Downloaded 267 times









![Implementa7on
• L2
LR
_weightOfFeatures[fea] += step * (feaValue * error - reguParam * _weightOfFeatures[fea]);
• L1
LR
if (_weightOfFeatures[fea] > 0)
{
_weightOfFeatures[fea] += step * (feaValue * error) - step * reguParam;
if (_weightOfFeatures[fea] < 0)
_weightOfFeatures[fea] = 0;
}else if (_weightOfFeatures[fea] < 0)
{
_weightOfFeatures[fea] += step * (feaValue * error) + step * reguParam;
if (_weightOfFeatures[fea] > 0)
_weightOfFeatures[fea] = 0;
}else{
_weightOfFeatures[fea] += step * (feaValue * error);
}](https://image.slidesharecdn.com/talk-logisticregression-pptx-120607043844-phpapp01/75/Logistic-Regression-15-2048.jpg)






![Recommended
resources
• Machine
Learning
open
class
–
by
Andrew
Ng
– //10.20.0.130/TempShare/Machine-‐Learning
Open
Class
• h>p://www.cnblogs.com/vivounicorn/archive/
2012/02/24/2365328.html
• logis7c
regression
Implementa7on[link]
– //10.20.0.130/TempShare/guodong/Logis7c
regression
Implementa7on/
– Support
binomial
and
mul7nominal
LR
with
L1
and
L2
regulariza7on
• OWL-‐QN
– //10.20.0.130/TempShare/guodong/OWL-‐QN/](https://image.slidesharecdn.com/talk-logisticregression-pptx-120607043844-phpapp01/75/Logistic-Regression-24-2048.jpg)


