Downloaded 20 times







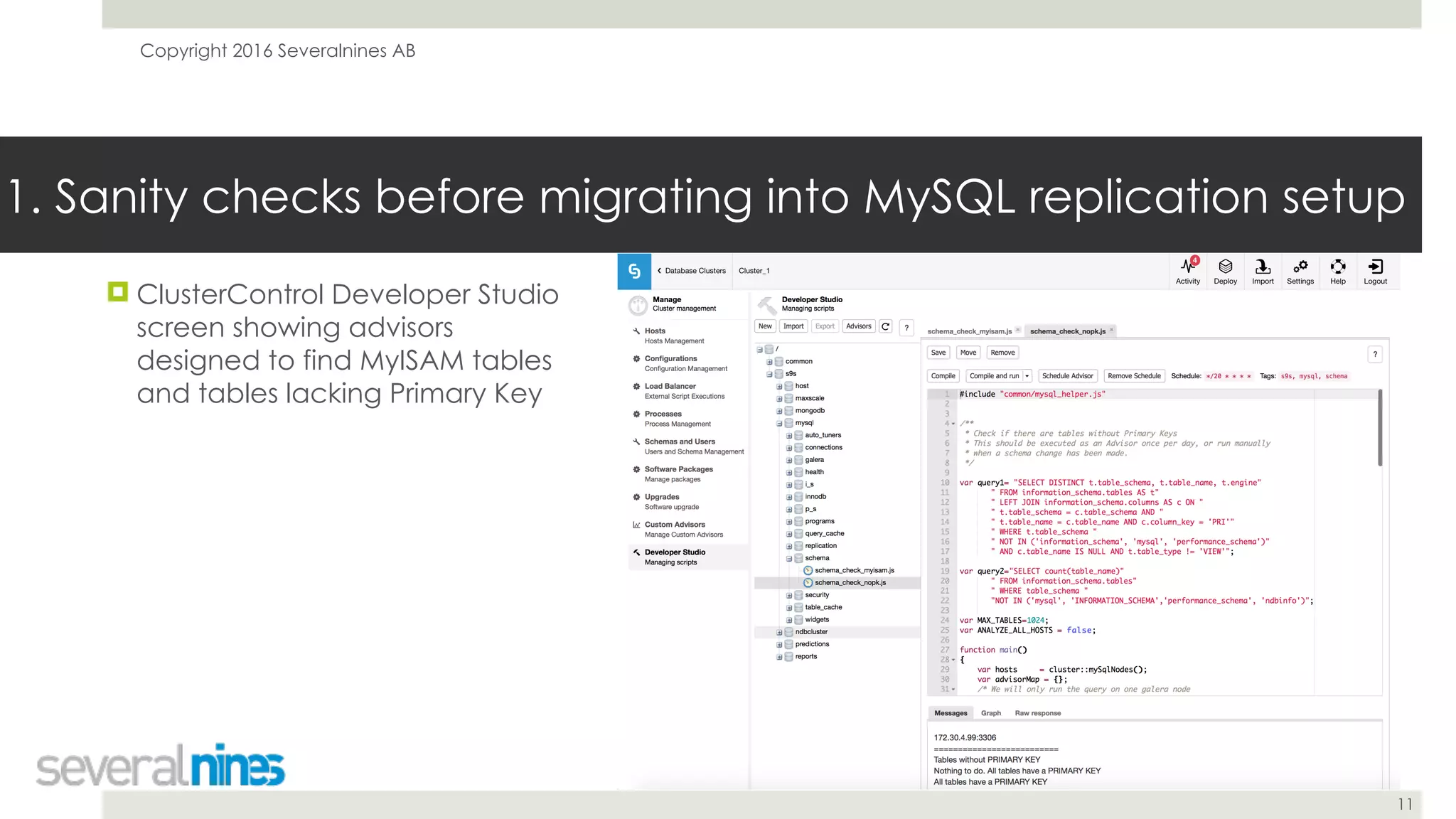



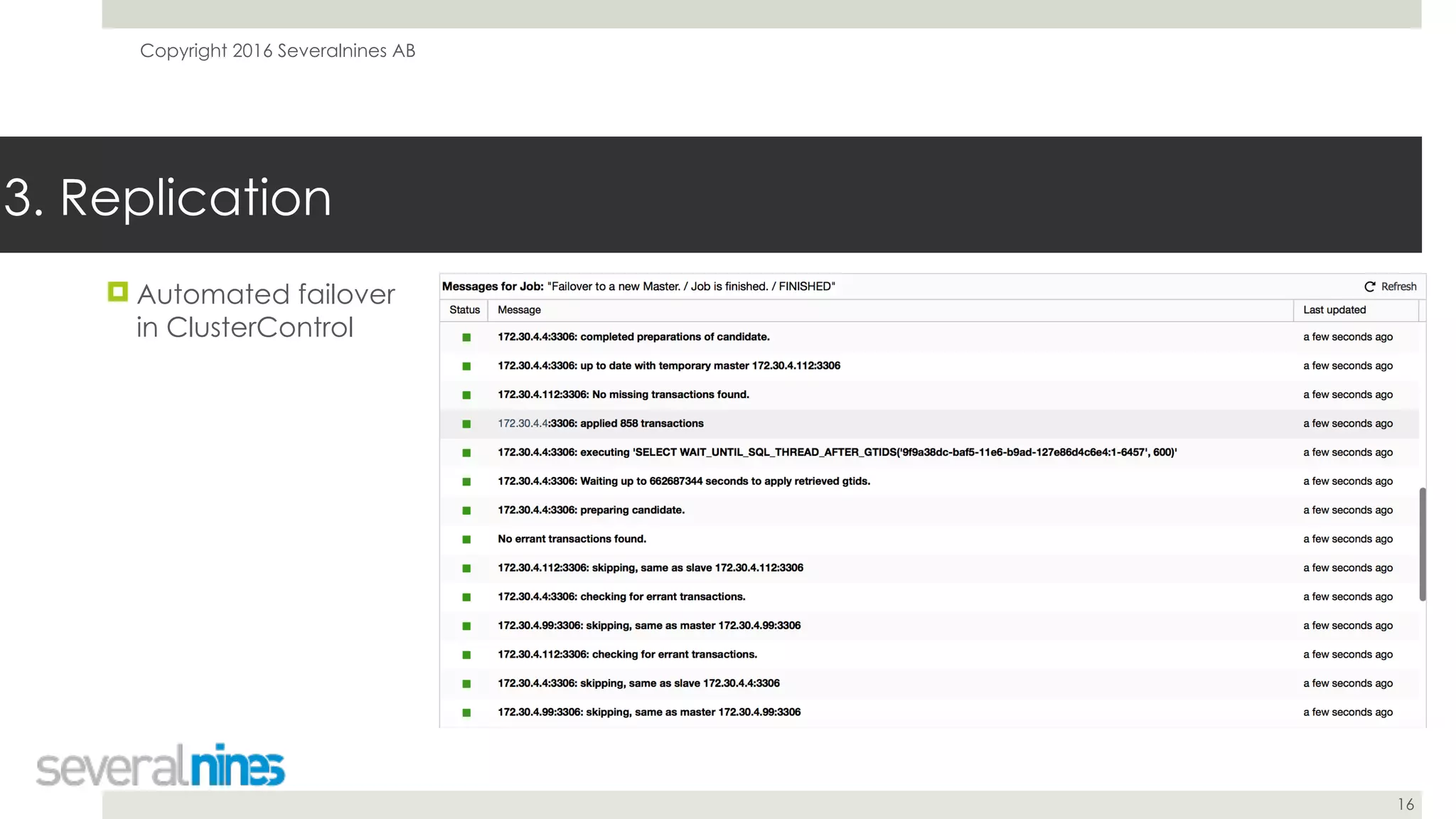






