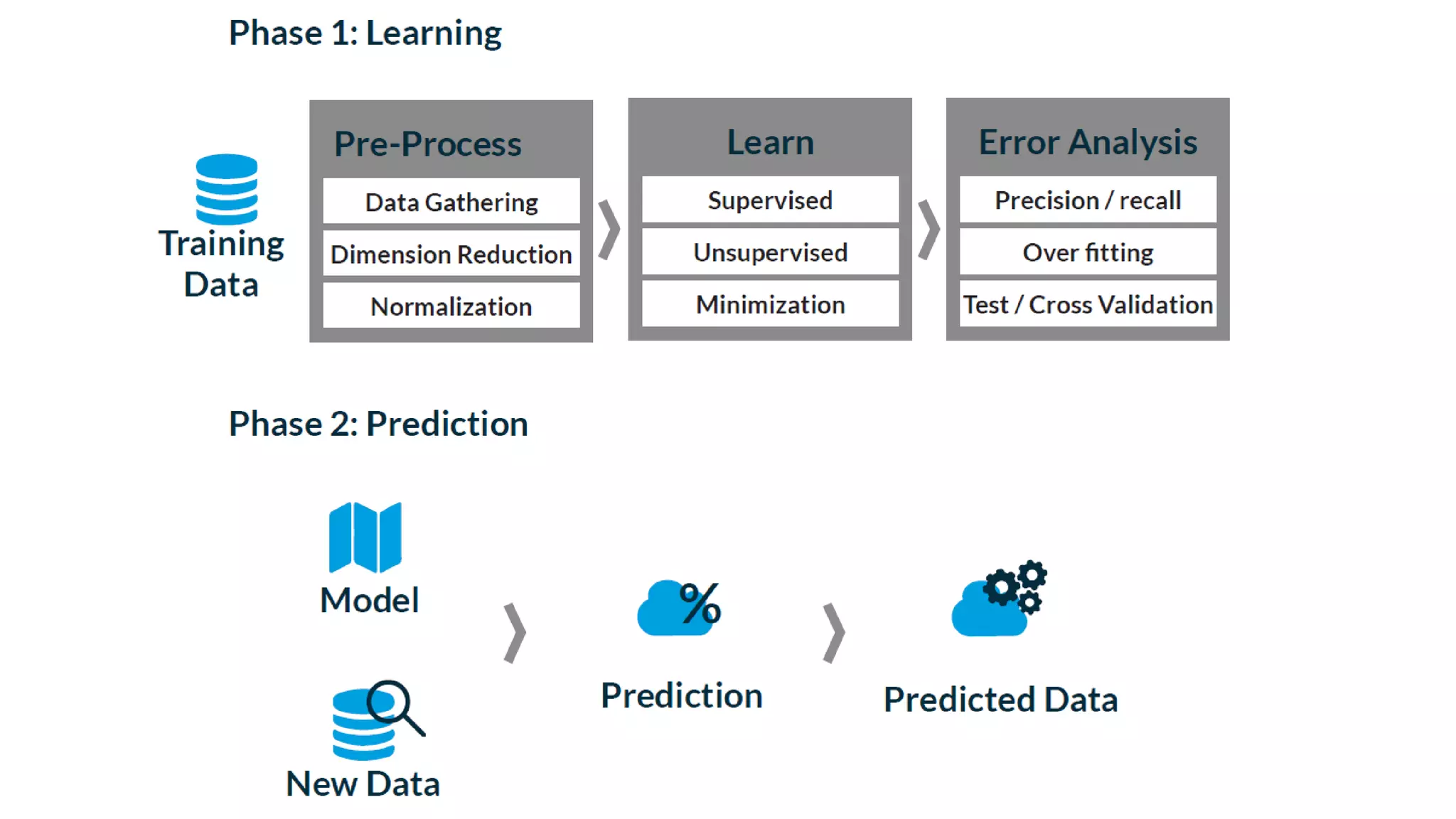







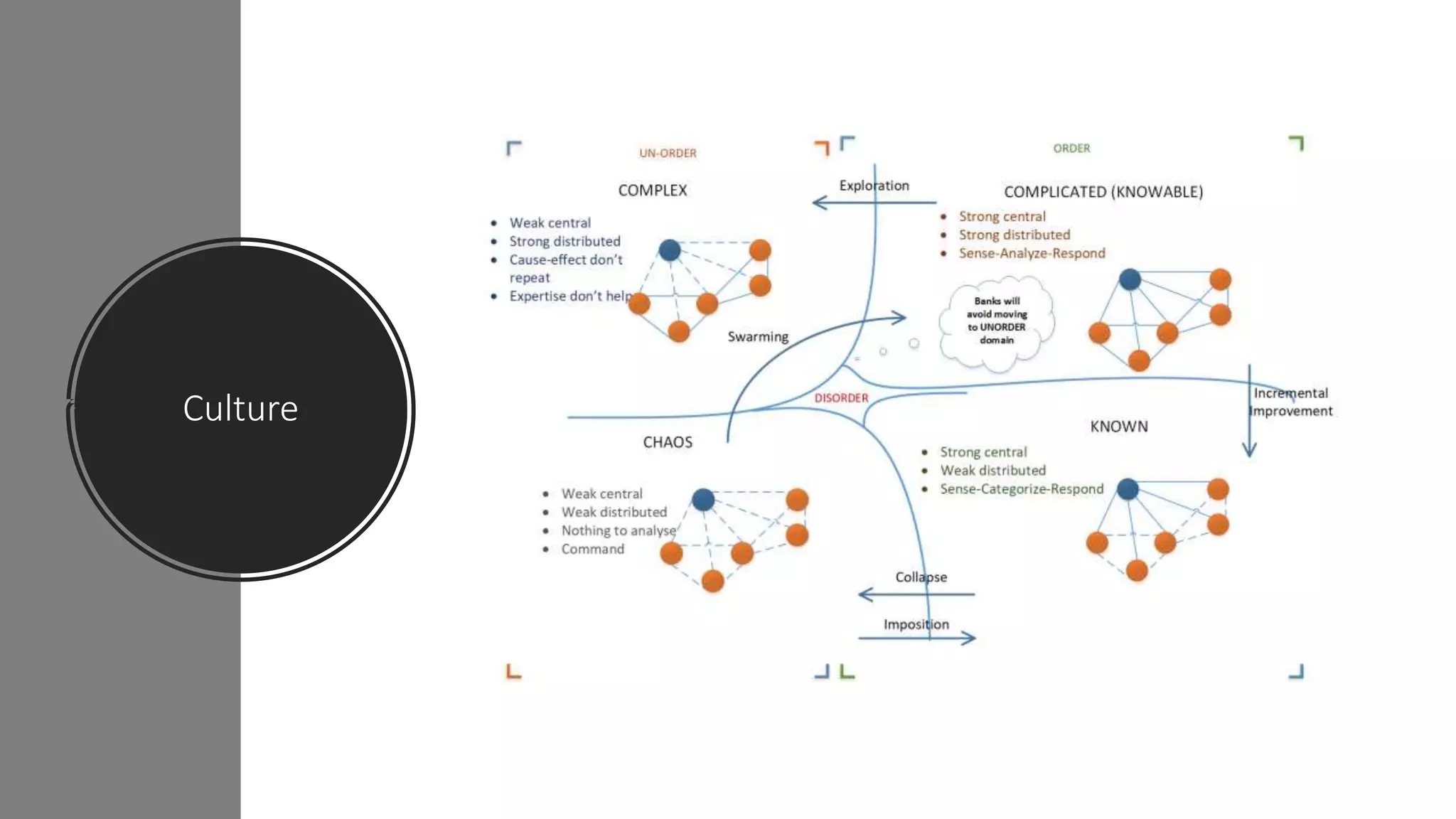




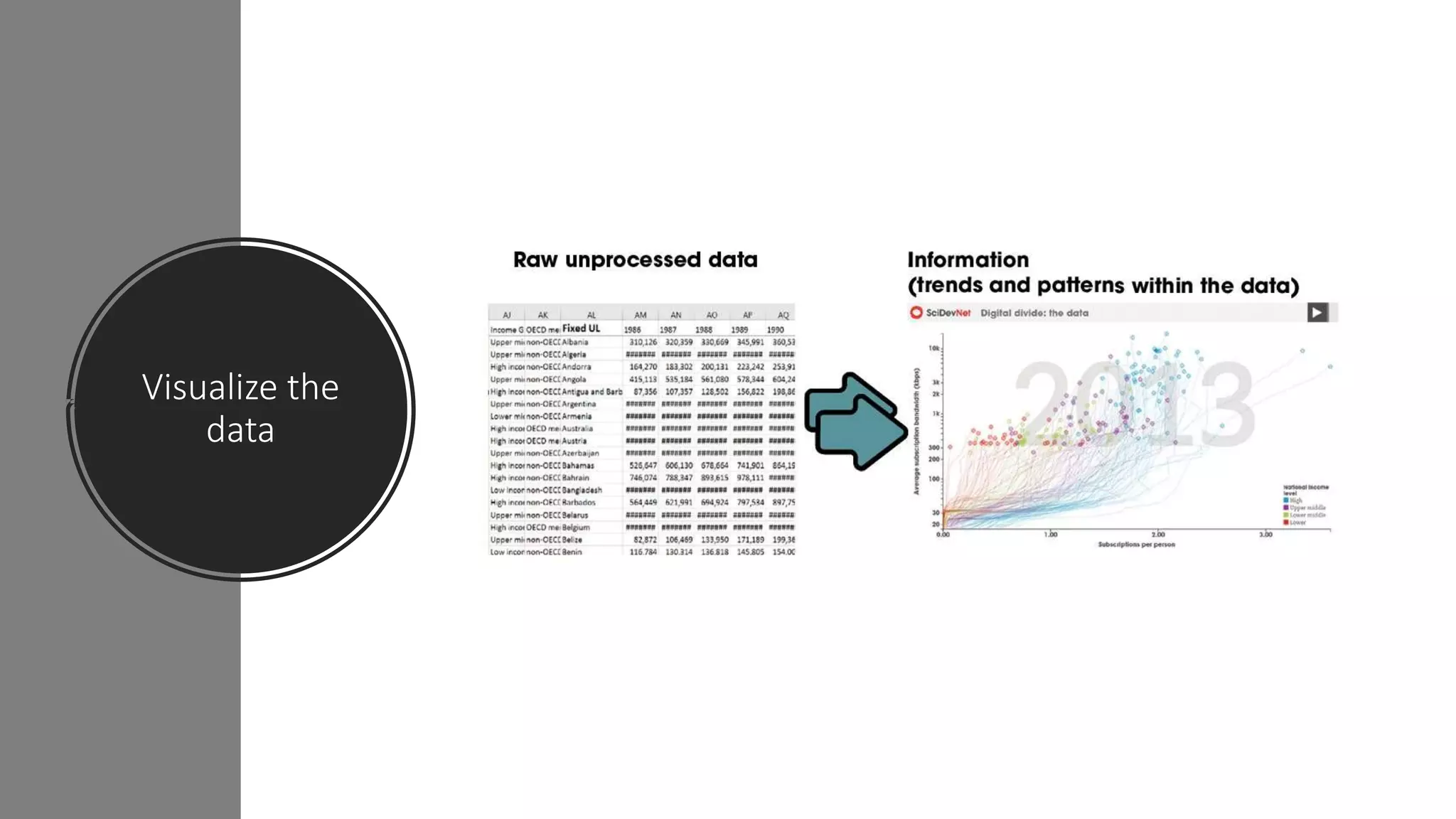
