Downloaded 31 times




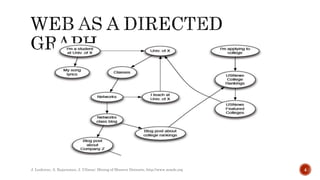
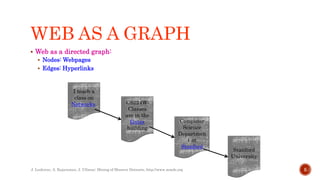






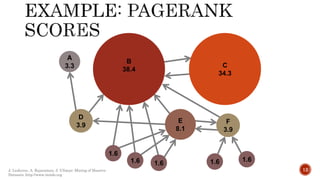

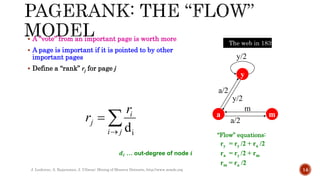






Link analysis uses graph theory to represent relationships between objects as edges in a graph. It can be used for both directed and undirected data mining. Link analysis ranking algorithms start with a set of web pages and rank them based on their link structure, with more important pages having more inbound links. PageRank is a specific link analysis algorithm that models the web as a directed graph and calculates page ranks through an iterative process where each page's rank is the sum of the ranks of pages that link to it.



































































