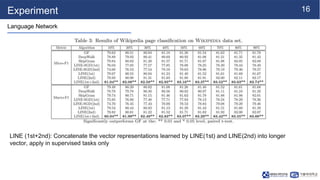
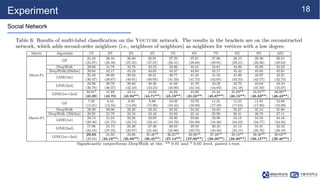
LINE is a network embedding algorithm that learns distributed representations of nodes in a graph. It aims to preserve both first-order and second-order proximity structures by optimizing an objective function. The algorithm is efficient and can learn embeddings for networks with millions of nodes and billions of edges. Empirical experiments on language, social, and citation networks demonstrate LINE's effectiveness at capturing network structures.



















![240401_JW_labseminar[LINE: Large-scale Information Network Embeddin].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240401jwlabseminarline-240408131509-f1e552b4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240311_LabSeminar_Huy]LINE: Large-scale Information Network Embedding.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/20240311labseminarhuyline-240409105447-1d798fce-thumbnail.jpg?width=640&height=640&fit=bounds)




![240506_JW_labseminar[Structural Deep Network Embedding].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240506jwlabseminarstructuraldeepnetworkembedding-240507042150-61ba62d3-thumbnail.jpg?width=640&height=640&fit=bounds)