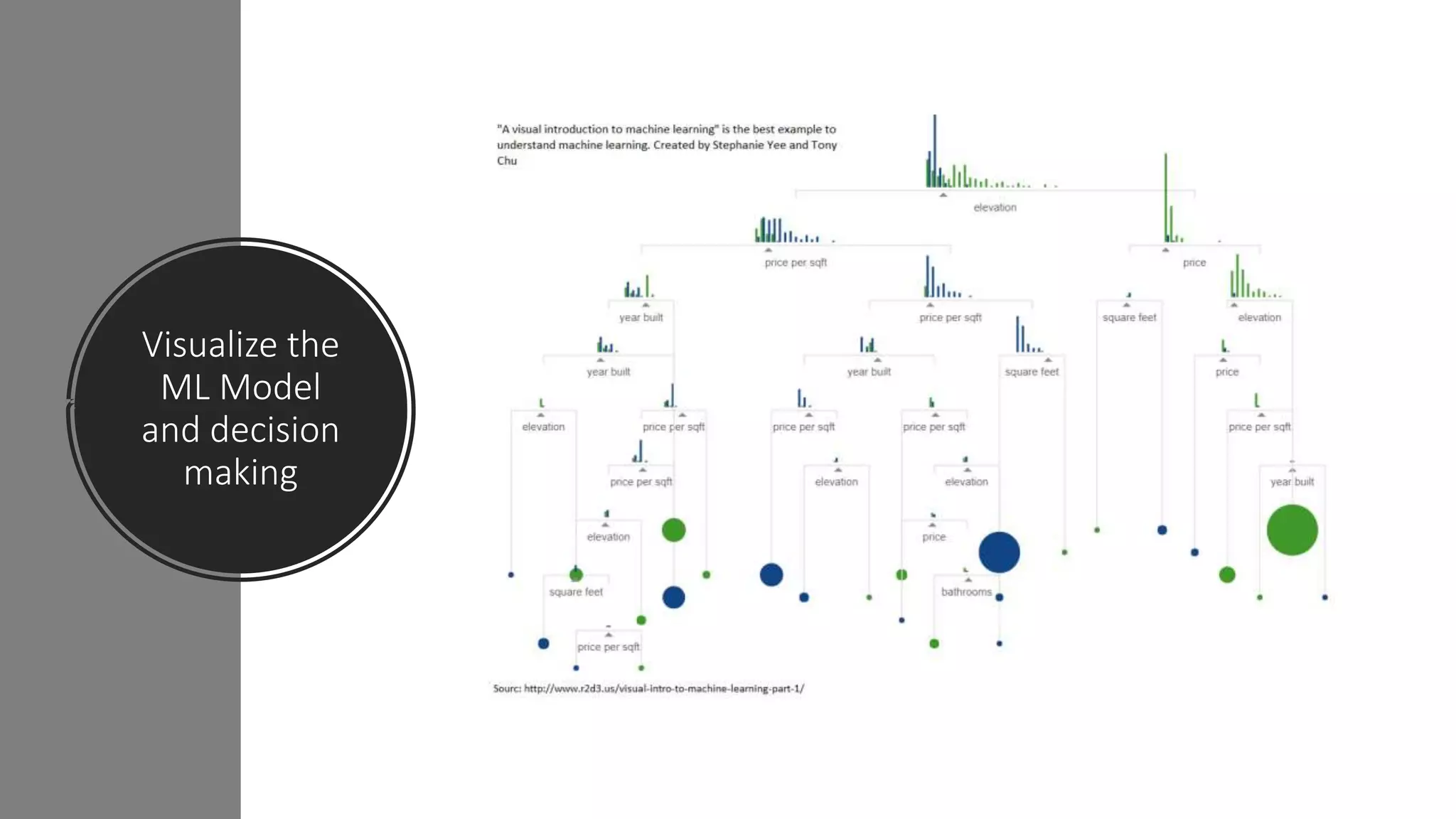







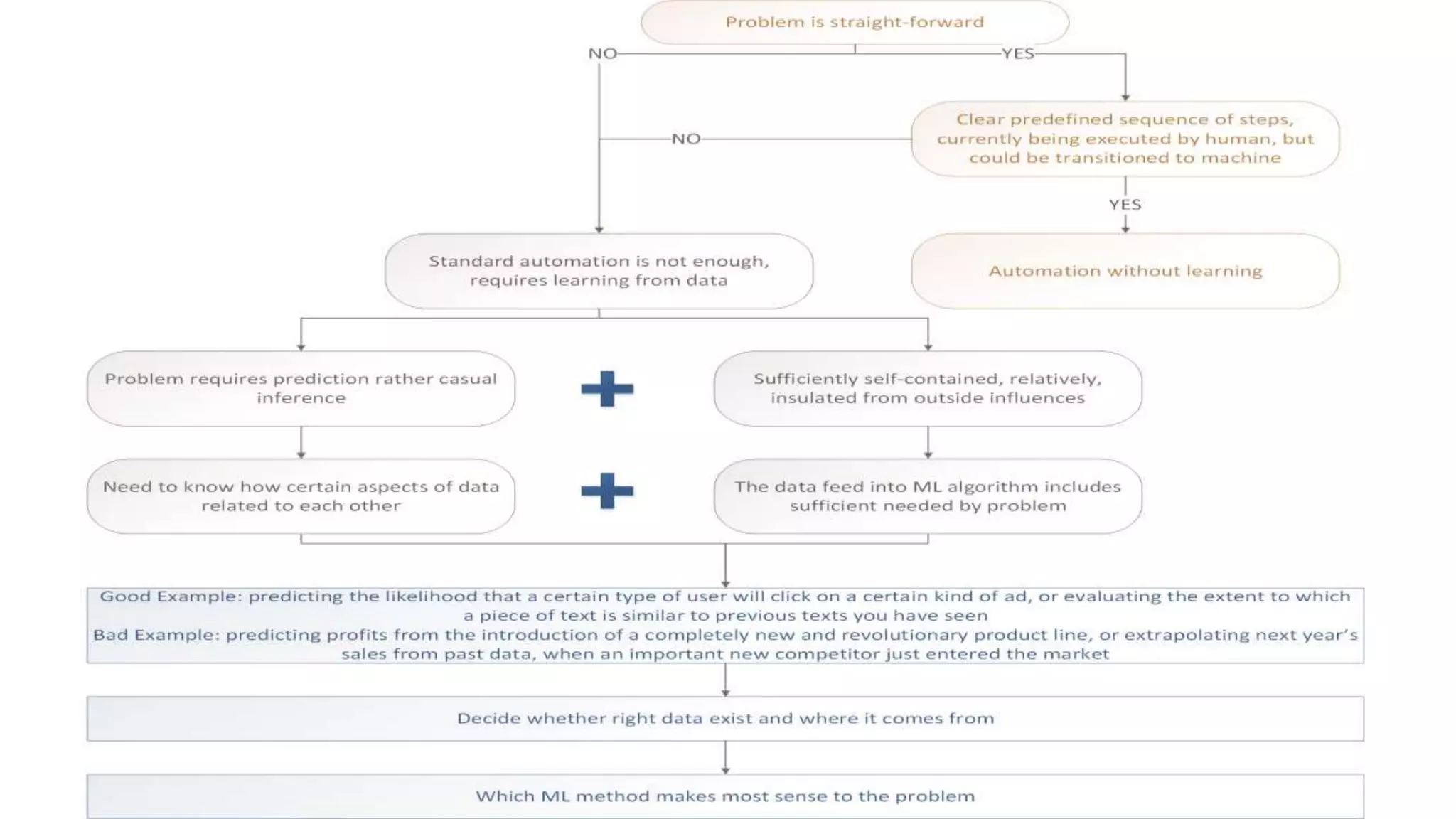




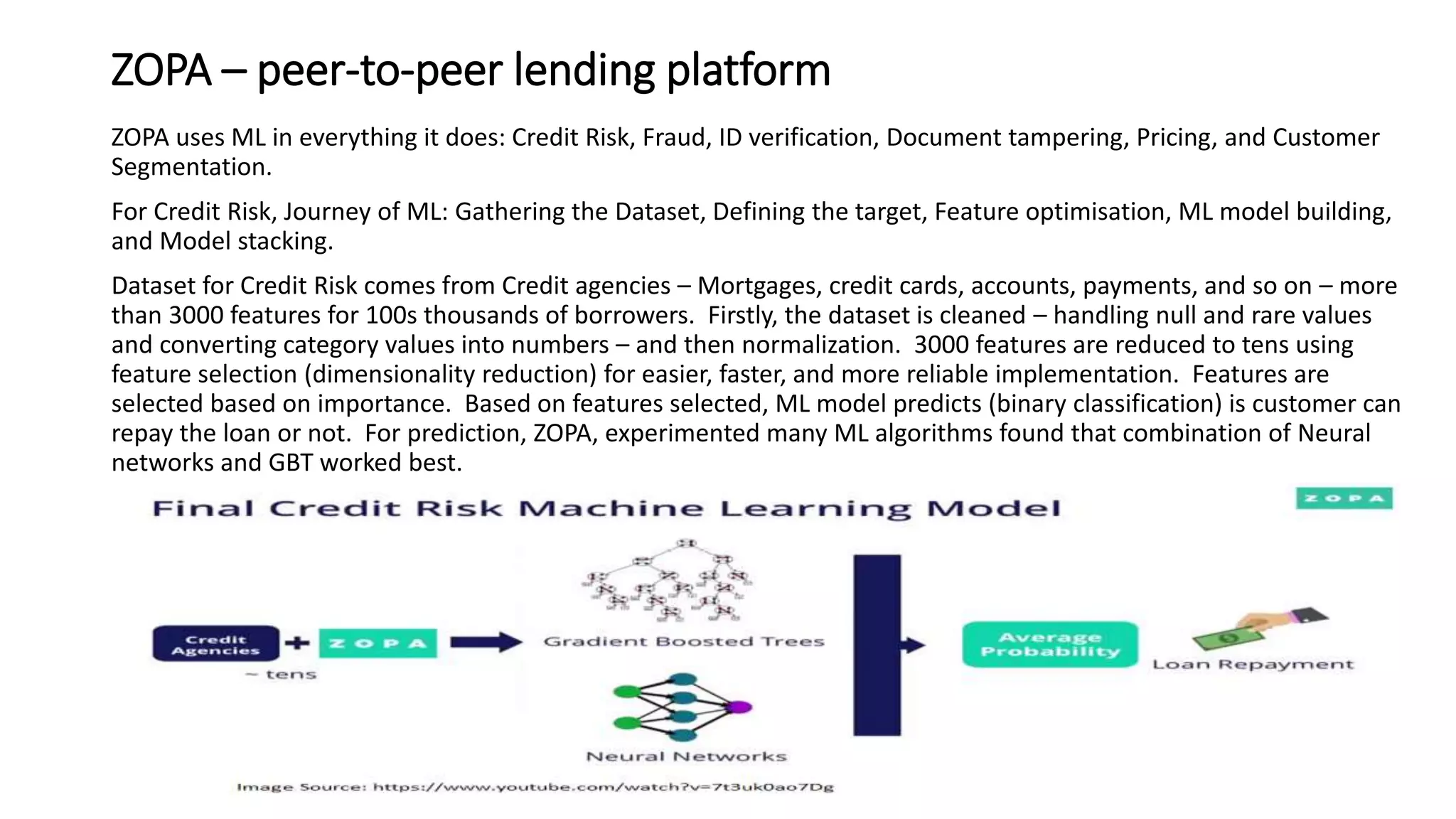


