②特許文献からの情報抽出
17
必要性 特許文献を全部(すみからすみまで)読みたくない
利用関数 UnstructuredURLLoader
CharacterTextSplitter
Chroma
サンプルchain = RetrievalQAWithSourcesChain.from_chain_type(model,
chain_type="map_reduce", retriever=docsearch.as_retriever())
q1="この発明に記載の方法で処理できる物質を教えてください。
"
chain({"question": q1}, return_only_outputs=True)
output:
{'answer': 'Types of waste that can be processed include
normal garbage, toilet solid waste, organic waste, and small
amounts of PVC plastic containing chlorine. Glass and metal
are not melted but are recovered as completely sterilized at
the end of the process cycle for recycling.n', 'sources':
'https://patents.google.com/patent/WO2020118236A1/en,
https://patents.google.com/patent/US7998226B2/en'}
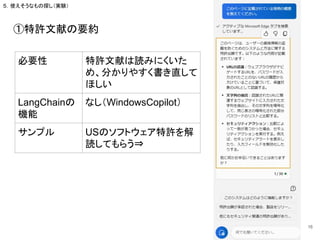
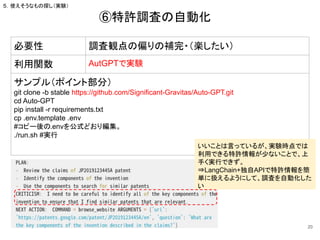
5.使えそうなもの探し(実験)
21
必要性 分析の観点のアイデア出し
利用関数 LLMChain、human、AgentExecutor、ZeroShotAgent
サンプル(ポイント部分)
tools= [ Tool( name="Search", func=search.run, description="useful for when
you need to answer questions about current events" , ),
Tool( name="Human", func=human.HumanInputRun(description="useful for when you
need to ask human yes or no about questions." ) ) ]
llm_chain = LLMChain(llm=llm, prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True,
memory=memory
)
agent_chain.run(input="make an abduction.",compA="A株式会社",compB="B株式会社",technology="内視
鏡")
⑦分析仮説の作成(1/2)
問:A社とB社が技術的に**分野
で繋がっている理由について仮説を
作る
5.使えそうなもの探し(実験)
人間を道具にできる
24
必要性 特許以外の関連情報を参照したい
利用関数 ConversationalRetrievalChain
KayAiRetriever
サンプル(ポイント部分)
retriever= KayAiRetriever.create(dataset_id="company", data_types=["10-K",
"10-Q","PressRelease"], num_contexts=6)
qa = ConversationalRetrievalChain.from_llm(model, retriever=retriever)
questions = [
"What is IBM's patent strategy?",
]
chat_history = []
for question in questions:
result = qa({"question": question, "chat_history": chat_history})
chat_history.append((question, result["answer"]))
docs = retriever.get_relevant_documents(question)
print(f"-> **Question**: {question} n")
print(f"**Answer**: {result['answer']} n")
⑨有価証券報告書からデータ抽出
5.使えそうなもの探し(実験)
-> **Question**: What is IBM's patent strategy?
**Answer**: IBM's patent strategy focuses on seeking IP protection for its innovations while also
emphasizing other initiatives designed to leverage its IP leadership. The company actively pursues
intellectual property and invests approximately 8 percent of its total revenue in research and development
(R&D). IBM Research works with clients and business units to deliver new technologies and address
challenges in areas such as artificial intelligence, quantum computing, security, cloud, and systems. In
2019, IBM was awarded more U.S. patents than any other company, with a total of 9,262 patents,
including patents related to artificial intelligence, cloud, cybersecurity, and quantum computing.
問:IBMの特許戦略は?
⇒SCE Filings(有価証券報告書みたいな情
報)から情報を収集・まとめてくれる。













