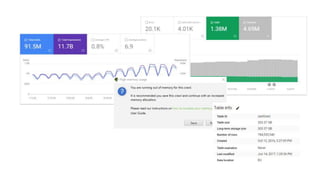
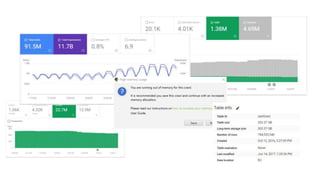
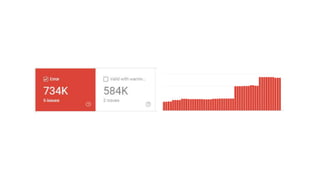
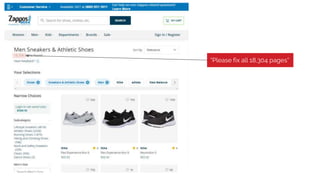
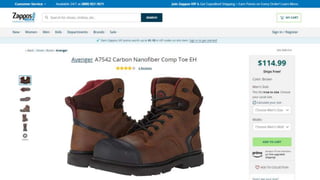
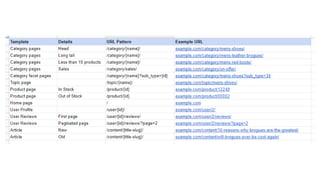
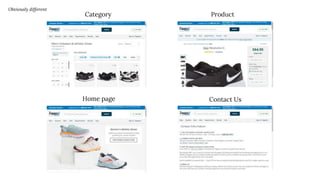
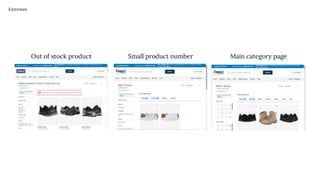
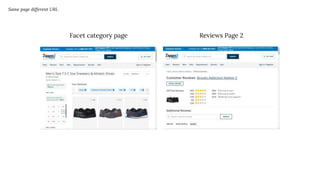
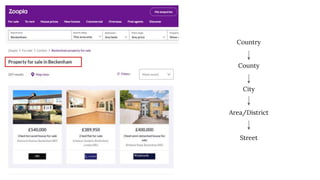
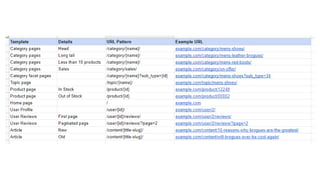
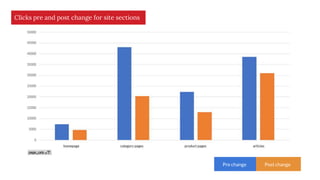
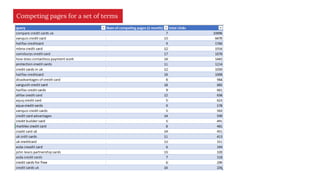
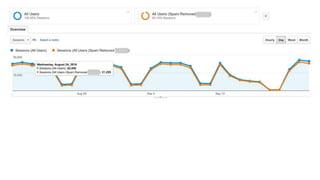
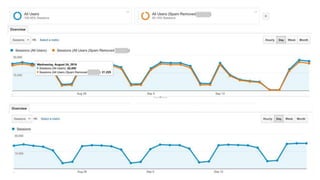
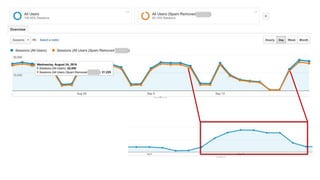
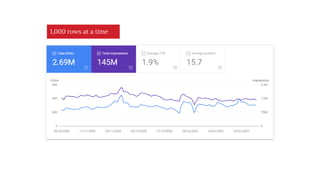
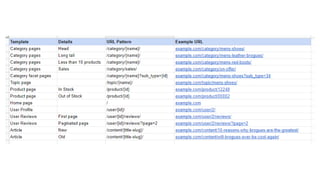
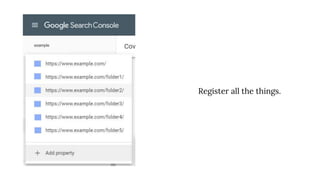
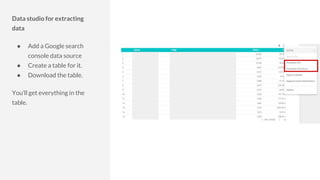
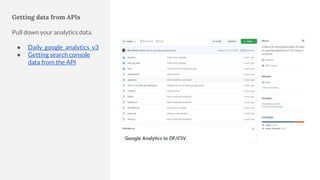
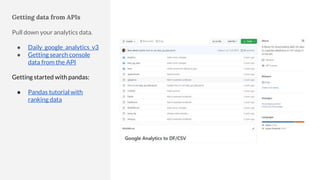
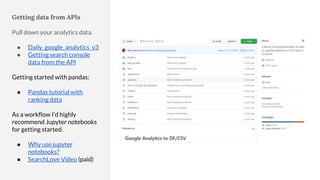
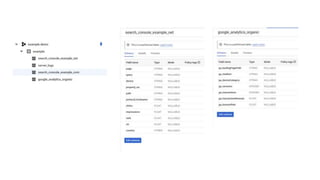
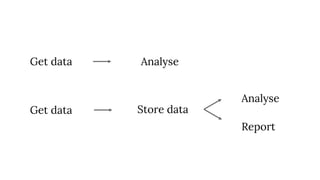
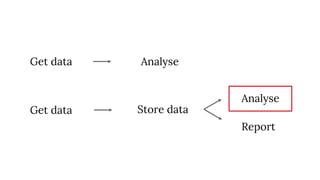
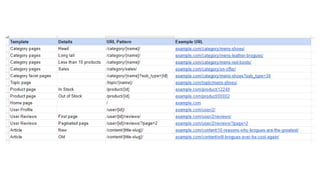
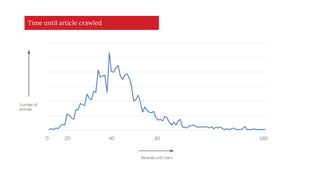
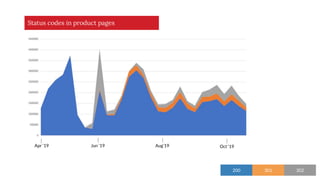