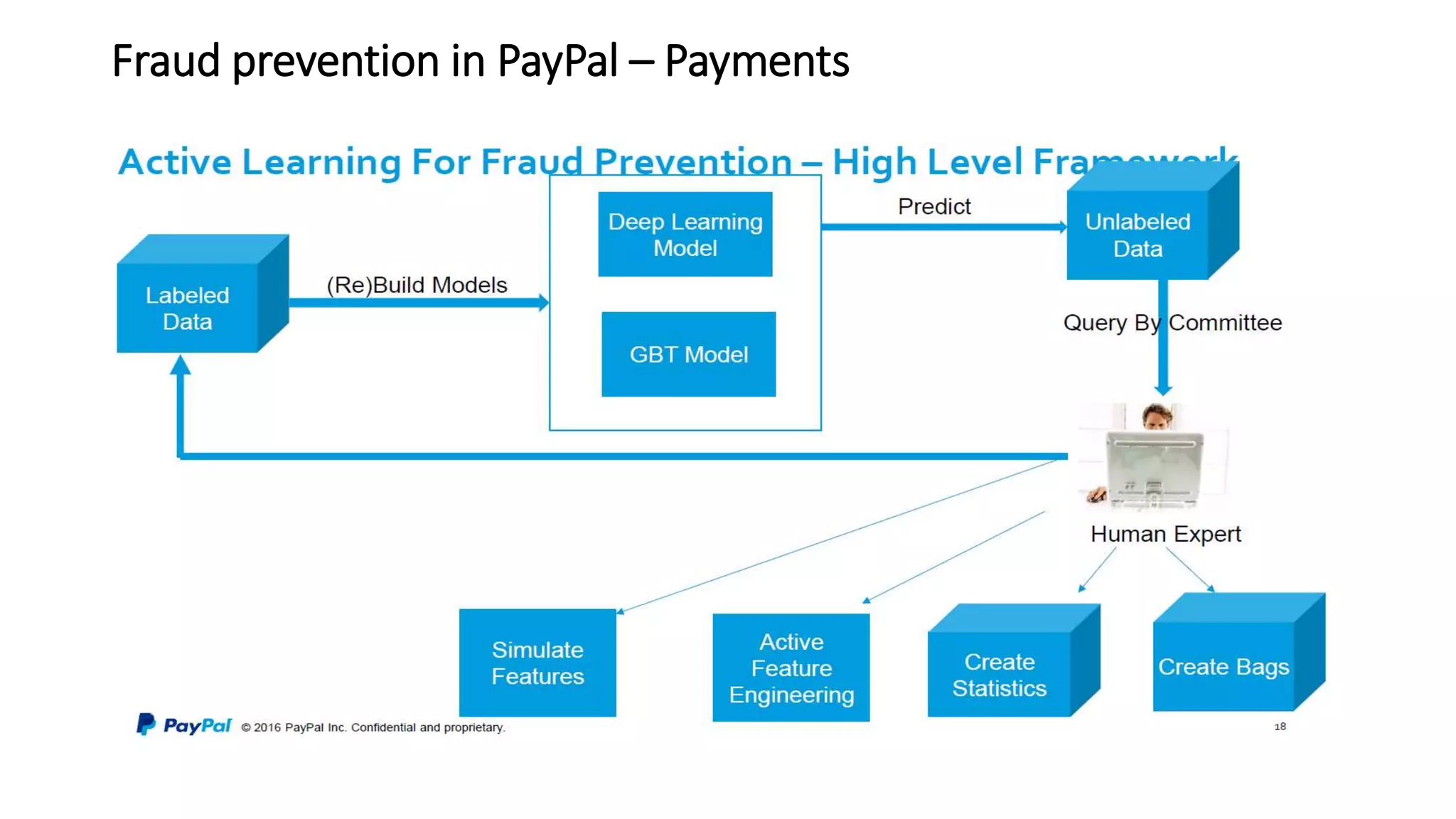

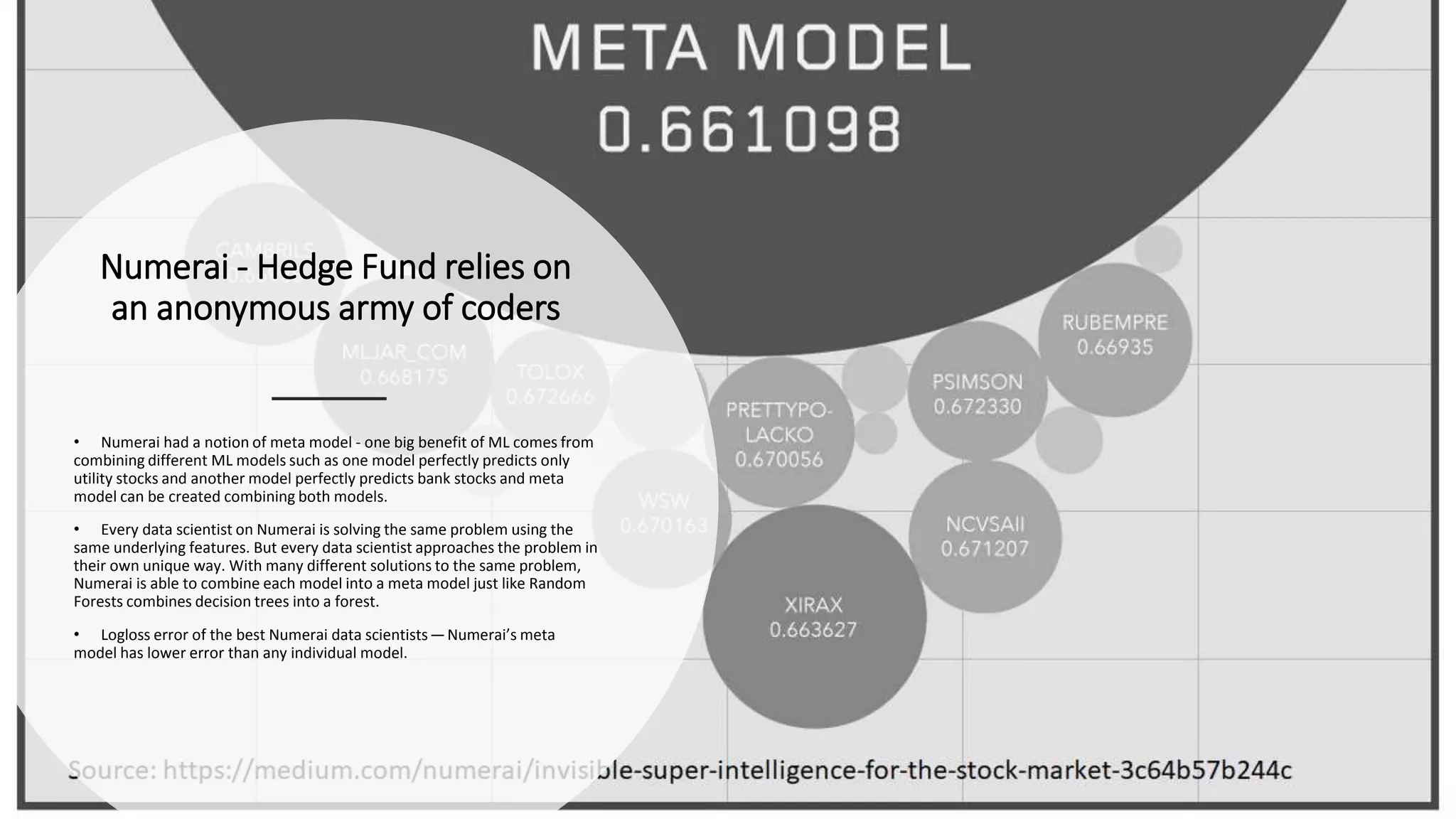


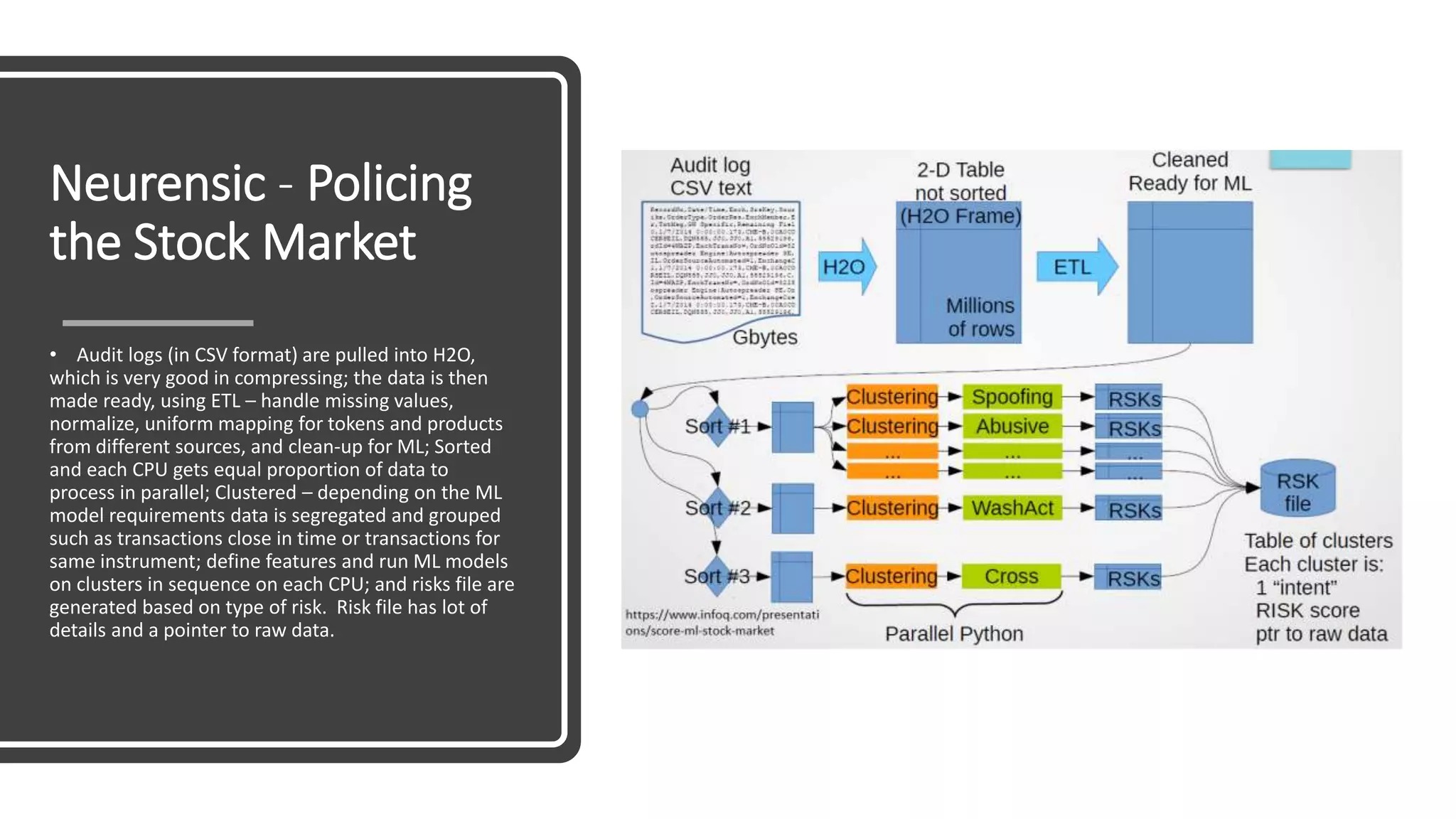

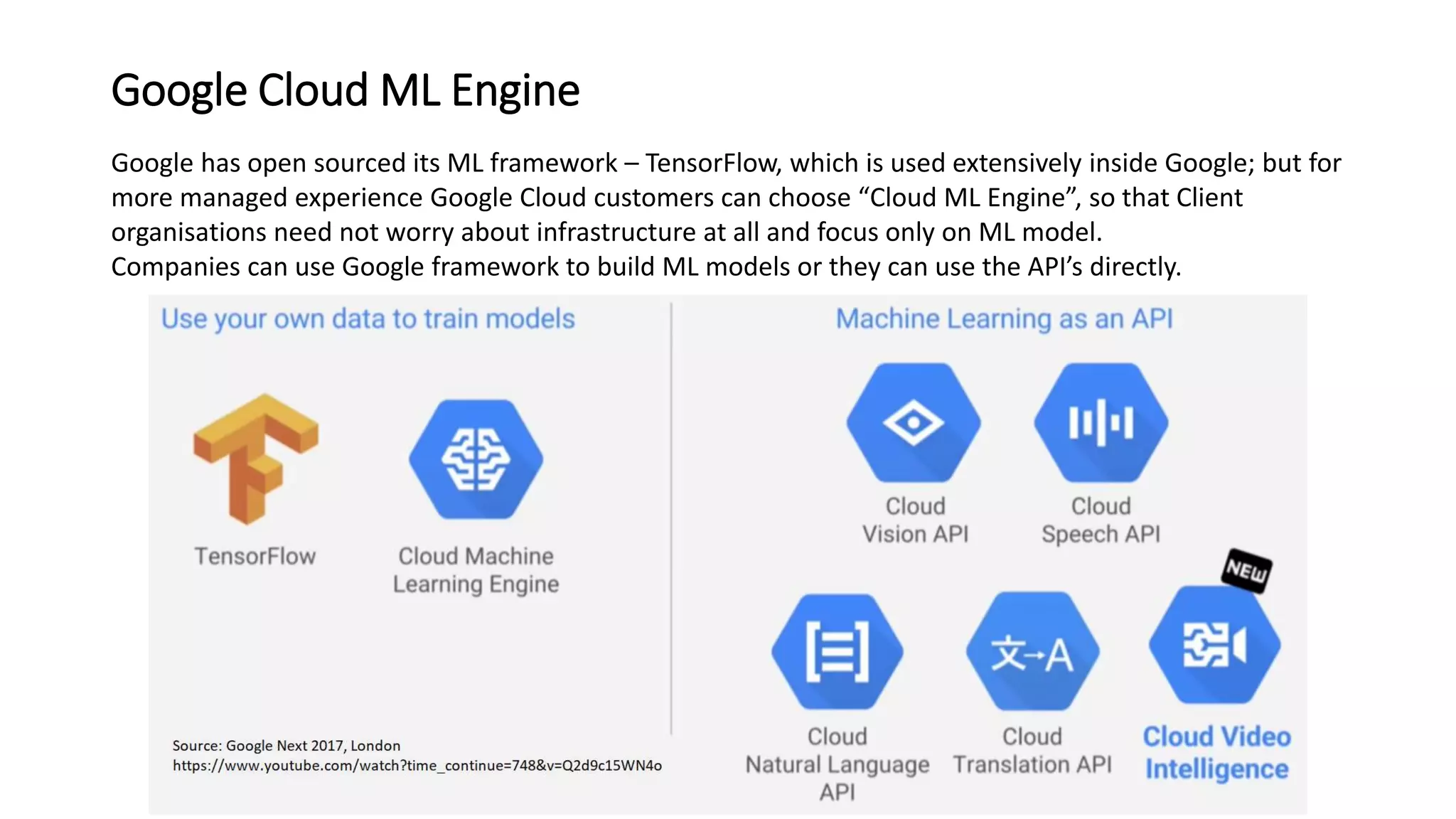
