Downloaded 15 times




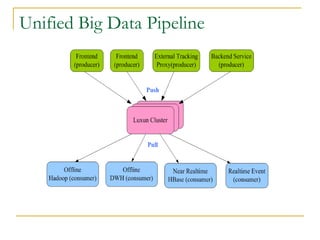


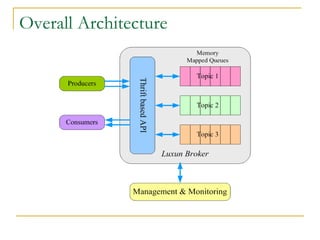

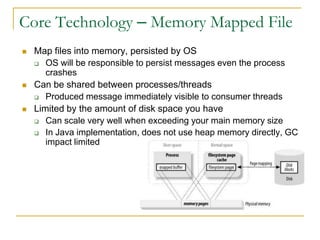

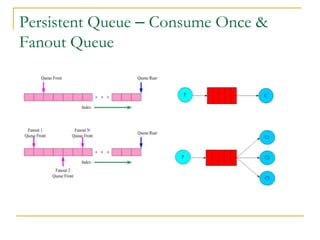


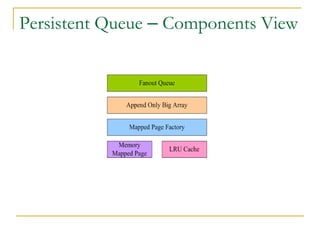
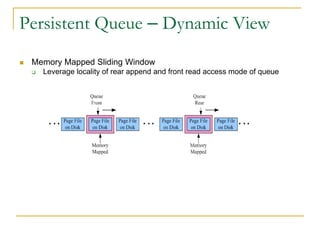

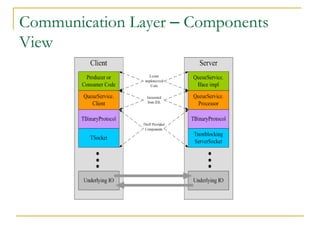


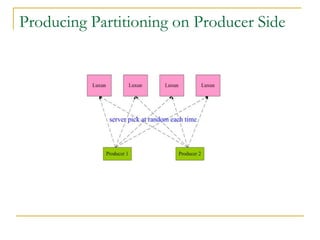
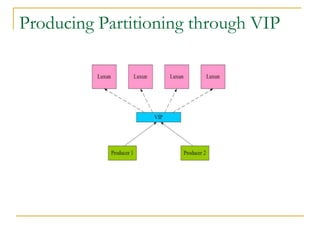

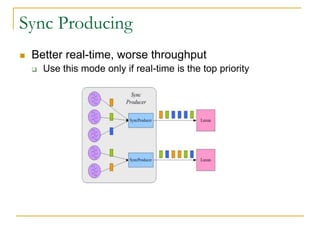
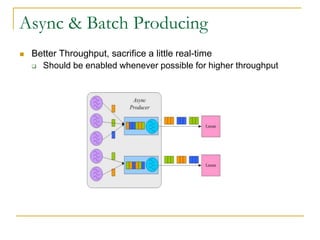


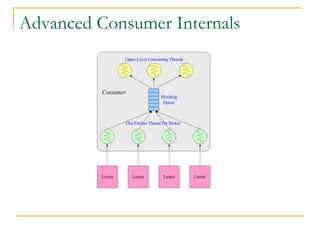
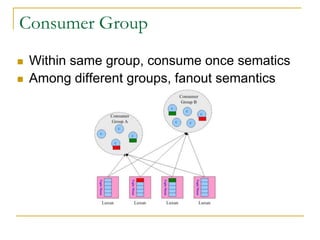






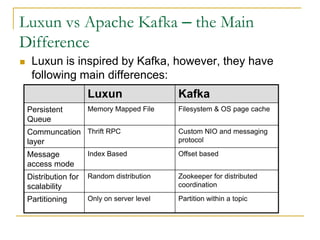





Luxun is a high-performance, persistent messaging system designed for big data collection and analytics, achieving throughput over 200mbps in optimal conditions. It features fast and durable message handling, real-time visibility for consumers, and easy integration across various programming languages. The system is inspired by Apache Kafka but uses a memory-mapped file architecture and a unique communication layer, prioritizing performance and flexibility.







![[B4]deview 2012-hdfs](https://cdn.slidesharecdn.com/ss_thumbnails/b4deview-2012-hdfs-120919013559-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















































![[B5]memcached scalability-bag lru-deview-100](https://cdn.slidesharecdn.com/ss_thumbnails/b5memcached-scalability-baglru-deview-100-120919013502-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























