

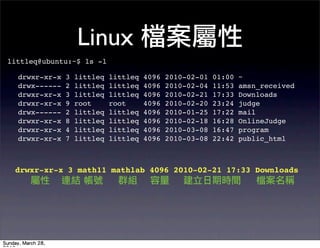




![chown-
• chown [-R] < >[: ] < >
• chown -R monkey:mathlab banana
• chown littleq aicp0529](https://image.slidesharecdn.com/linux-100821132305-phpapp01/85/Linux-Permission-8-320.jpg)



This document discusses Linux file permissions and commands used to modify permissions. It explains the rwx permissions for owner, group, and other using an example ls -l output. It then covers the chmod, chown, and chgrp commands to change file ownership, group, and permissions including recursive (-R) options and using symbolic modes.











































































