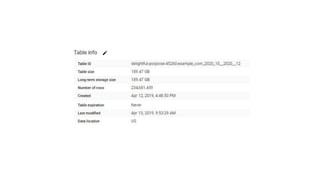
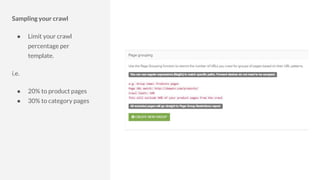
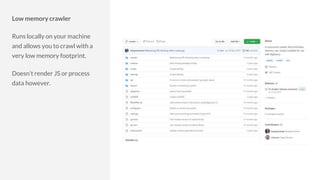
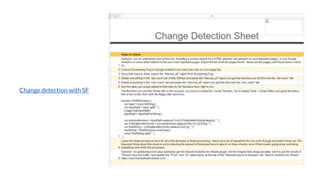
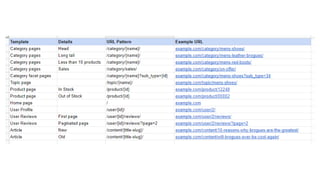
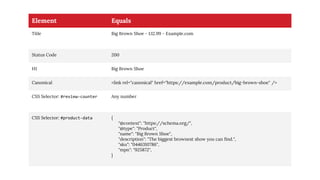
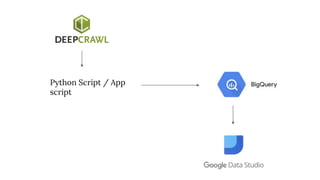
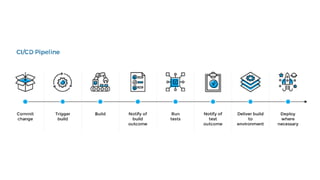
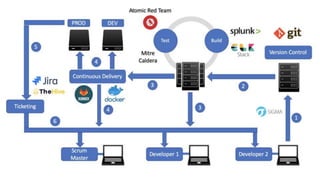
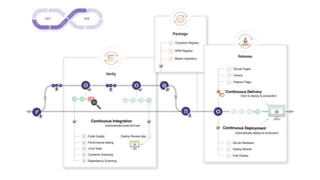
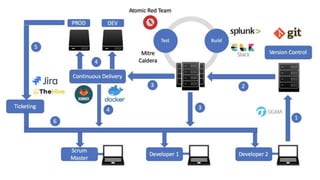
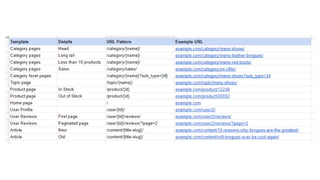
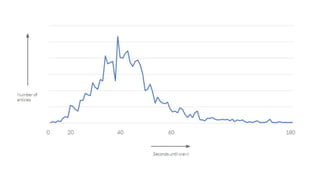
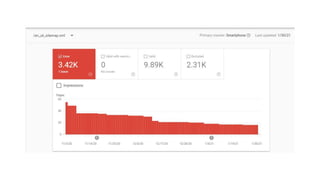
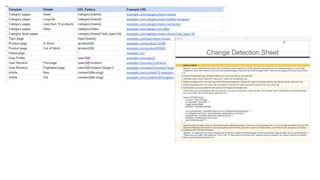
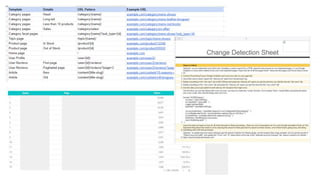
The document discusses the complexities of performing SEO for large websites, highlighting challenges such as data processing, technical issues, and the necessity of using various tools like Google Search Console and APIs. It emphasizes the importance of log analysis to understand search engine behaviors and offers methods for data extraction and reporting. Additionally, it covers techniques for managing crawling and indexing problems, including monitoring website changes and implementing unit tests for ongoing SEO health.