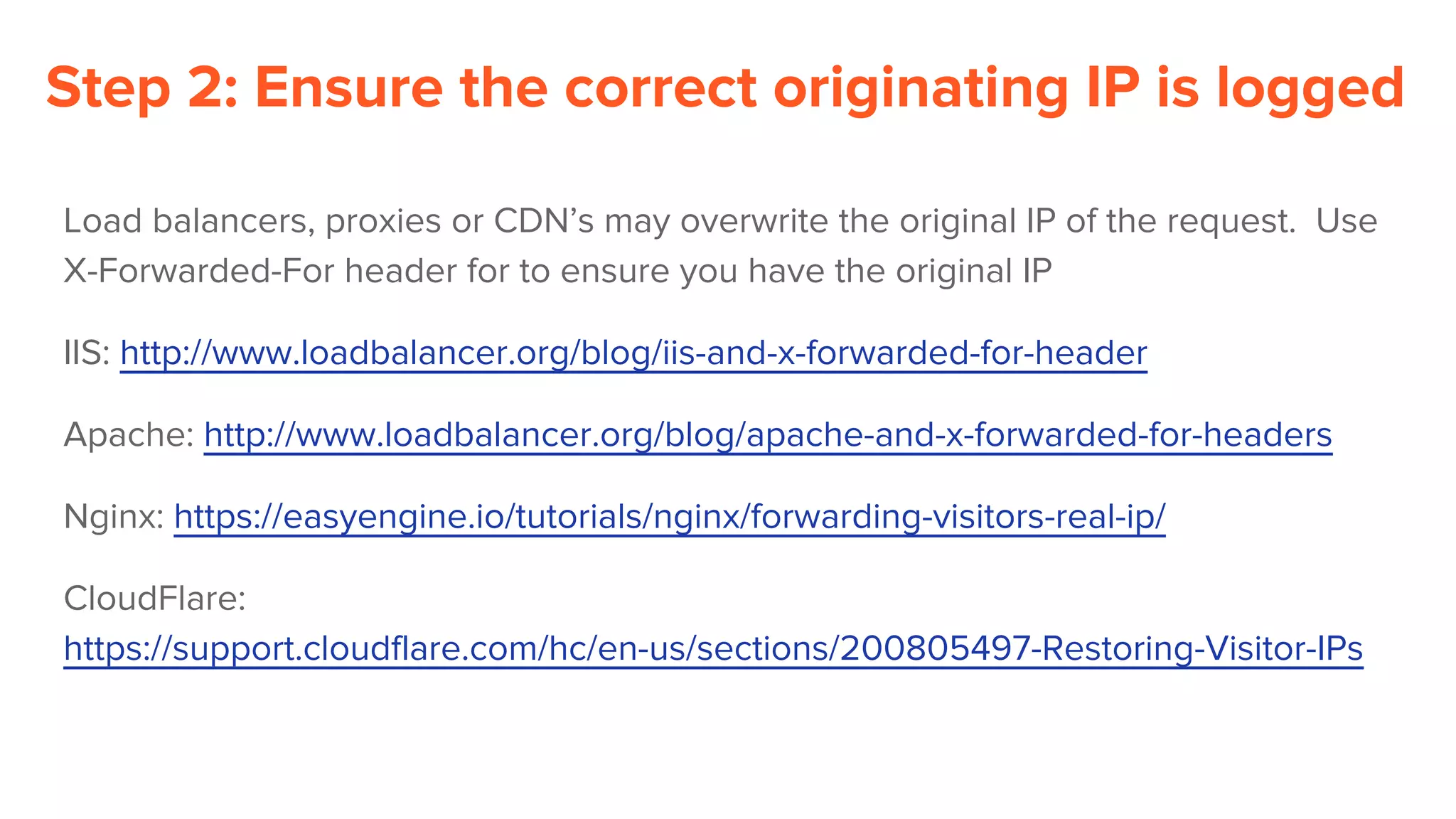
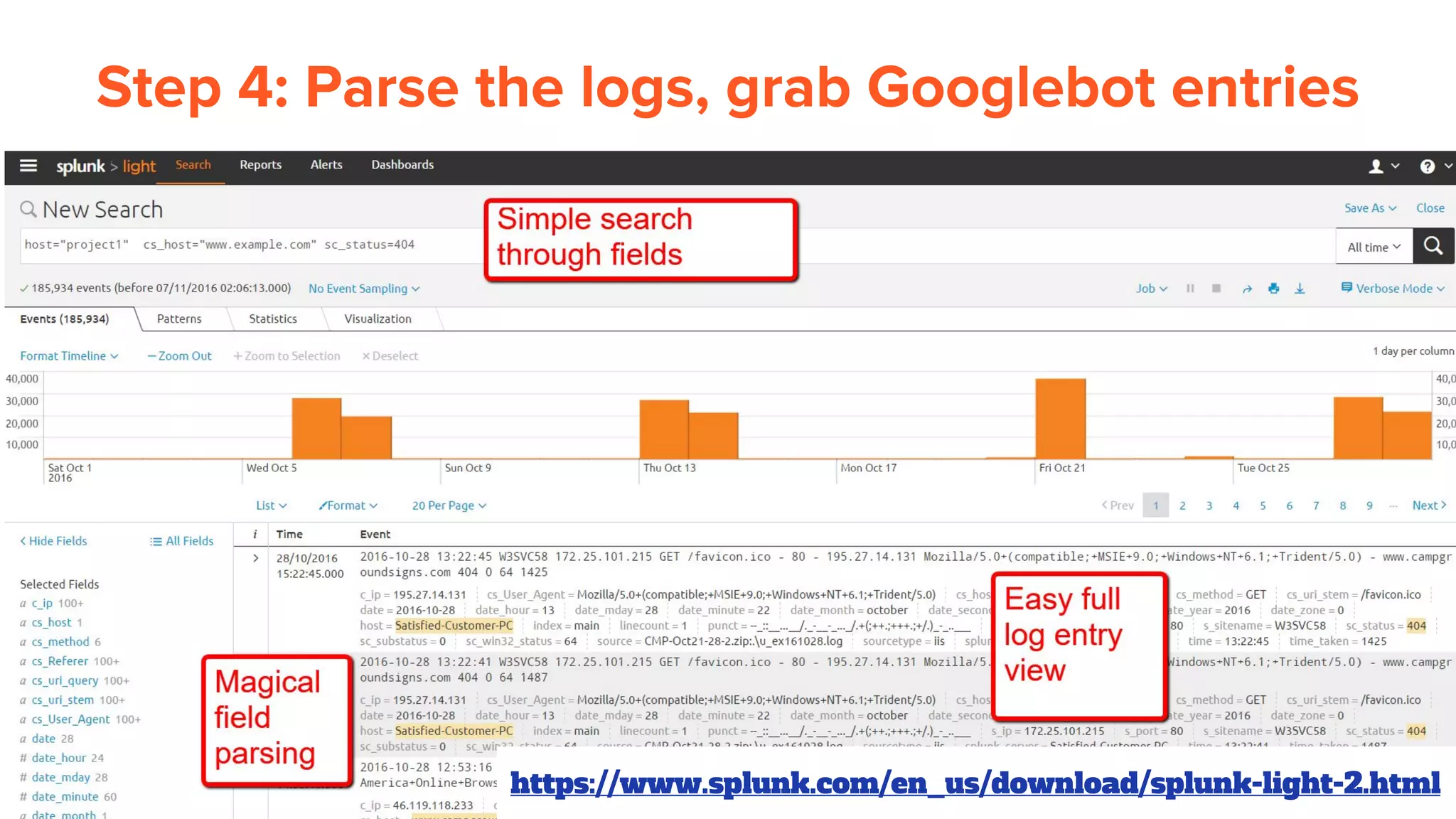
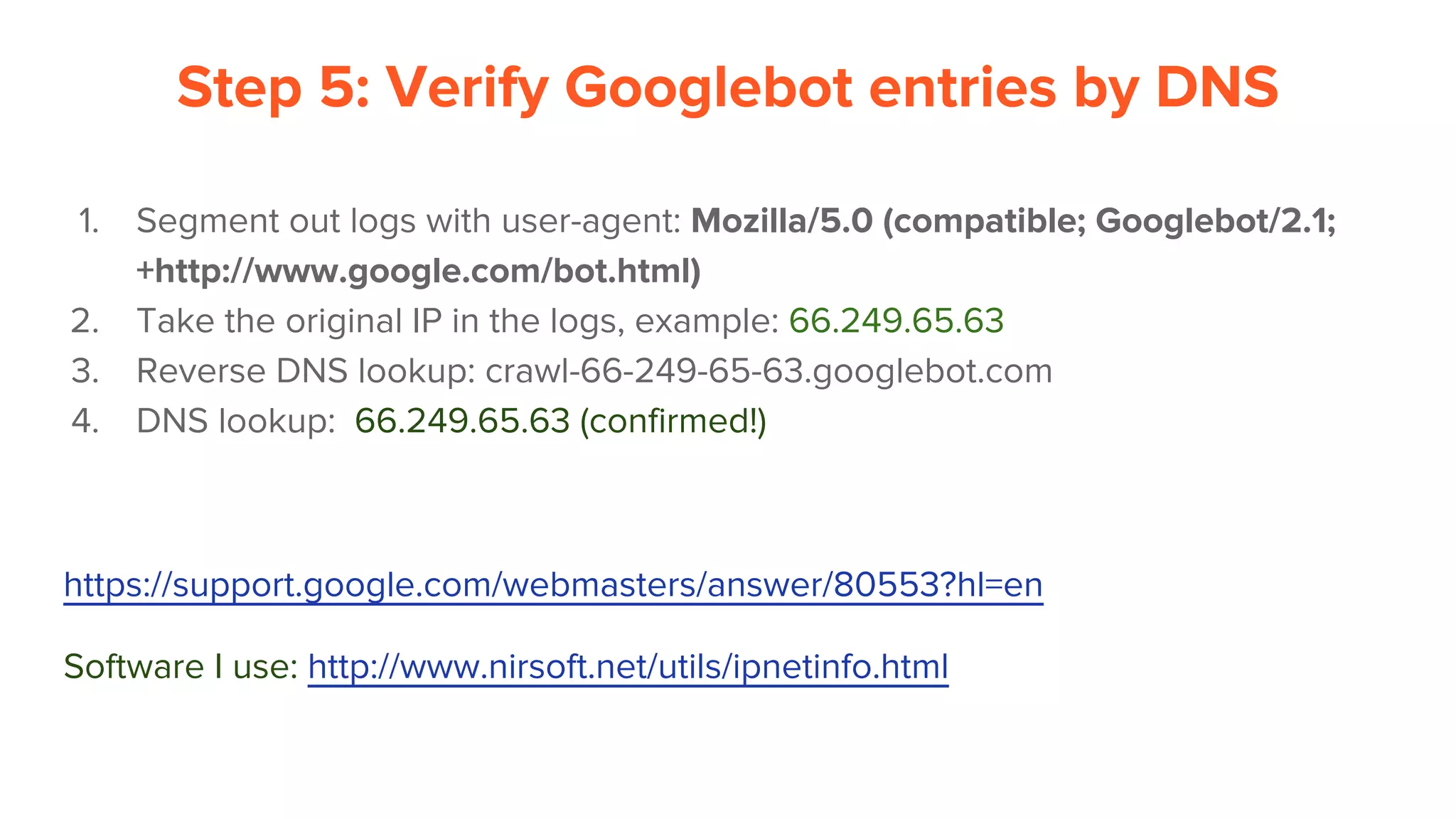
Download as PDF, PPTX








![Step 1: Get the right fields logged
206.248.146.167 - - [25/Aug/2015:06:50:01 +0000] "GET /shoes HTTP/1.0" 200 251