![③特許文献中に書いてある(かもしれない)ことを抽出
18
必要性 特許文献を全部(すみからすみまで)読みたくな
い。しかも書いてない可能性もある
利用関数 create_extraction_chain
recursiveCharacterTextSplitter
AsyncHtmlLoader
BeautifulSoupTransformer
サンプル urls =
["https://patents.google.com/patent/US20190078220A1/en"]#,"https://pate
nts.google.com/patent/US20160237578A1/en","https://patents.google.com
/patent/US20160237578A1/en?"]
extracted_content = scrape_with_playwright(urls, schema=schema)
Fetching pages: 100%|##########| 1/1 [00:00<00:00,
13.23it/s]
Extracting content with LLM [{'Anode initial overvoltage': '1.7
to 1.9 V', 'Anode overvoltage': '0.3 to 0.4 Acm−2',
'durability': 'more than several tens of years'}]
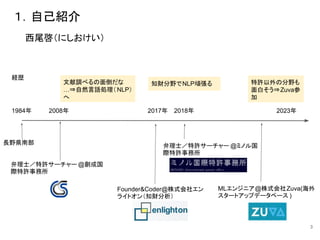
5.使えそうなもの探し(実験)
問:文献中に初期
過電圧と過電圧
について記載が
あるか?](https://image.slidesharecdn.com/gasg9th-231018033150-79323051/85/LLM-LangChain-18-320.jpg)
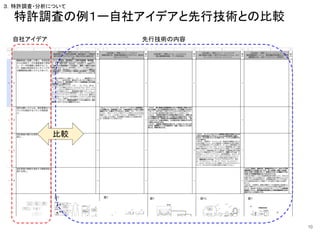
![④課題・解決手段マップ作成
19
必要性 課題と解決手段のクロス集計する(ために、文献1件
毎に「課題」と「解決手段」を抽出したい)
利用関数 create_tagging_chain
create_tagging_chain_pydantic
サンプル
schema = {
"properties": {
"課題": {"type": "string","description":"発明が解決しようとする課題を抽出"
,"enum":["生産性","滋養強壮","ダイエット","安全性","抗酸化","血中脂質改善、血圧降下","美容"]},
"解決手段": {"type": "string","description":"課題を解決するための方法や手段を抽出"
,"enum":["製造-酵素処理","製造-造粒・成形","製造-粉砕","製造-発酵","製造-混合・攪拌","製造-洗浄","製造-化学的処理","
製造-加熱","製造-分離抽出","製造-冷却","製造-乾燥","製造-その他"]},
"効果": {"type": "string","description":"発明によるメリットや効果"
},
},
"required": ["課題", "解決手段"],}
chain = create_tagging_chain(schema=schema, llm=llm)
5.使えそうなもの探し(実験)](https://image.slidesharecdn.com/gasg9th-231018033150-79323051/85/LLM-LangChain-19-320.jpg)
![21
必要性 分析の観点のアイデア出し
利用関数 LLMChain、human、AgentExecutor、ZeroShotAgent
サンプル(ポイント部分)
tools = [ Tool( name="Search", func=search.run, description="useful for when
you need to answer questions about current events" , ),
Tool( name="Human", func=human.HumanInputRun(description="useful for when you
need to ask human yes or no about questions." ) ) ]
llm_chain = LLMChain(llm=llm, prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True,
memory=memory
)
agent_chain.run(input="make an abduction.",compA="A株式会社",compB="B株式会社",technology="内視
鏡")
⑦分析仮説の作成(1/2)
問:A社とB社が技術的に**分野
で繋がっている理由について仮説を
作る
5.使えそうなもの探し(実験)
人間を道具にできる](https://image.slidesharecdn.com/gasg9th-231018033150-79323051/85/LLM-LangChain-21-320.jpg)

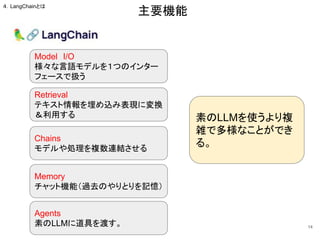
![23
必要性 分析の観点のアイデア出し・自分の知識・考えの偏り
の補完
利用関数 Agents
サンプル(ポイント部分)
names = {
"scientist": ["arxiv", "ddg-search", "wikipedia"],
"marketer": ["arxiv", "ddg-search", "wikipedia"],
"desingner": ["arxiv", "ddg-search", "wikipedia"], }
topic = "metamaterialsの可能性"
max_iters = 6
n = 0
simulator = DialogueSimulator(agents=agents, selection_function=select_next_speaker)
simulator.reset()
simulator.inject("Moderator", specified_topic) print(f"(Moderator): {specified_topic}")
print("n") while n < max_iters: name, message = simulator.step() print(f"({name}):
{message}") print("n") n += 1
⑧LLM同士で議論
Githubにも類似のものは色々とあります。
役割
使える道具
https://github.com/microsoft/autogen
https://github.com/dinobby/ReConcile
https://github.com/geekan/MetaGPT
https://github.com/aiwaves-cn/agents
5.使えそうなもの探し(実験)](https://image.slidesharecdn.com/gasg9th-231018033150-79323051/85/LLM-LangChain-23-320.jpg)
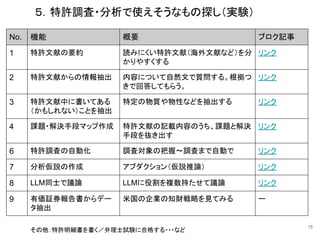
![24
必要性 特許以外の関連情報を参照したい
利用関数 ConversationalRetrievalChain
KayAiRetriever
サンプル(ポイント部分)
retriever = KayAiRetriever.create(dataset_id="company", data_types=["10-K",
"10-Q","PressRelease"], num_contexts=6)
qa = ConversationalRetrievalChain.from_llm(model, retriever=retriever)
questions = [
"What is IBM's patent strategy?",
]
chat_history = []
for question in questions:
result = qa({"question": question, "chat_history": chat_history})
chat_history.append((question, result["answer"]))
docs = retriever.get_relevant_documents(question)
print(f"-> **Question**: {question} n")
print(f"**Answer**: {result['answer']} n")
⑨有価証券報告書からデータ抽出
5.使えそうなもの探し(実験)
-> **Question**: What is IBM's patent strategy?
**Answer**: IBM's patent strategy focuses on seeking IP protection for its innovations while also
emphasizing other initiatives designed to leverage its IP leadership. The company actively pursues
intellectual property and invests approximately 8 percent of its total revenue in research and development
(R&D). IBM Research works with clients and business units to deliver new technologies and address
challenges in areas such as artificial intelligence, quantum computing, security, cloud, and systems. In
2019, IBM was awarded more U.S. patents than any other company, with a total of 9,262 patents,
including patents related to artificial intelligence, cloud, cybersecurity, and quantum computing.
問:IBMの特許戦略は?
⇒SCE Filings(有価証券報告書みたいな情
報)から情報を収集・まとめてくれる。](https://image.slidesharecdn.com/gasg9th-231018033150-79323051/85/LLM-LangChain-24-320.jpg)
























































![ifLink[改善版].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/iflink-230714052555-8cd84b5f-thumbnail.jpg?width=640&height=640&fit=bounds)
![AIの取り組み[改訂版].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ai-230714052449-591e7119-thumbnail.jpg?width=640&height=640&fit=bounds)





