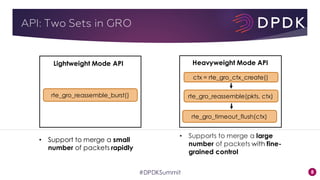
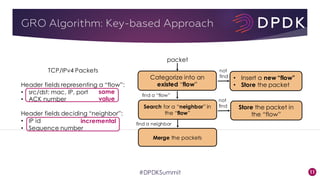
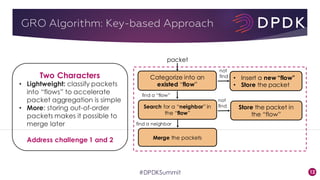
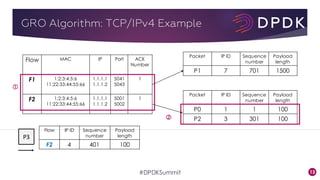
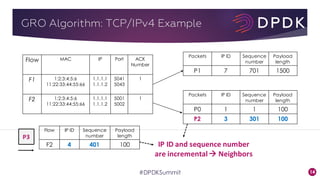
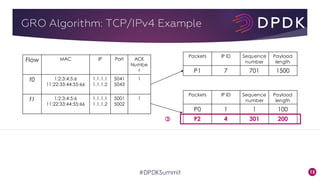
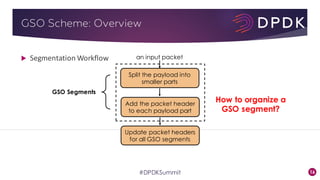
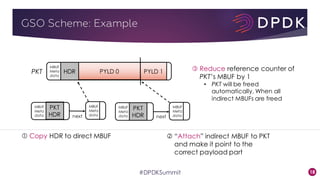
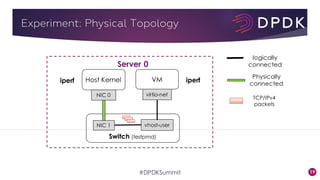
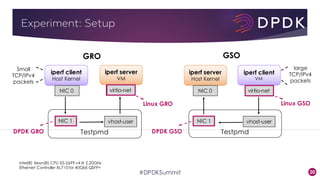
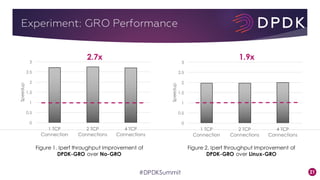
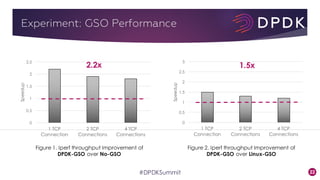
This document provides an overview of GRO and GSO in DPDK. It discusses how GRO and GSO can be used to reduce packet processing overheads by merging or splitting packets. It describes the GRO and GSO algorithms used in DPDK to handle packets in a lightweight manner. It also outlines an experiment that shows the performance improvements of DPDK GRO and GSO compared to no offloading or Linux offloading.




![7
API: How Applications Use it?
nb_pkts = rte_eth_rx_burst(…, pkts, …);
nb_segs = rte_gro_reassemble_burst(pkts, nb_pkts, …);
rte_eth_tx_burst(…, pkts, nb_segs);
struct rte_mbuf *gso_segs[N];
nb_segs = rte_gso_segment(…, pkt, gso_segs, …);
rte_eth_tx_burst(…, gso_segs, nb_segs);
GRO Sample
GSO Sample](https://image.slidesharecdn.com/5-171118034908/85/LF_DPDK17_GRO-GSO-Libraries-Bring-Significant-Performance-Gains-to-DPDK-based-Applications-7-320.jpg)