"https://www.google.ca/" “example.com” "Mozilla/5.0 (Windows NT 6.1; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
User agent
IP Address Date/Time
Referer
Method
Response code
Page
Response time
Hostname](https://image.slidesharecdn.com/loganalysisandprousecasesforsearchmarketersonlineversion1-161109004114/75/Log-analysis-and-pro-use-cases-for-search-marketers-online-version-1-13-2048.jpg)








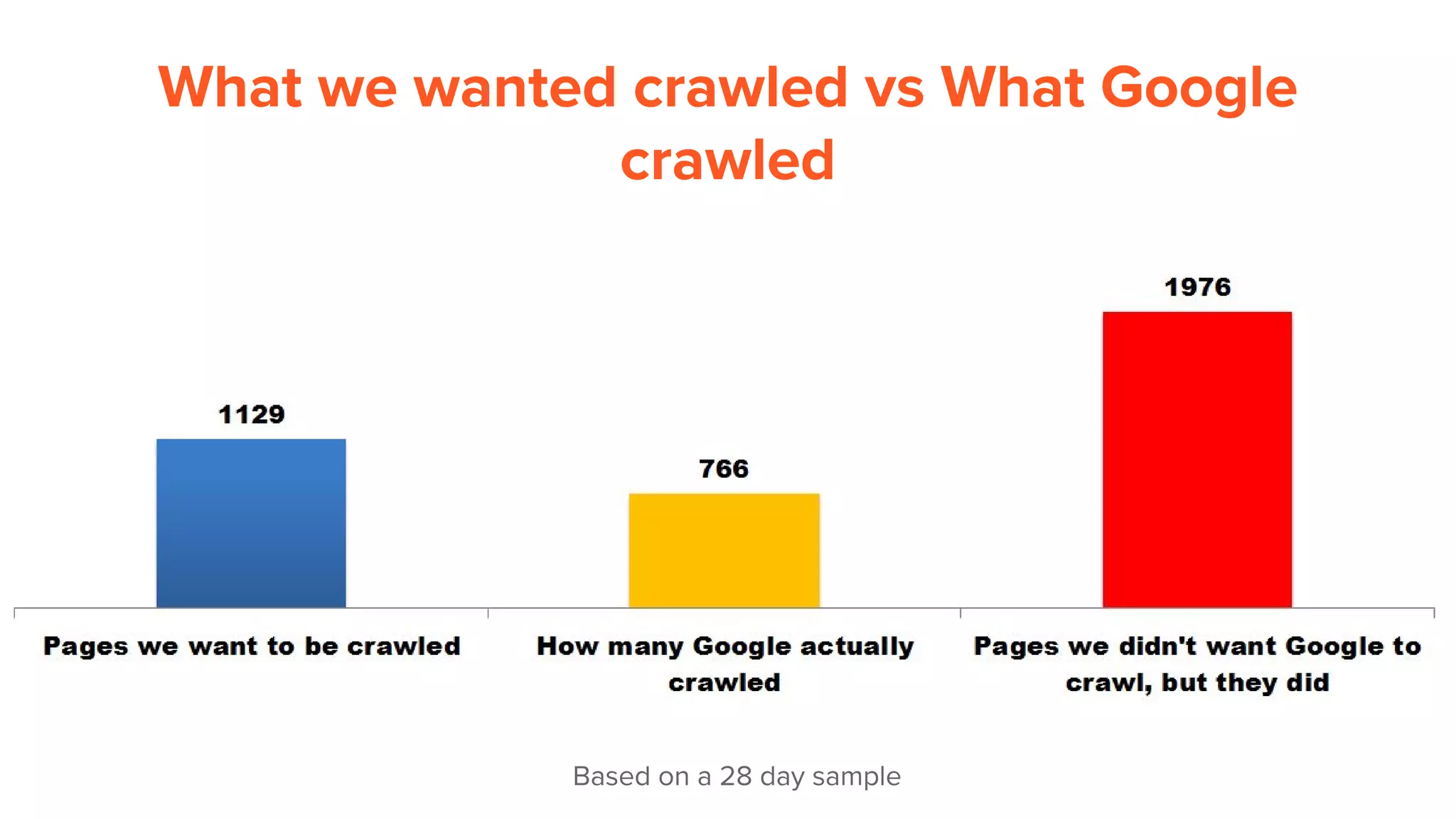
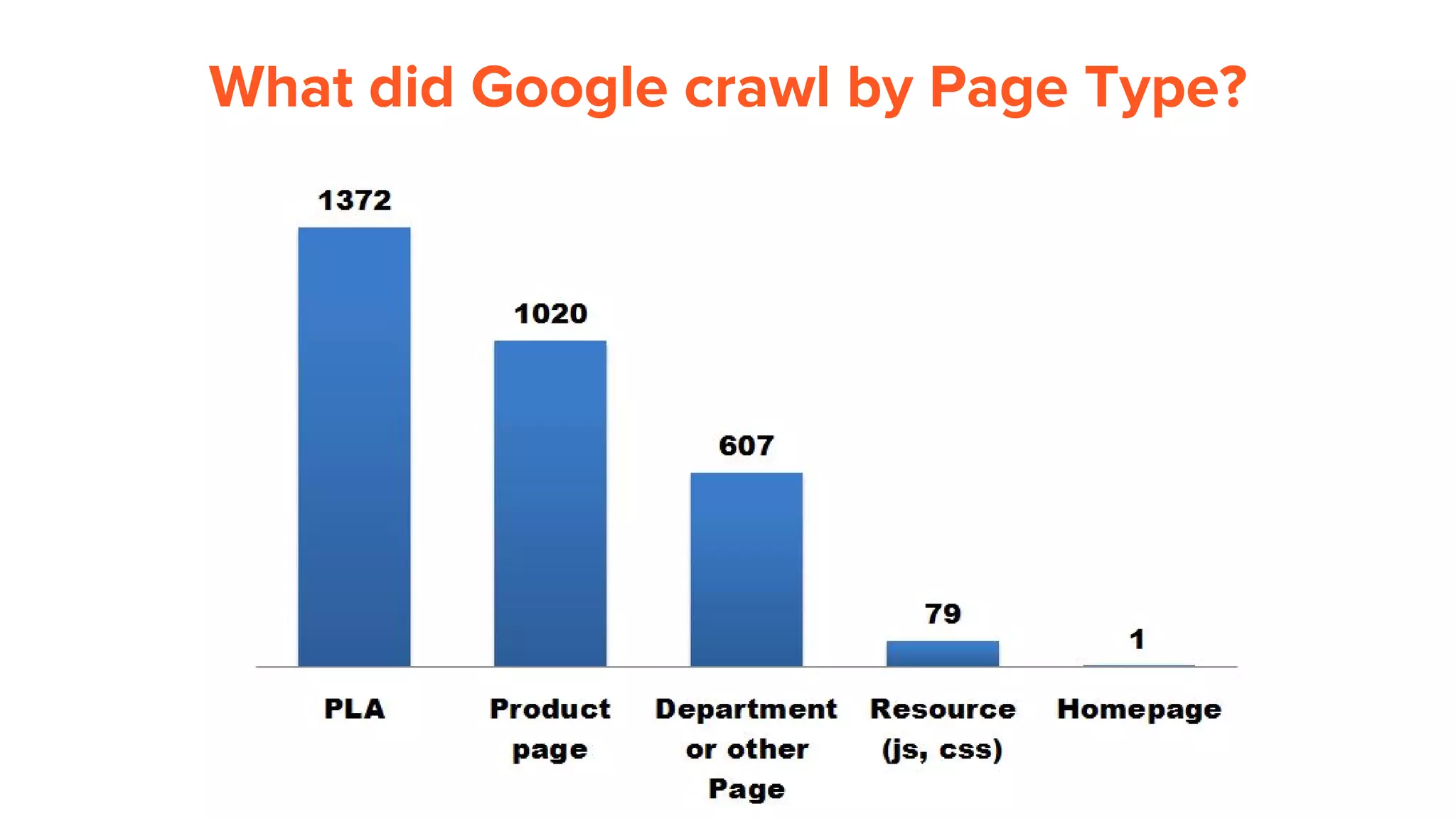