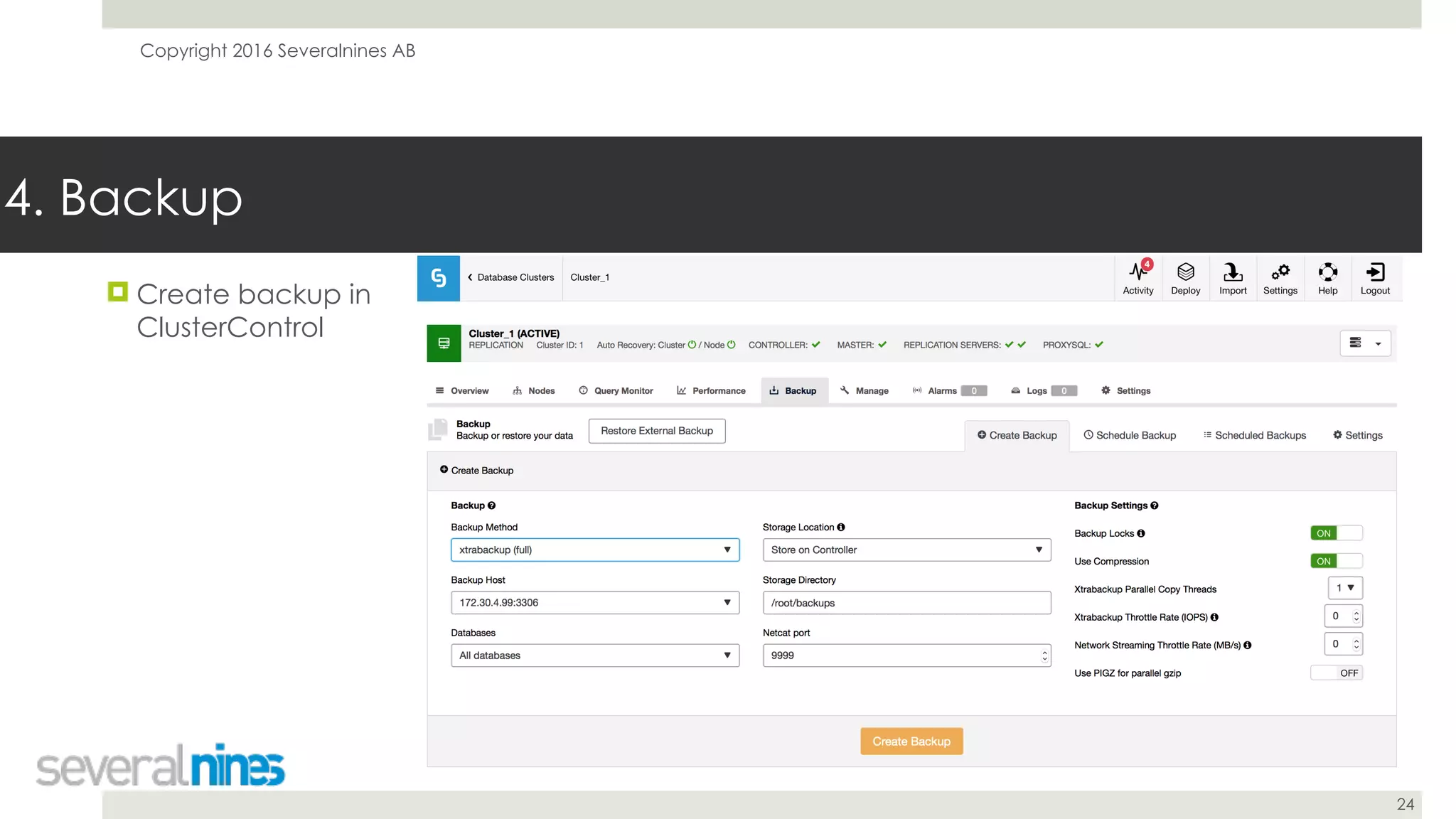
