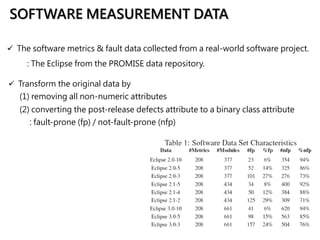
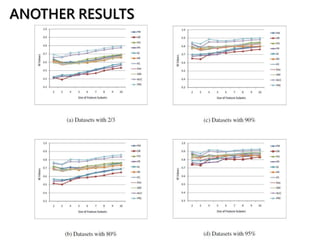
This document discusses feature selection techniques for software fault prediction. It begins by motivating the need for feature selection when building defect prediction models using large sets of software metrics. It then describes common feature selection techniques like filter and wrapper methods. It provides examples of widely used software metrics like CK and McCabe & Halstead metrics. The document also analyzes threshold-based feature selection and evaluates its stability. Finally, it proposes a hybrid feature selection model and demonstrates its effectiveness on a dataset from the Eclipse project.