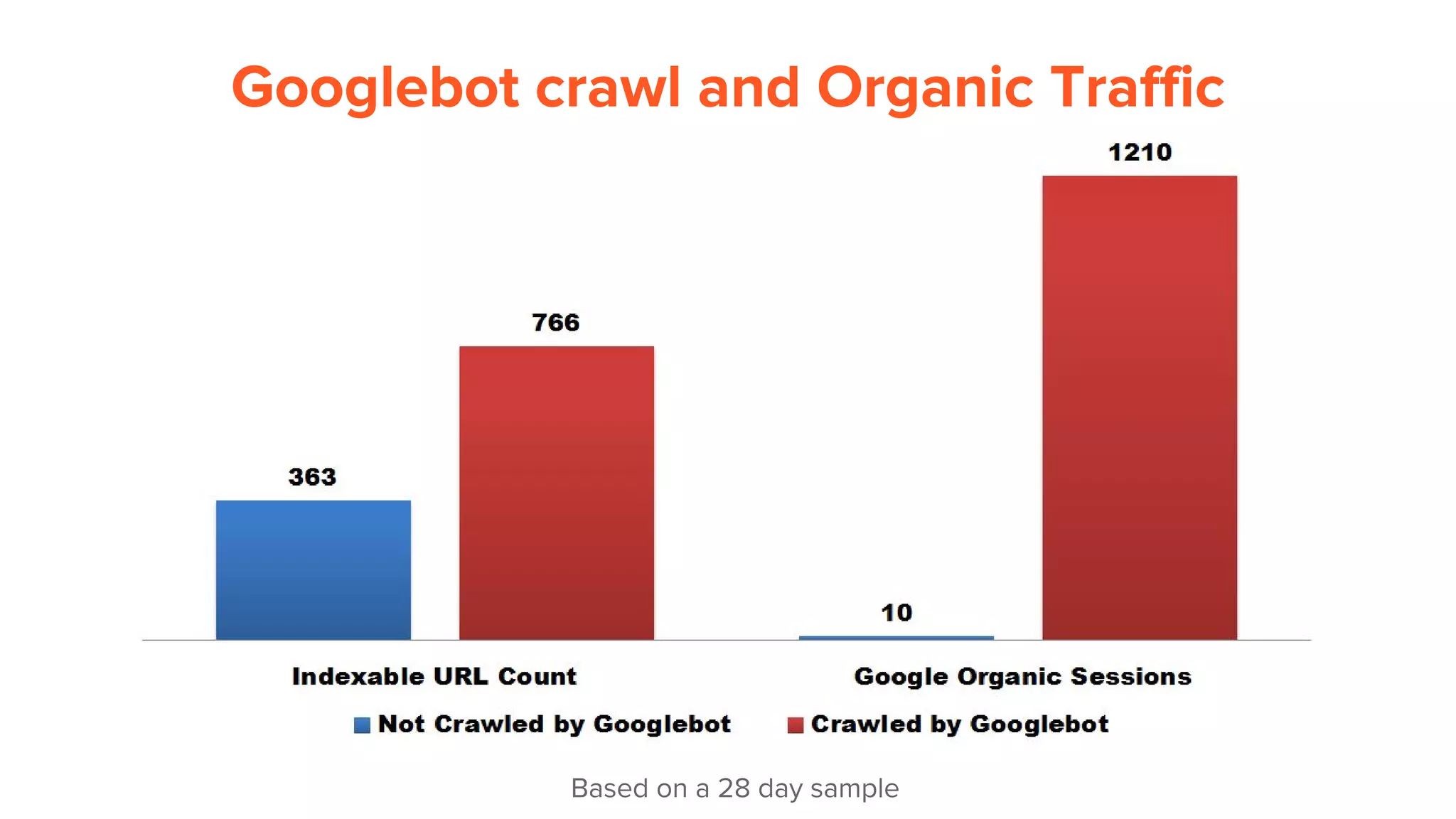

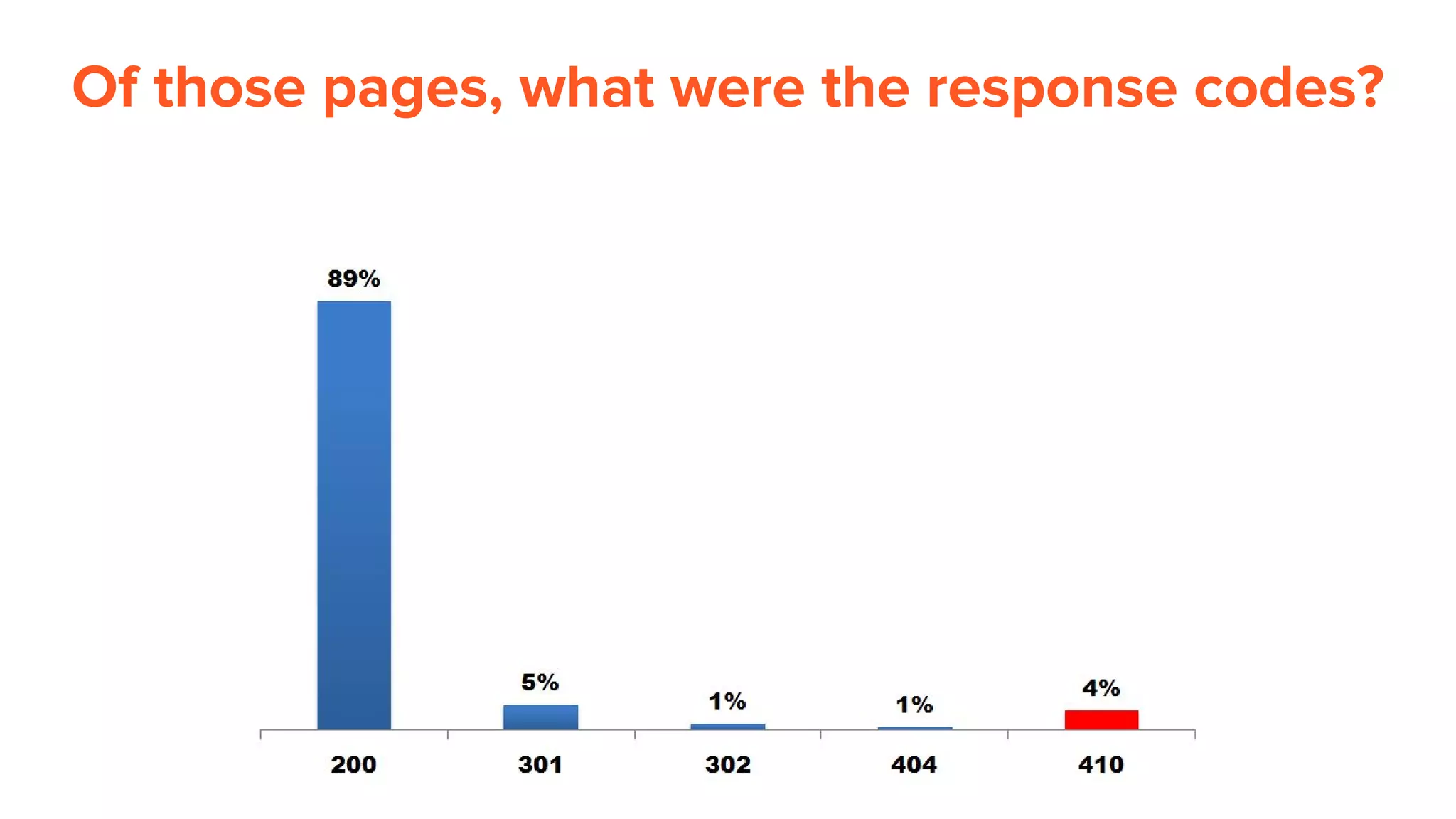
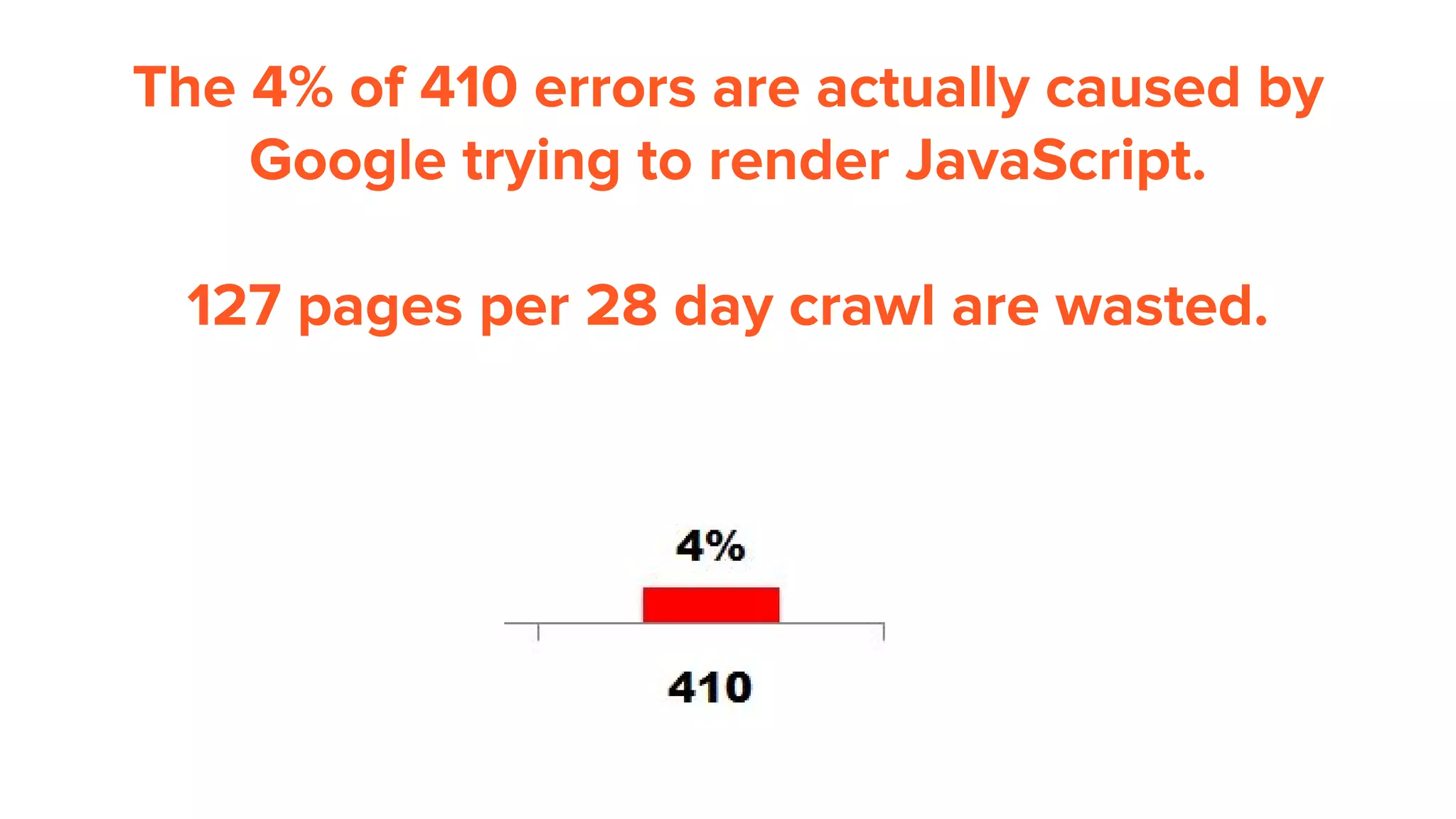
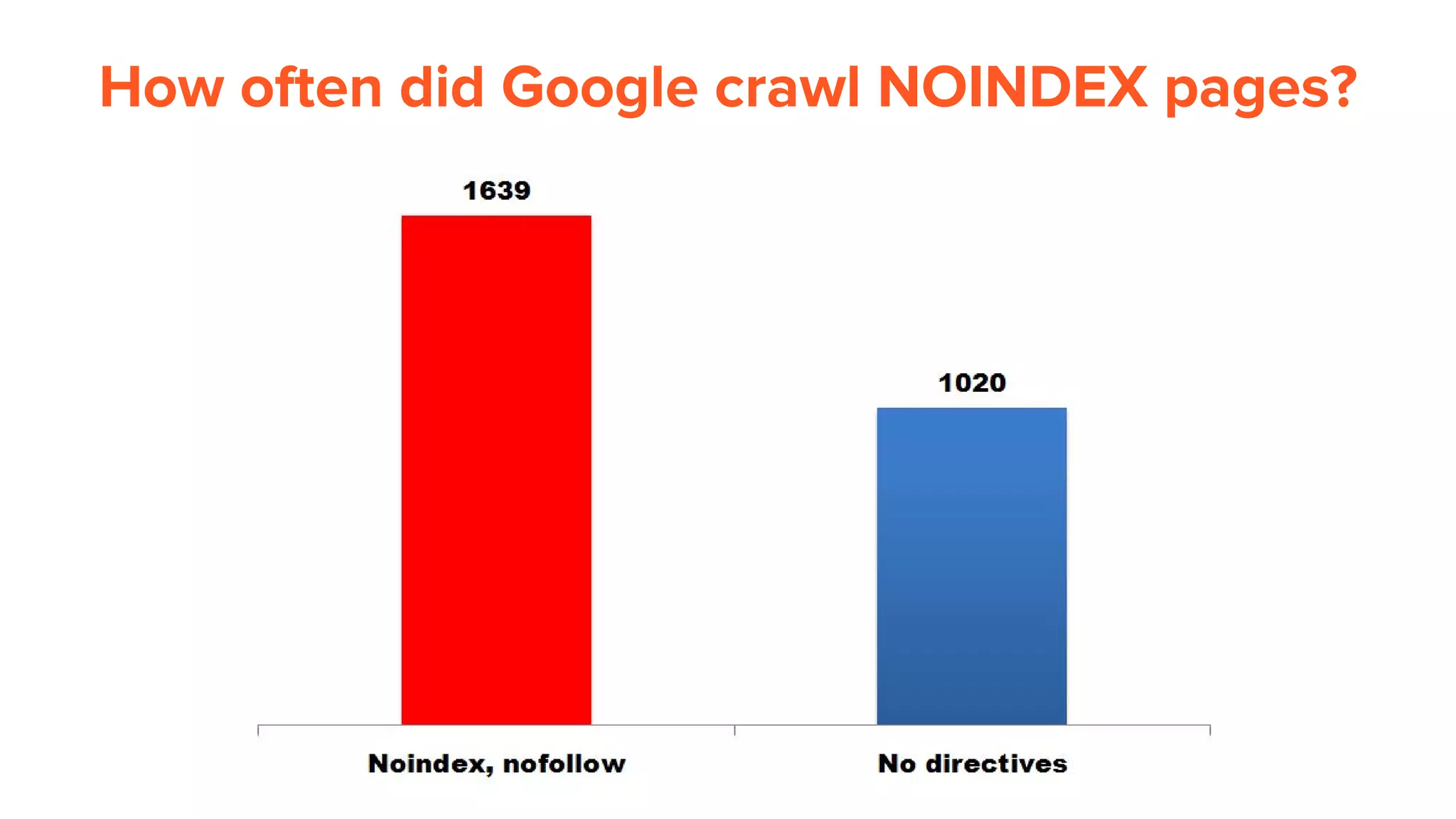
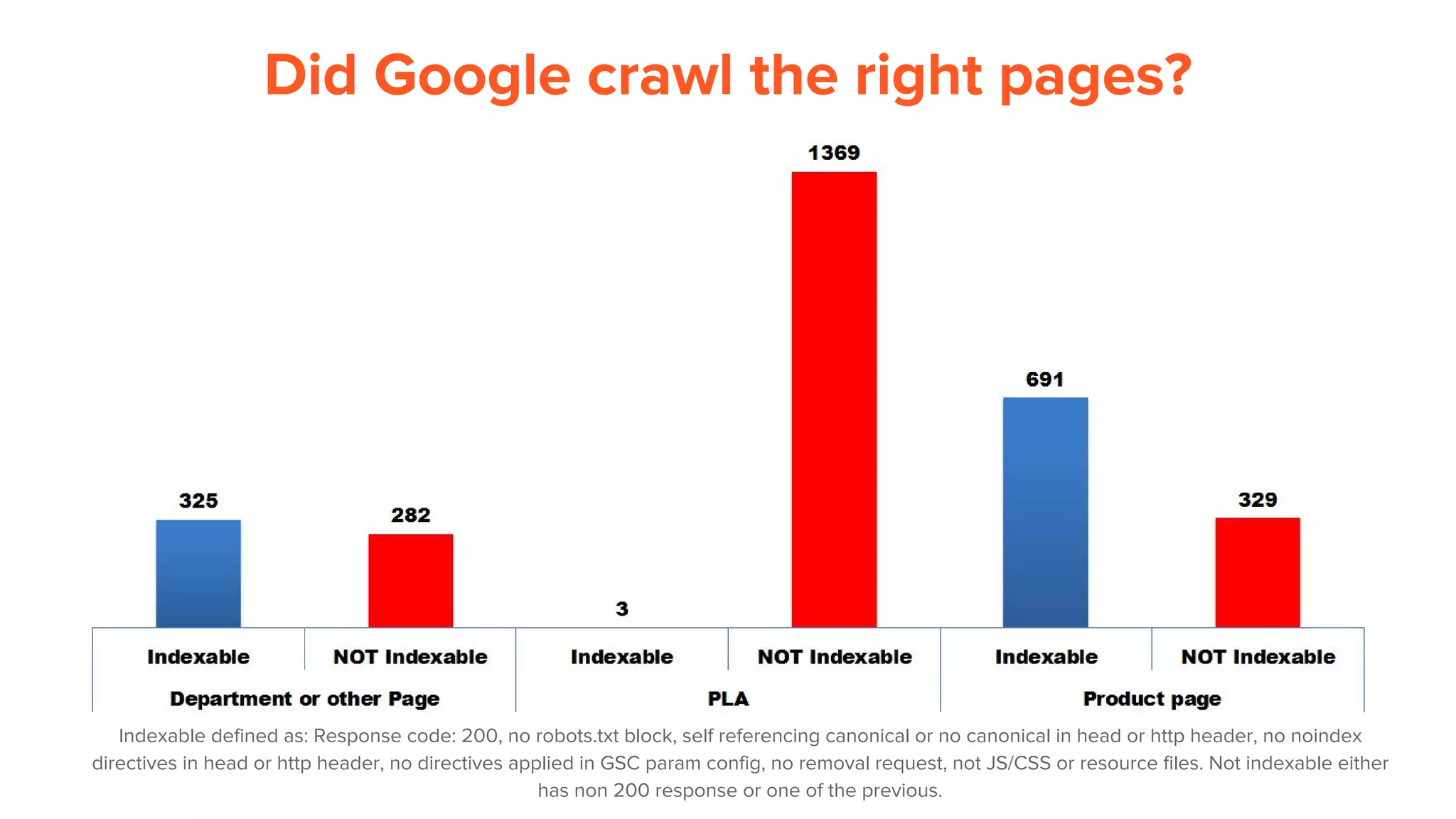


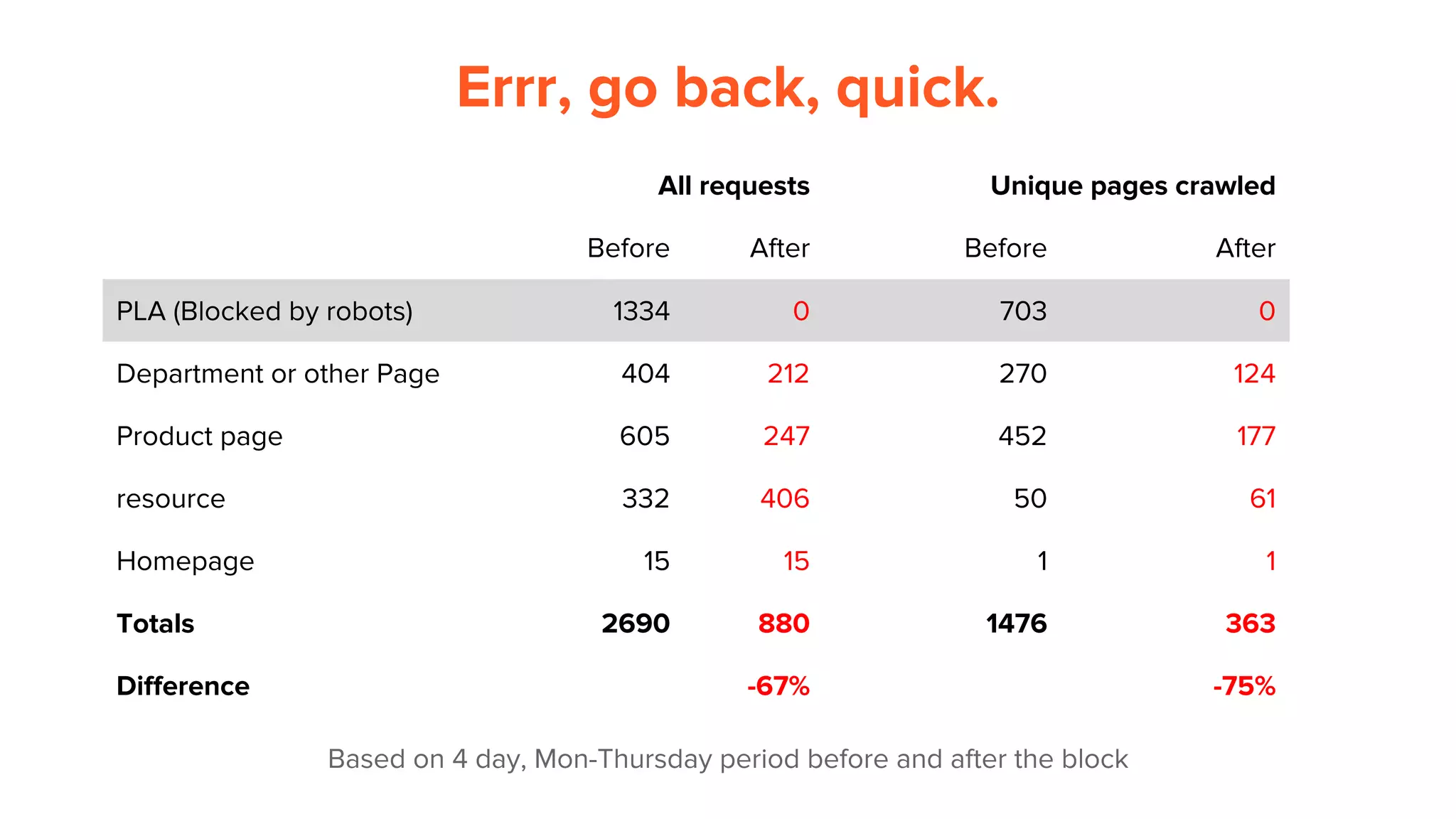