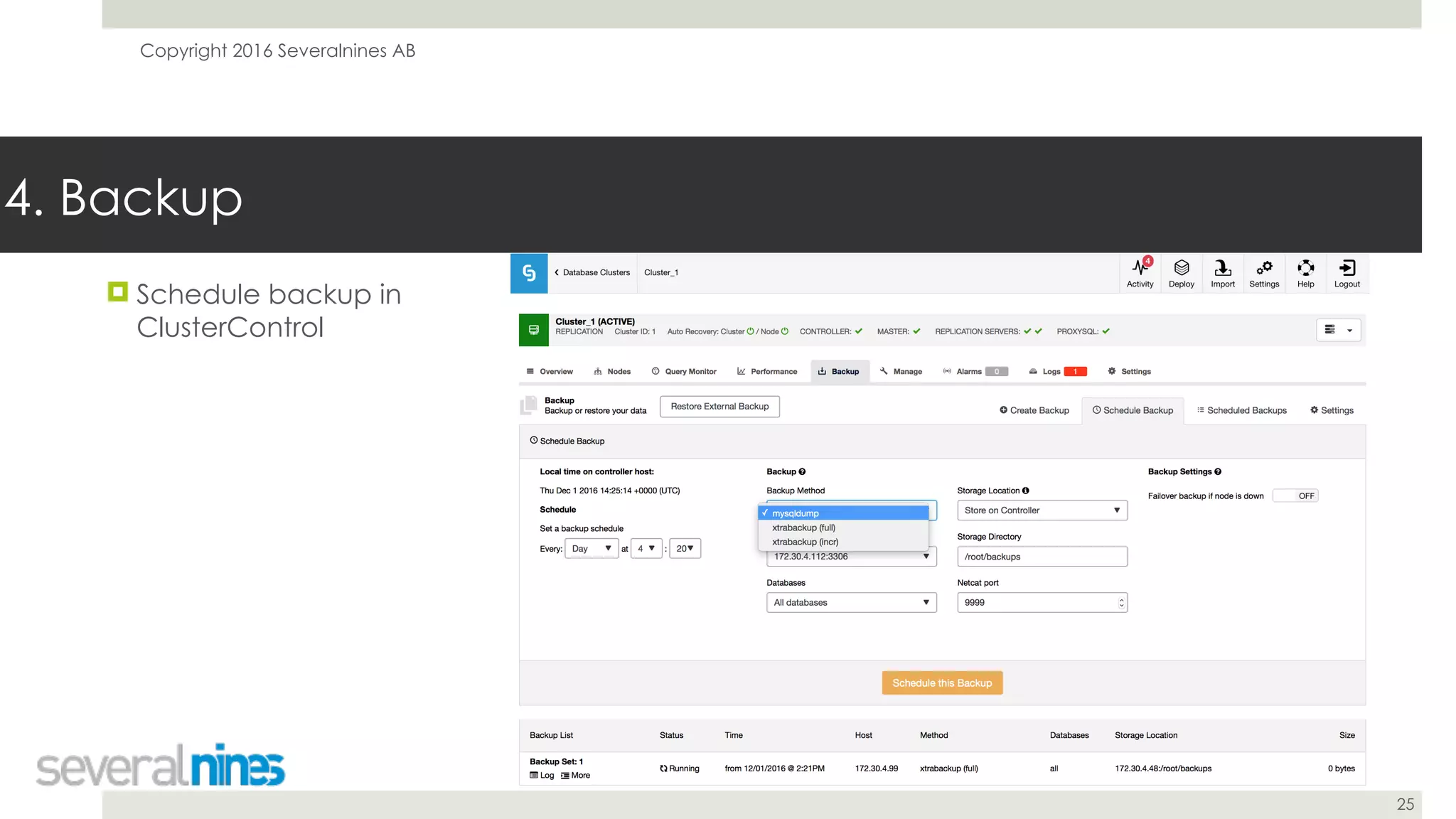

