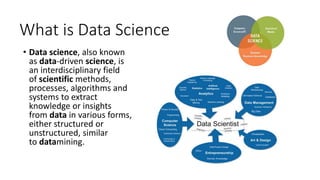
This document discusses data science, machine learning, and R. It defines data science as using methods and algorithms to extract knowledge from structured and unstructured data. It describes the growing need for data scientists due to increasing data volumes and the importance of analytics in many industries. Machine learning is defined as using algorithms to learn from data without relying on predetermined equations, and it can be supervised or unsupervised. Real-world applications of machine learning include finance, computer vision, biology, and more. Common machine learning techniques and when to use machine learning are also outlined. The document concludes with an overview of R, including its data types, objects, operators, and using it for a case study in multiple linear regression.