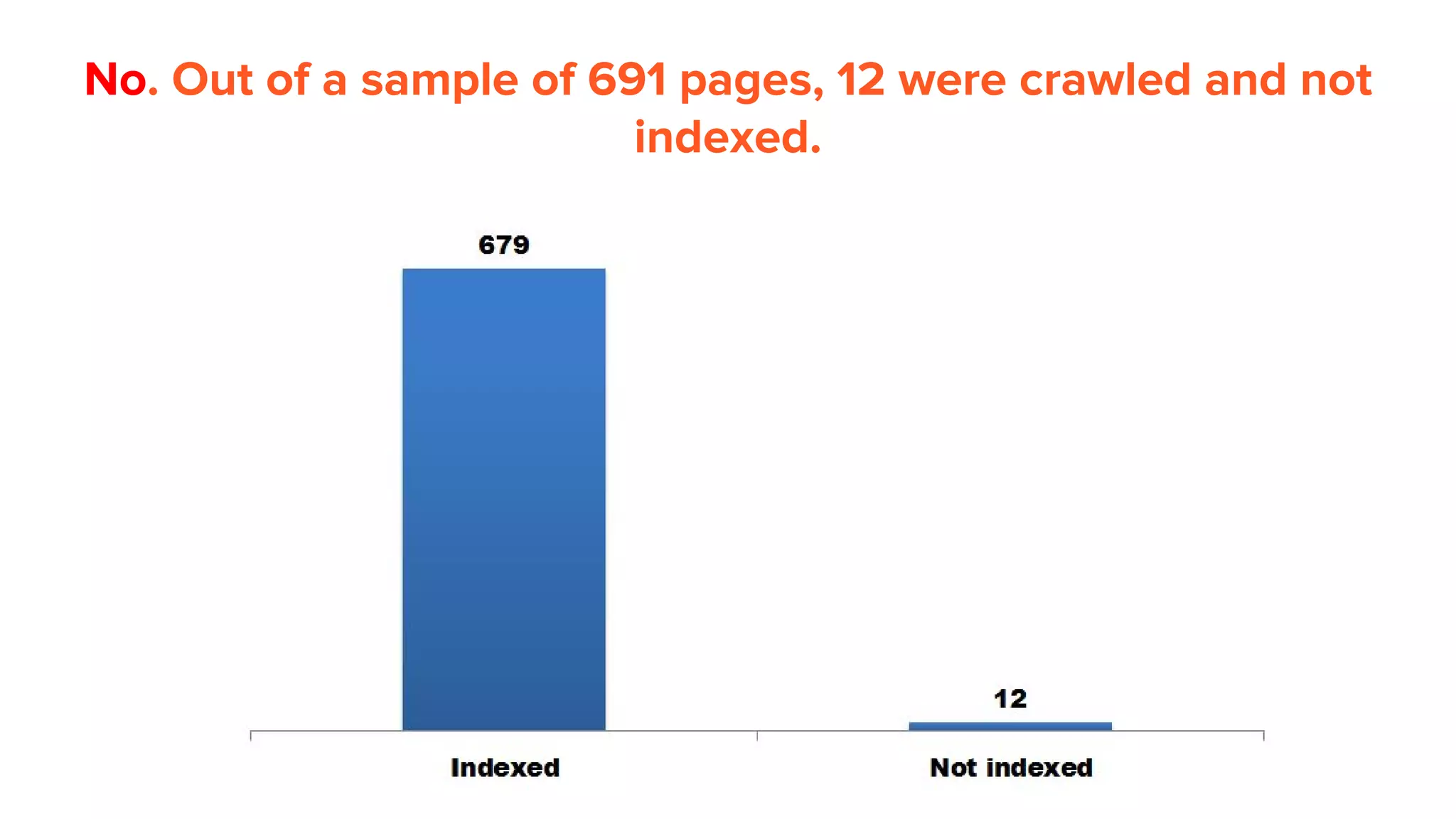

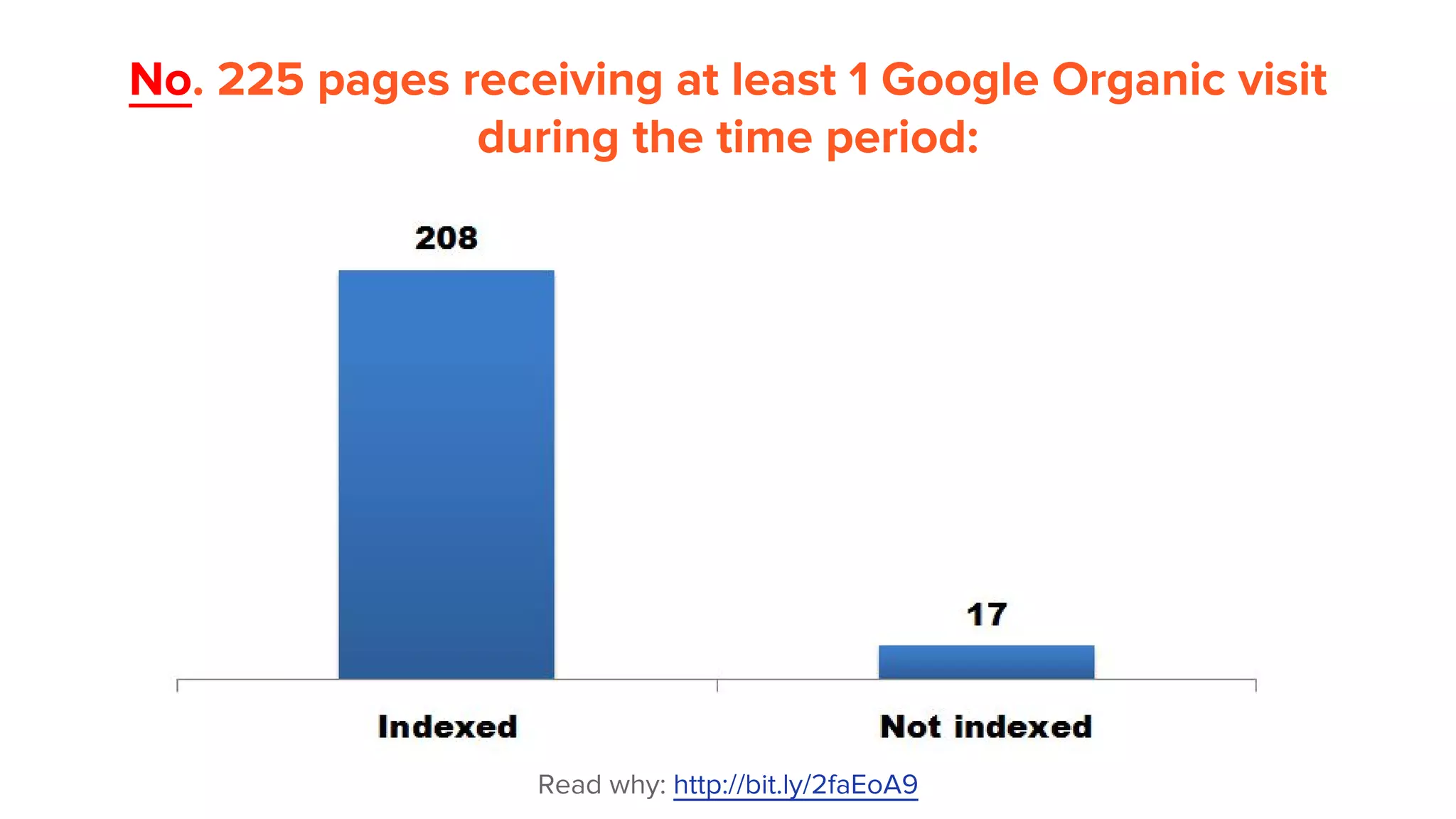


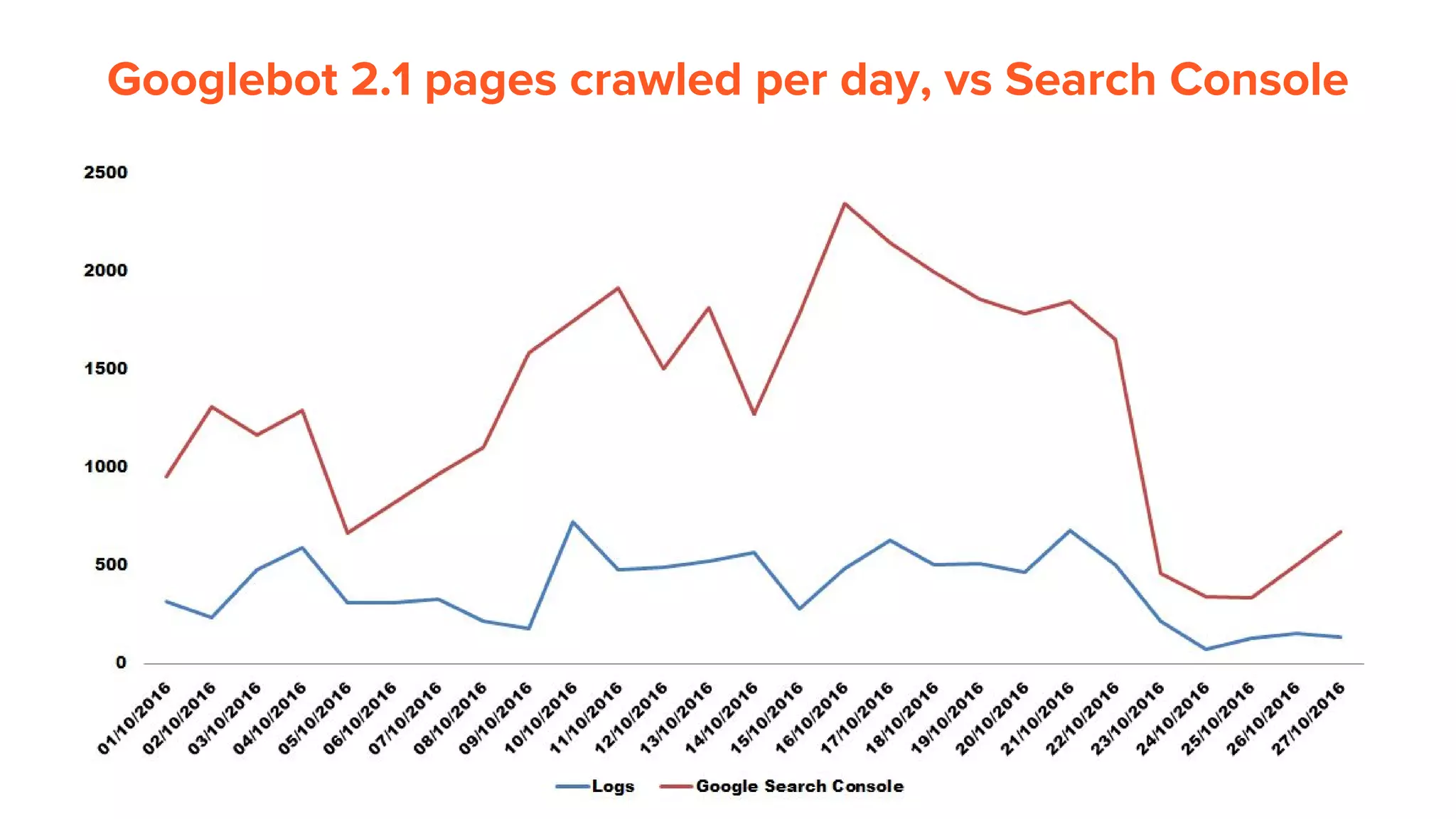
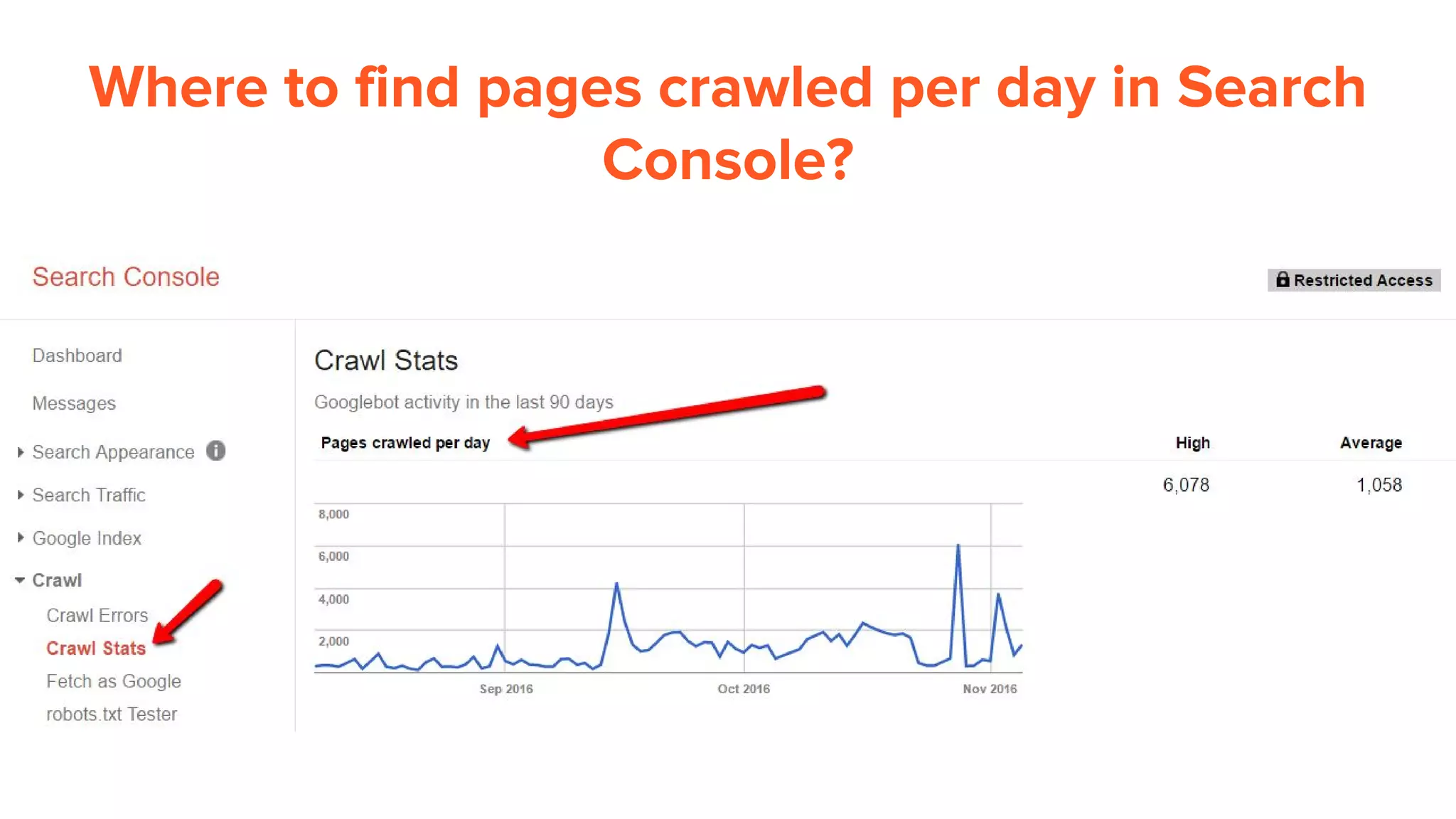
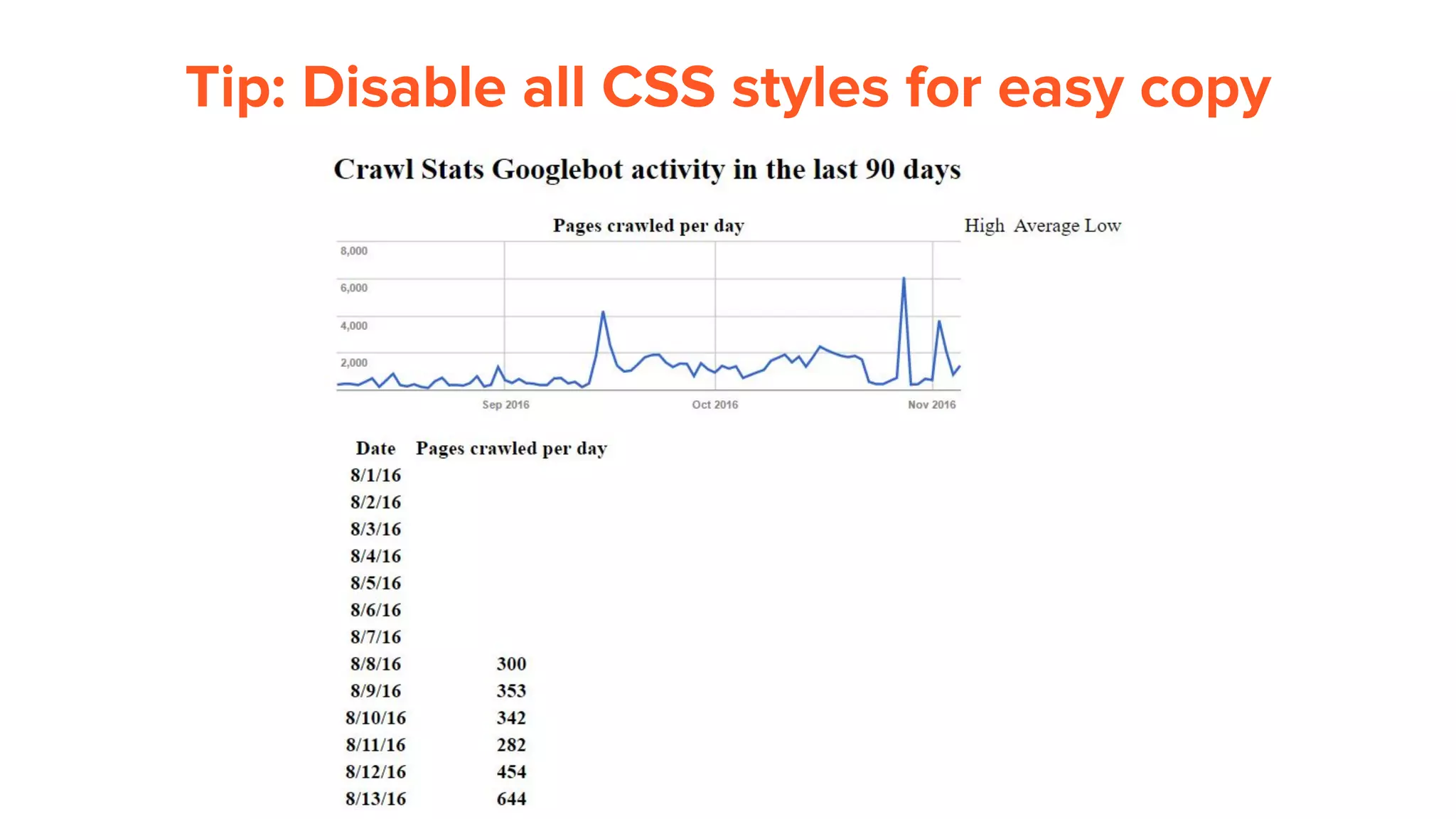
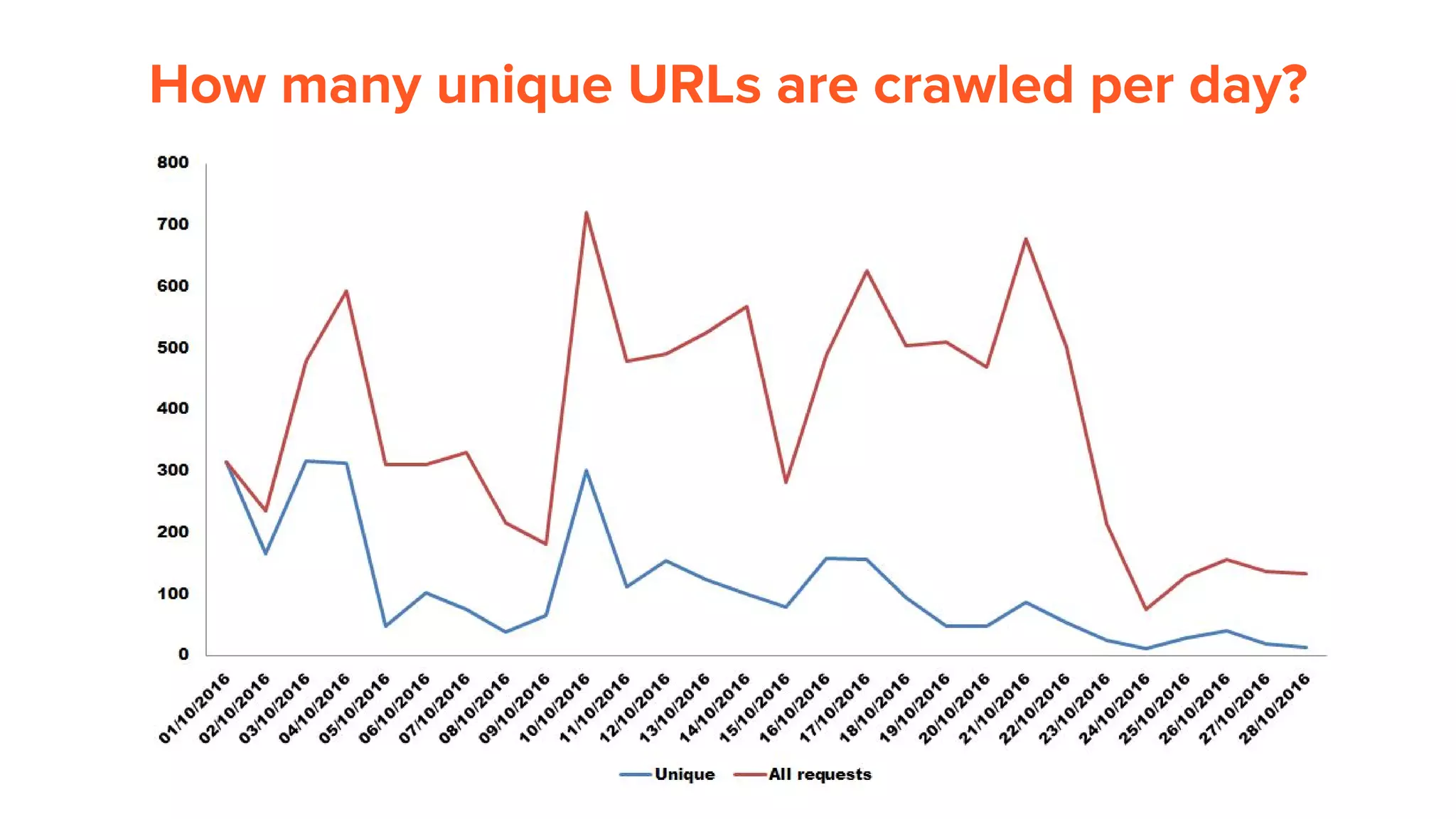