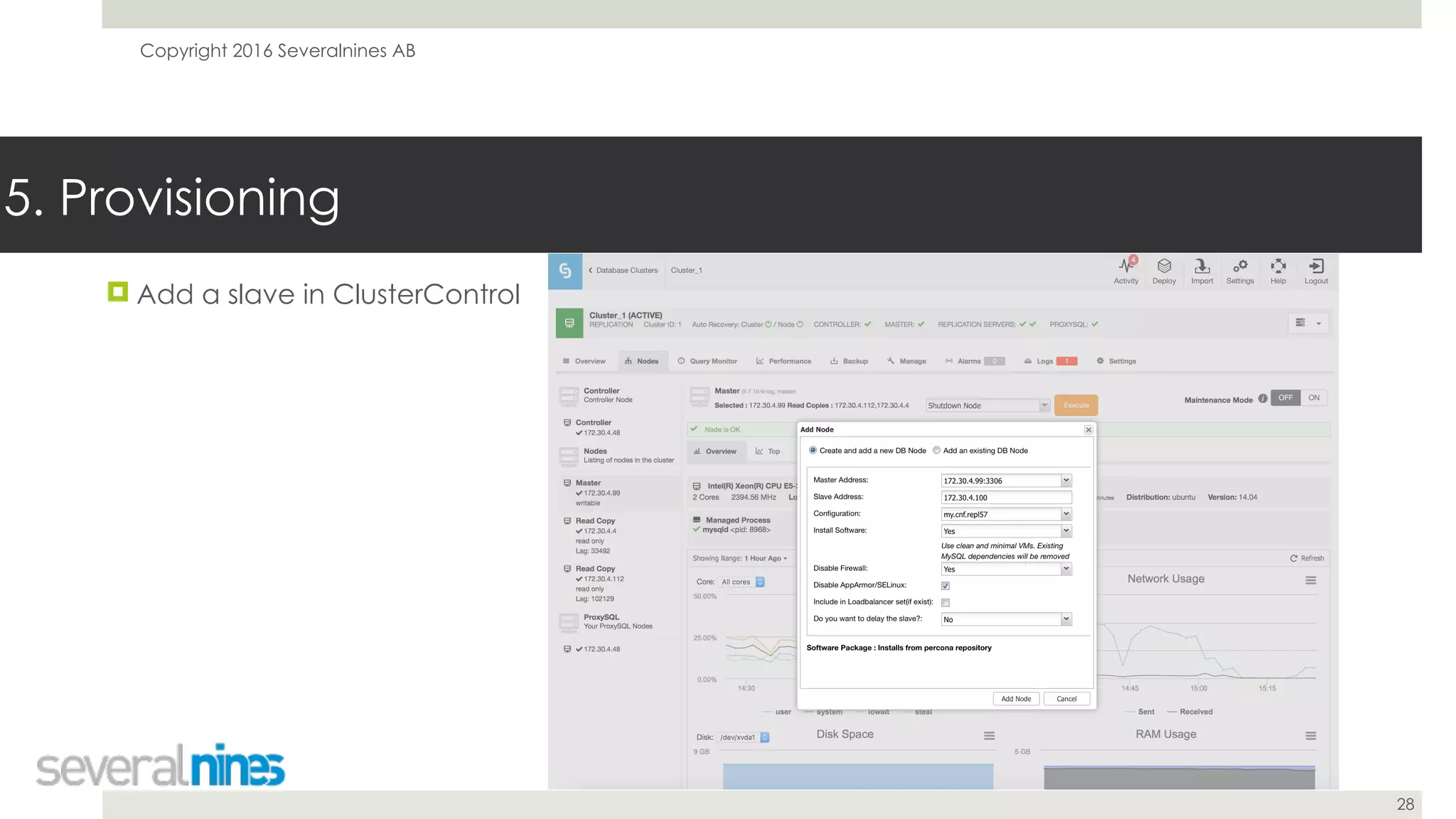