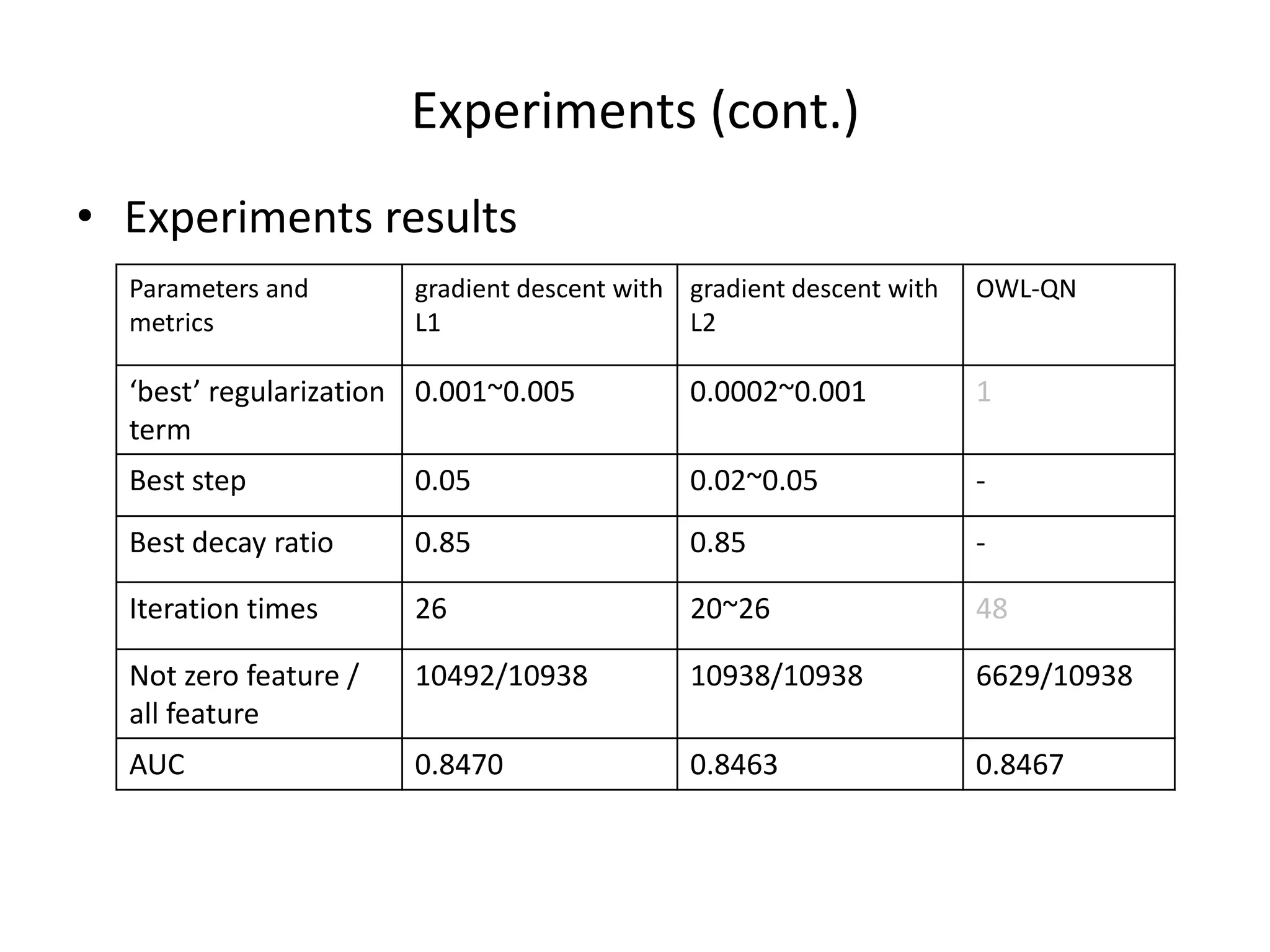
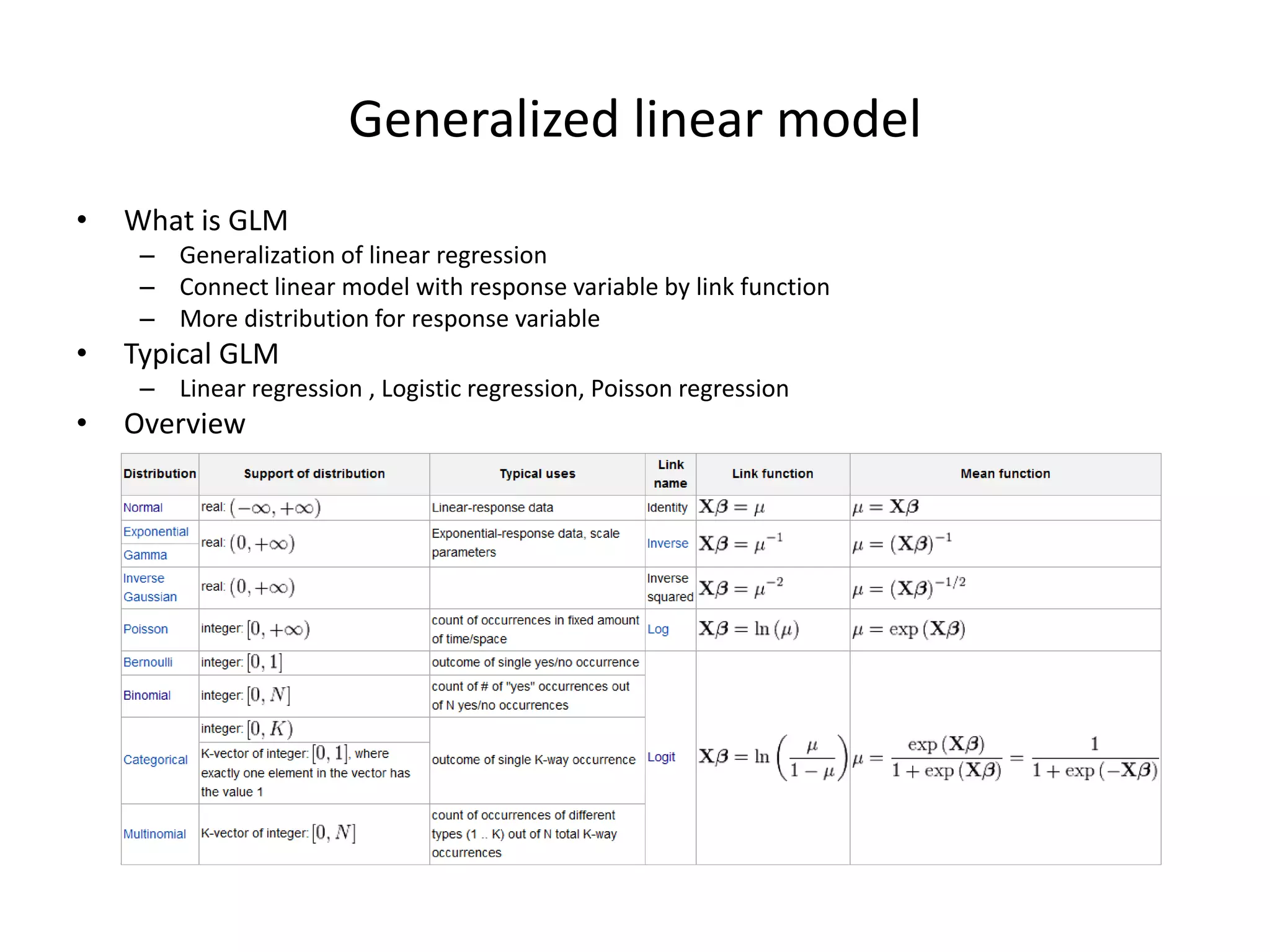
The document outlines a machine learning workshop, focusing on logistic regression, feature selection, and boosting techniques. It discusses different types of learning models, regularization methods, and practical implementations using gradient descent for gender prediction datasets. Various experiments comparing L1 and L2 regularization methods are presented, including outcomes and recommendations for future reference.























































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)








