Download as PDF, PPTX




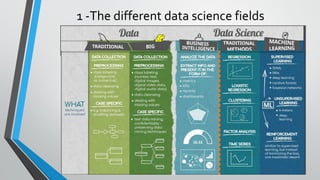


























This document provides an introduction to data science. It discusses the different types of data including traditional structured data, big unstructured data, and semi-structured data. It also summarizes the key differences between analysis and analytics, qualitative and quantitative analytics, business intelligence, machine learning, and traditional data science methods. Common data science tools and job positions are also outlined.



































