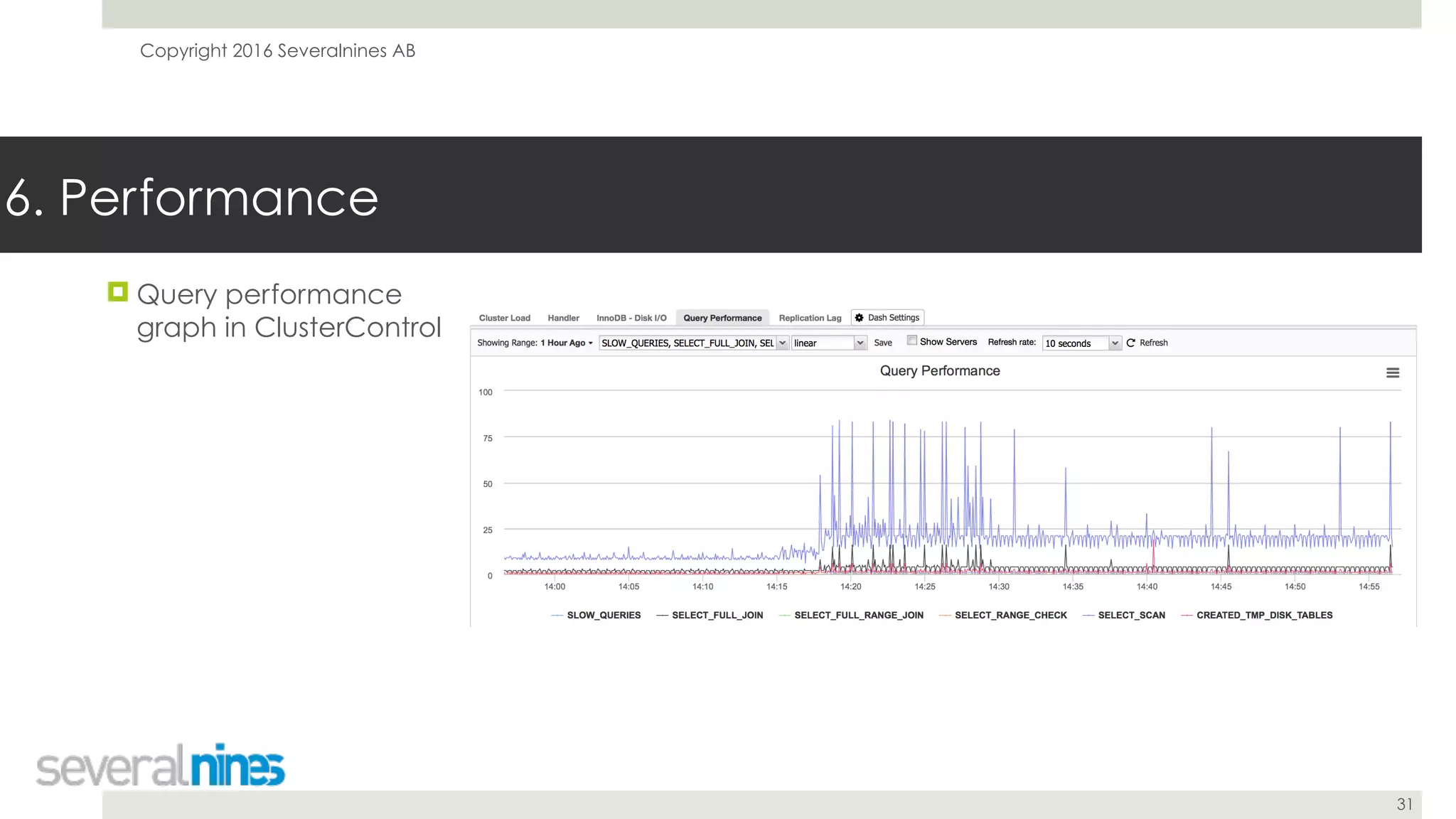