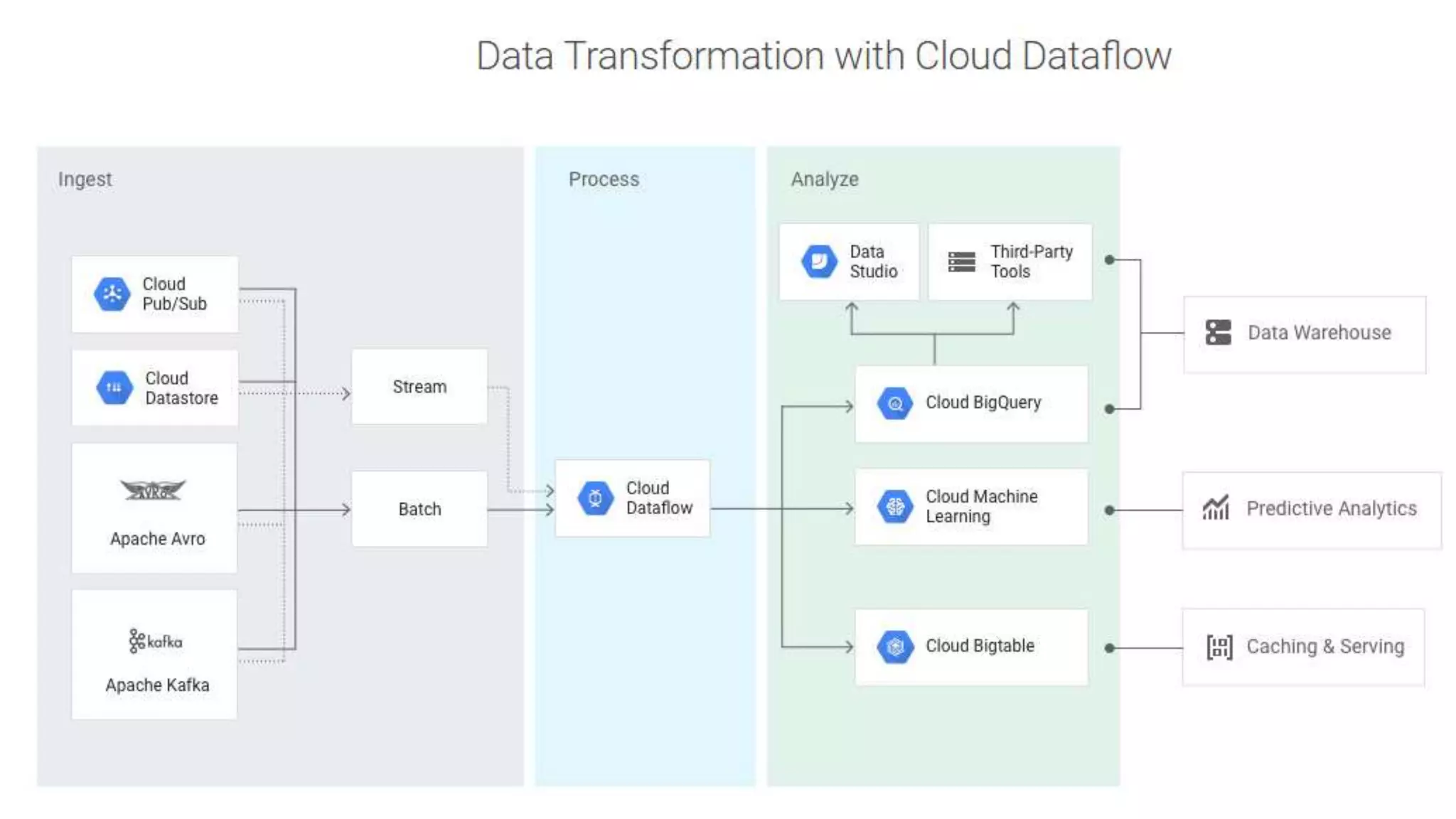




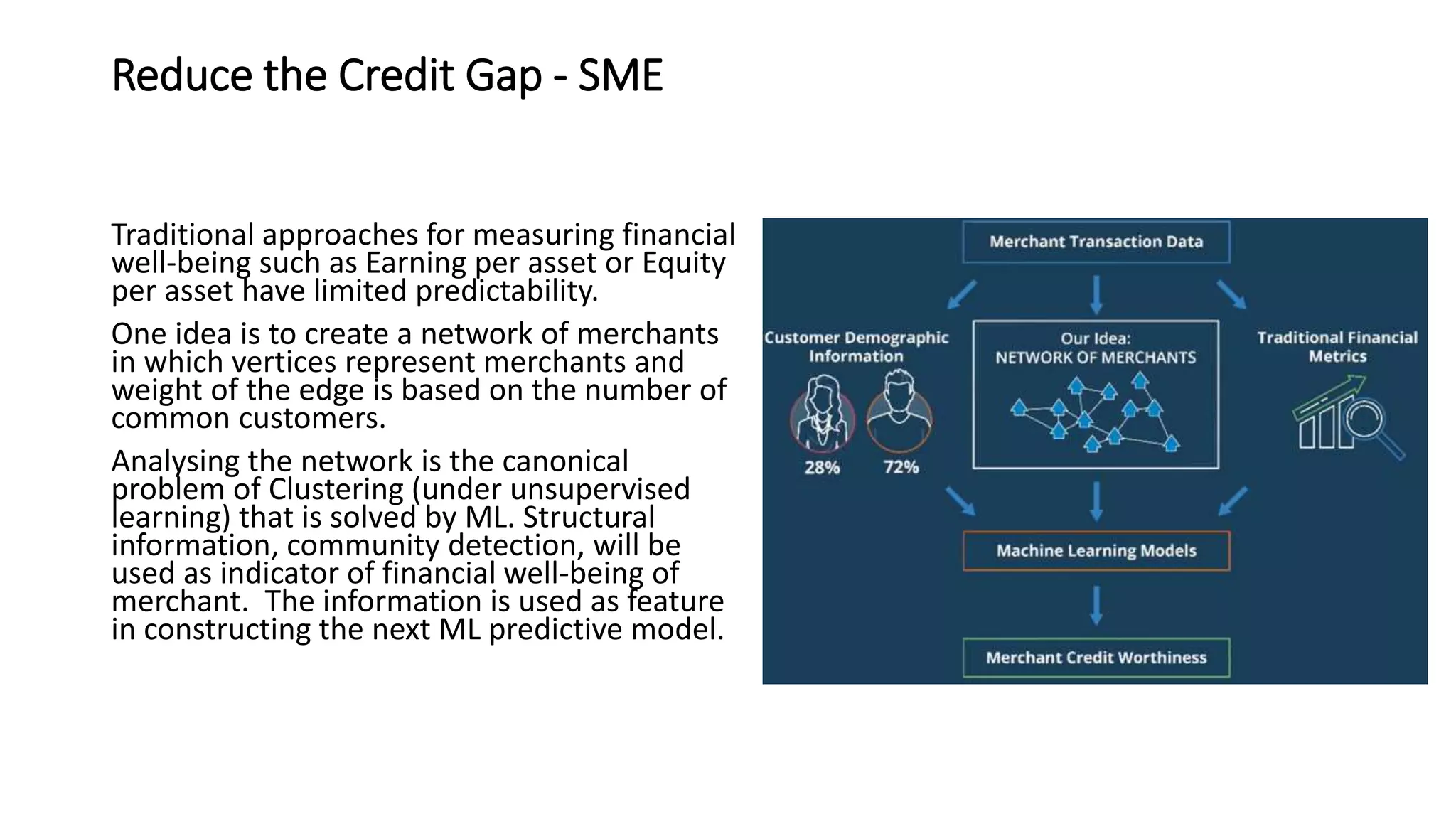







The document discusses the application and challenges of machine learning (ML) in the banking sector, emphasizing its ability to process data, automate analyses, and uncover insights without human bias. It outlines various ML techniques, such as supervised and unsupervised learning, while highlighting key challenges in adoption, including data silos and the need for governance. Use cases from several companies, including fraud prevention and credit risk assessment, illustrate the practical benefits of integrating ML into financial operations.
















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