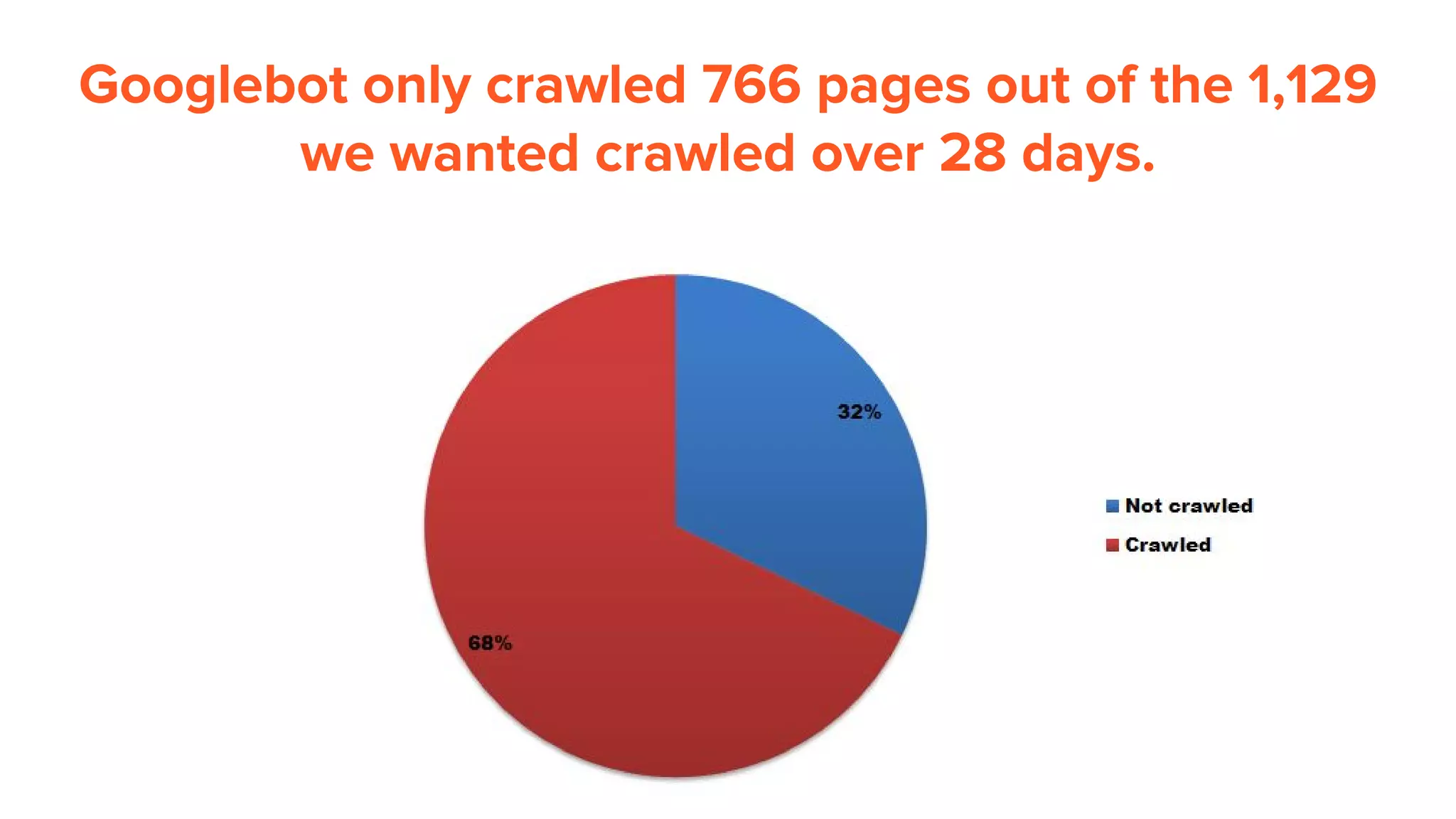

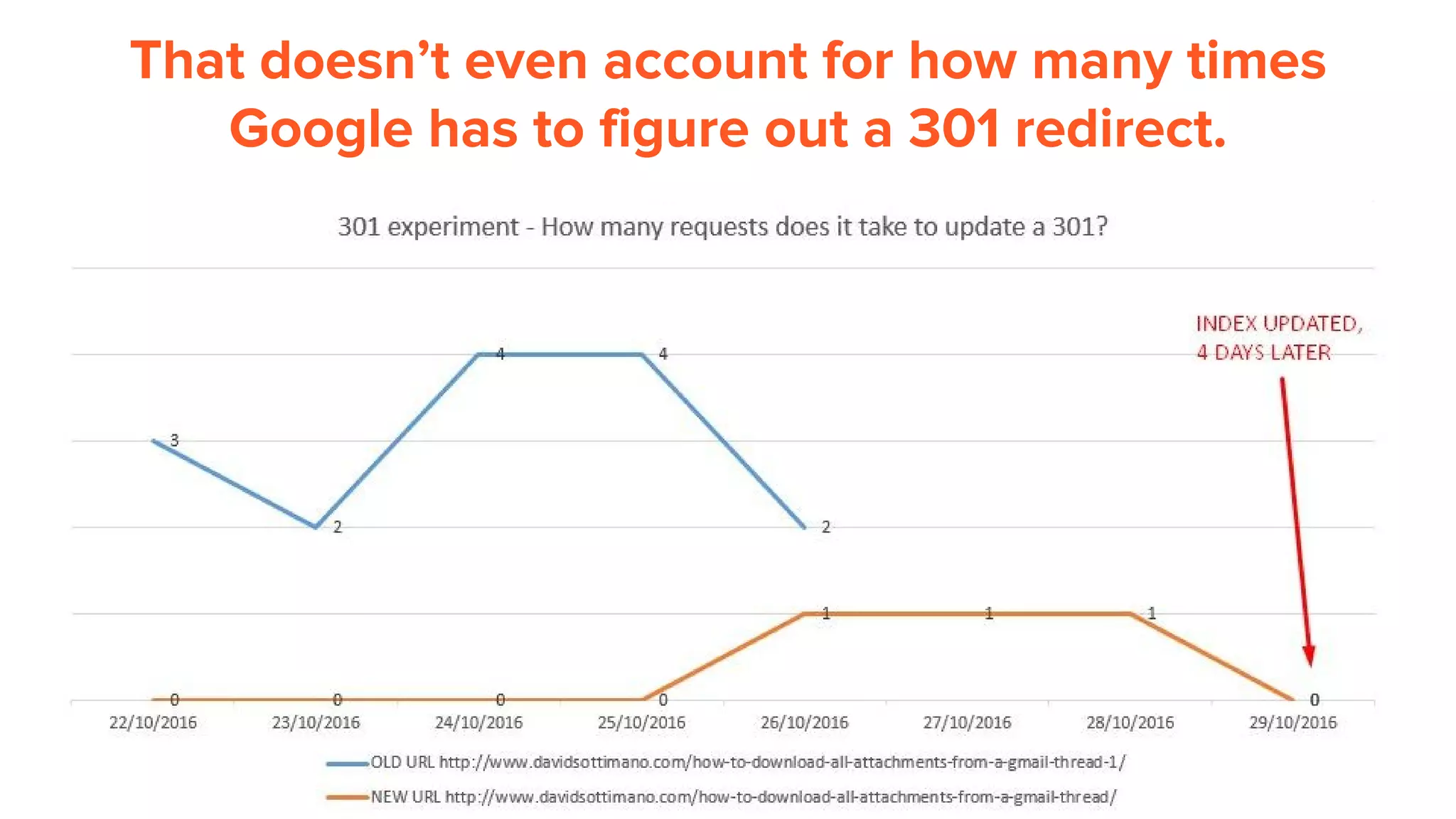



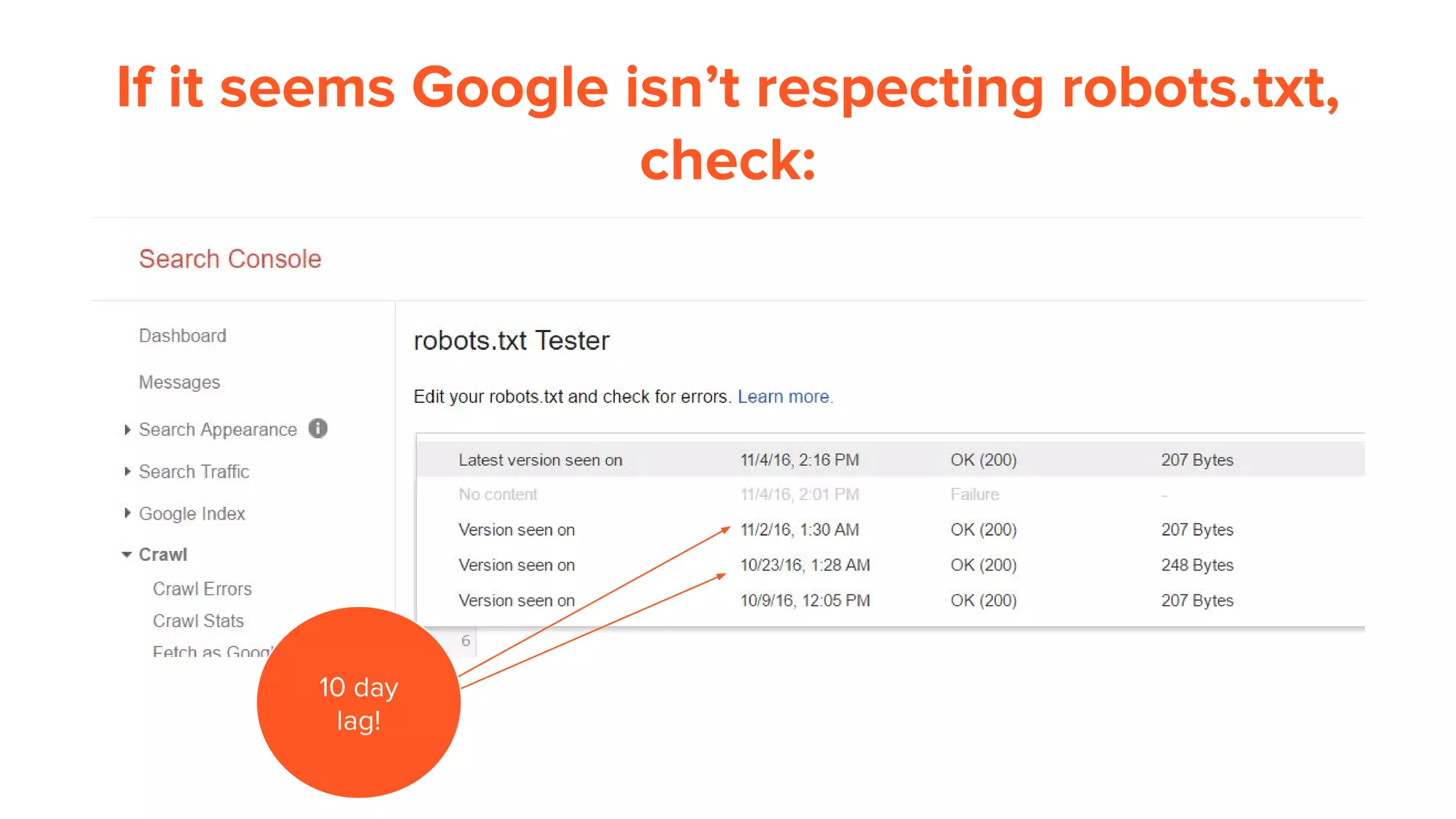

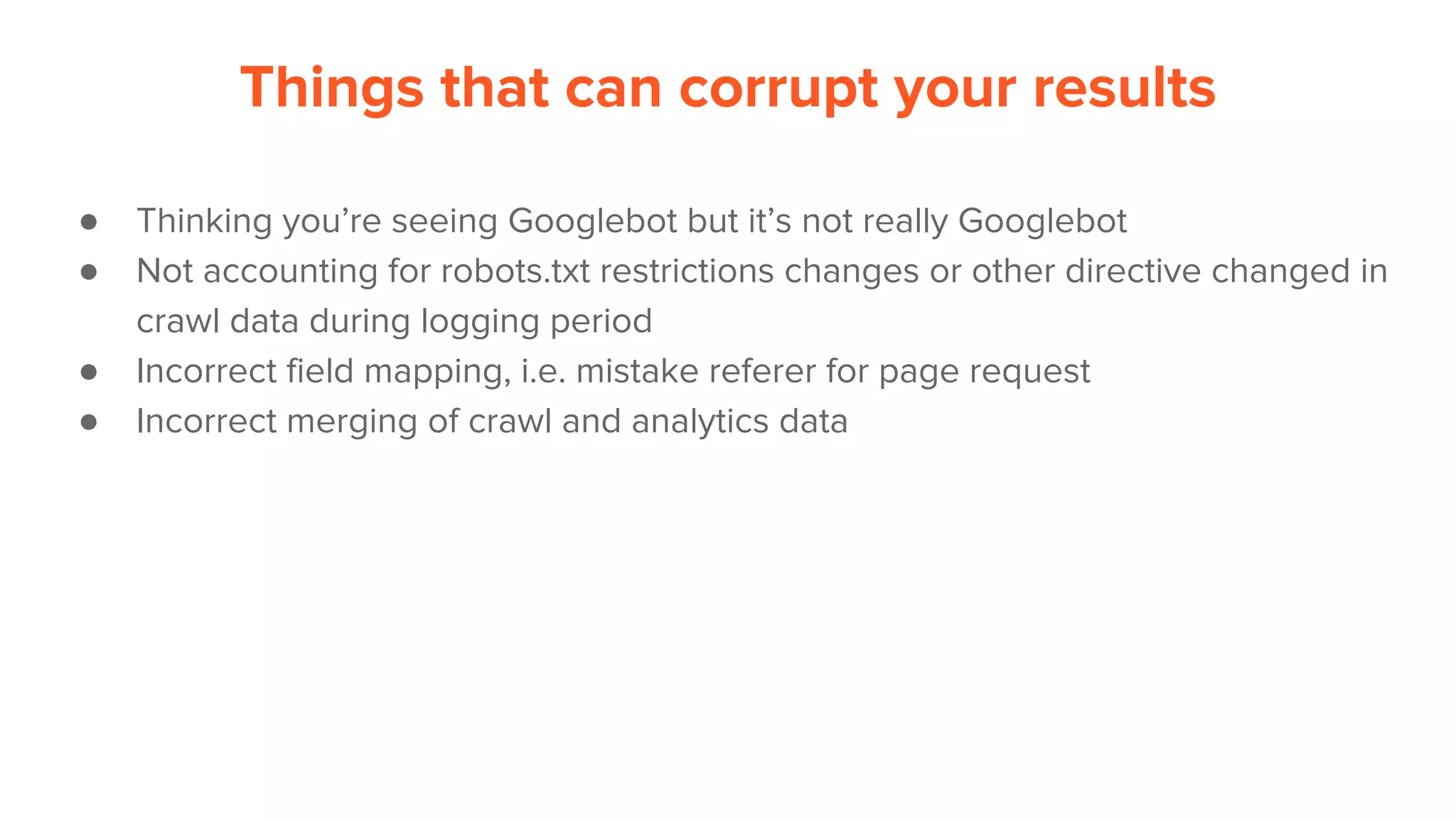


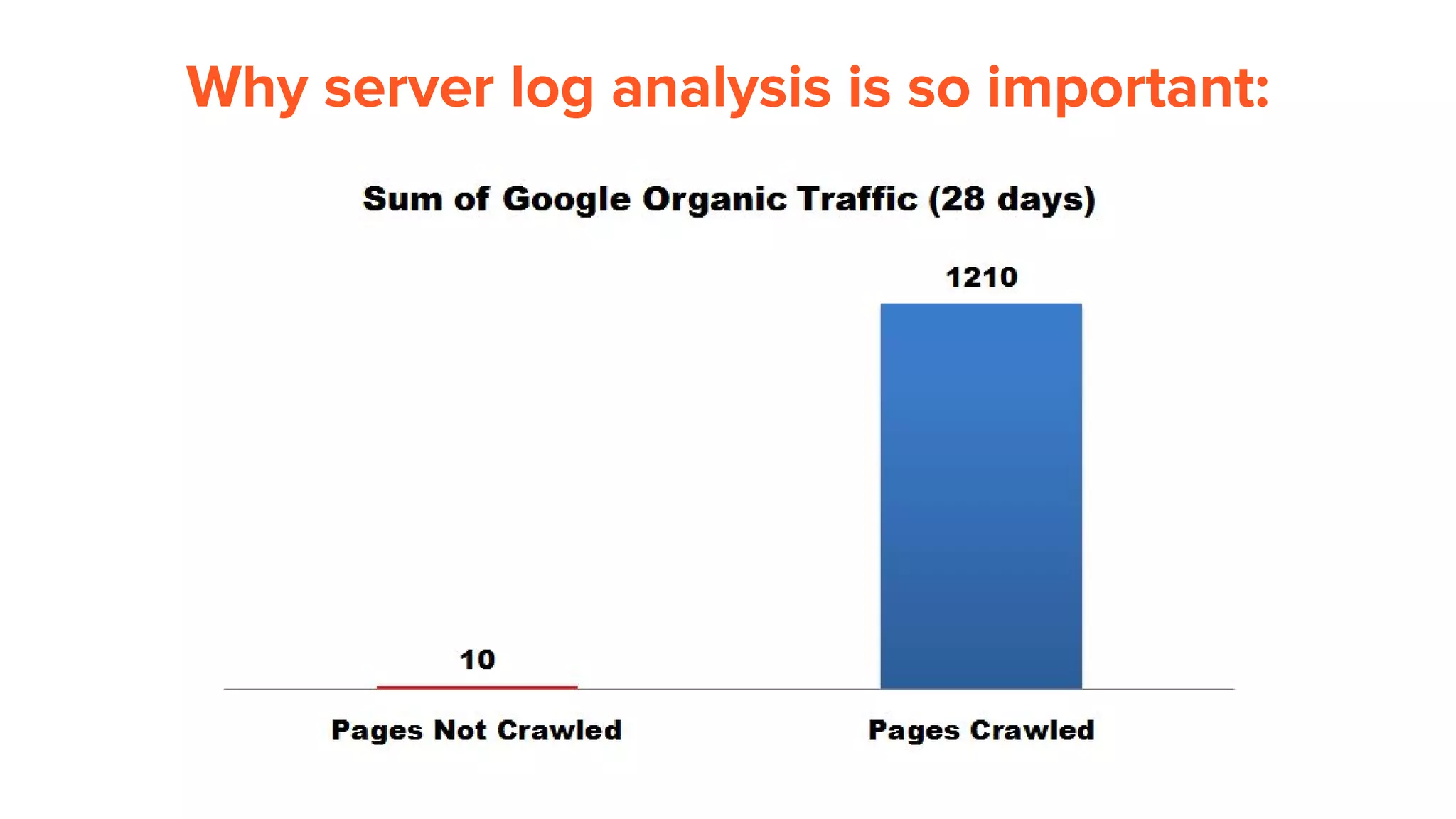
This document provides an overview of log analysis and how it can be used for search marketing purposes. It discusses how to properly obtain and parse server logs to extract useful search engine crawler data, common actions taken from log analysis like optimizing crawls and finding errors, and insights that can be gleaned like understanding crawl behavior and traffic patterns. It also covers potential issues that can corrupt analysis and provides helpful references.






















































