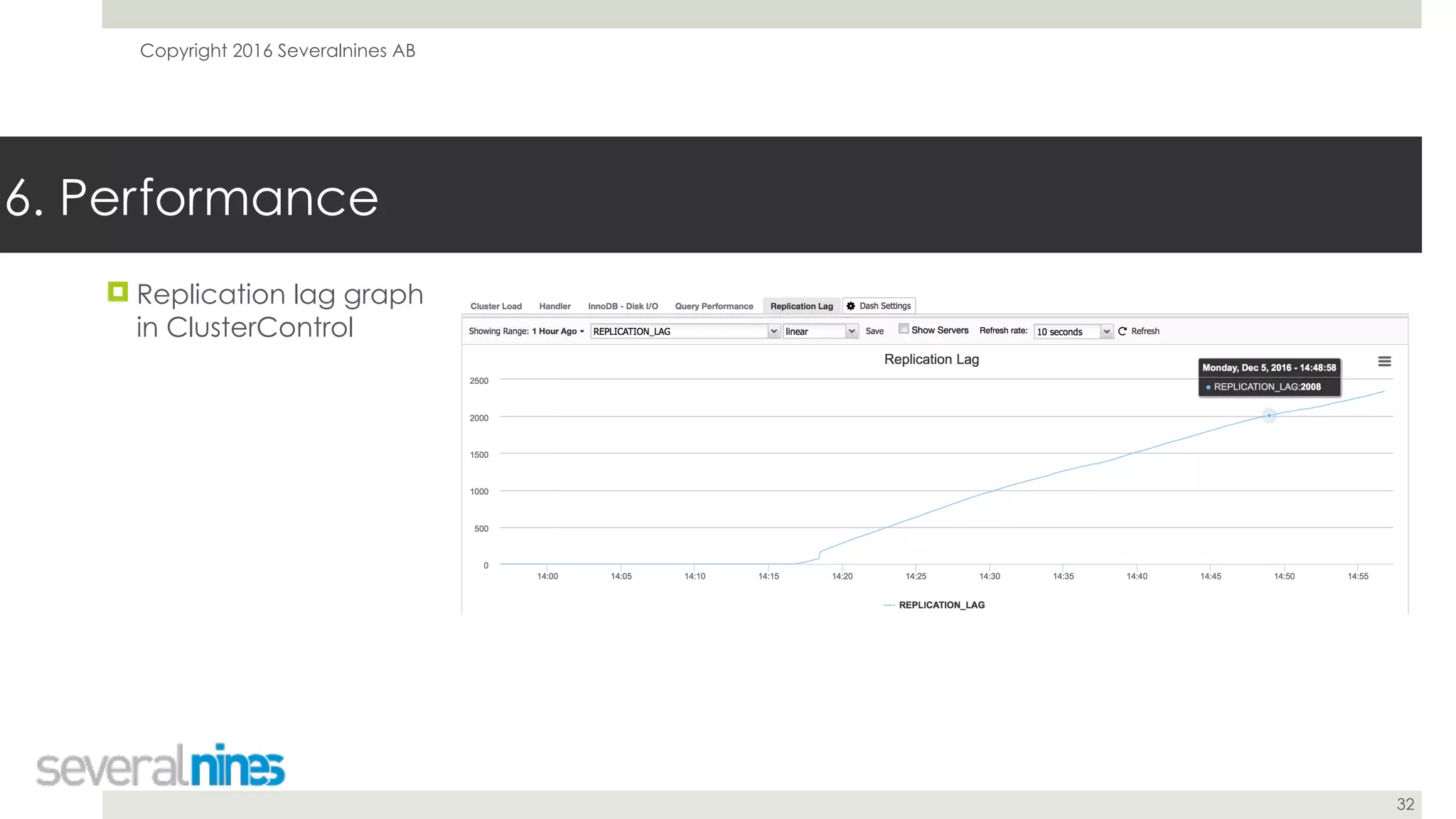

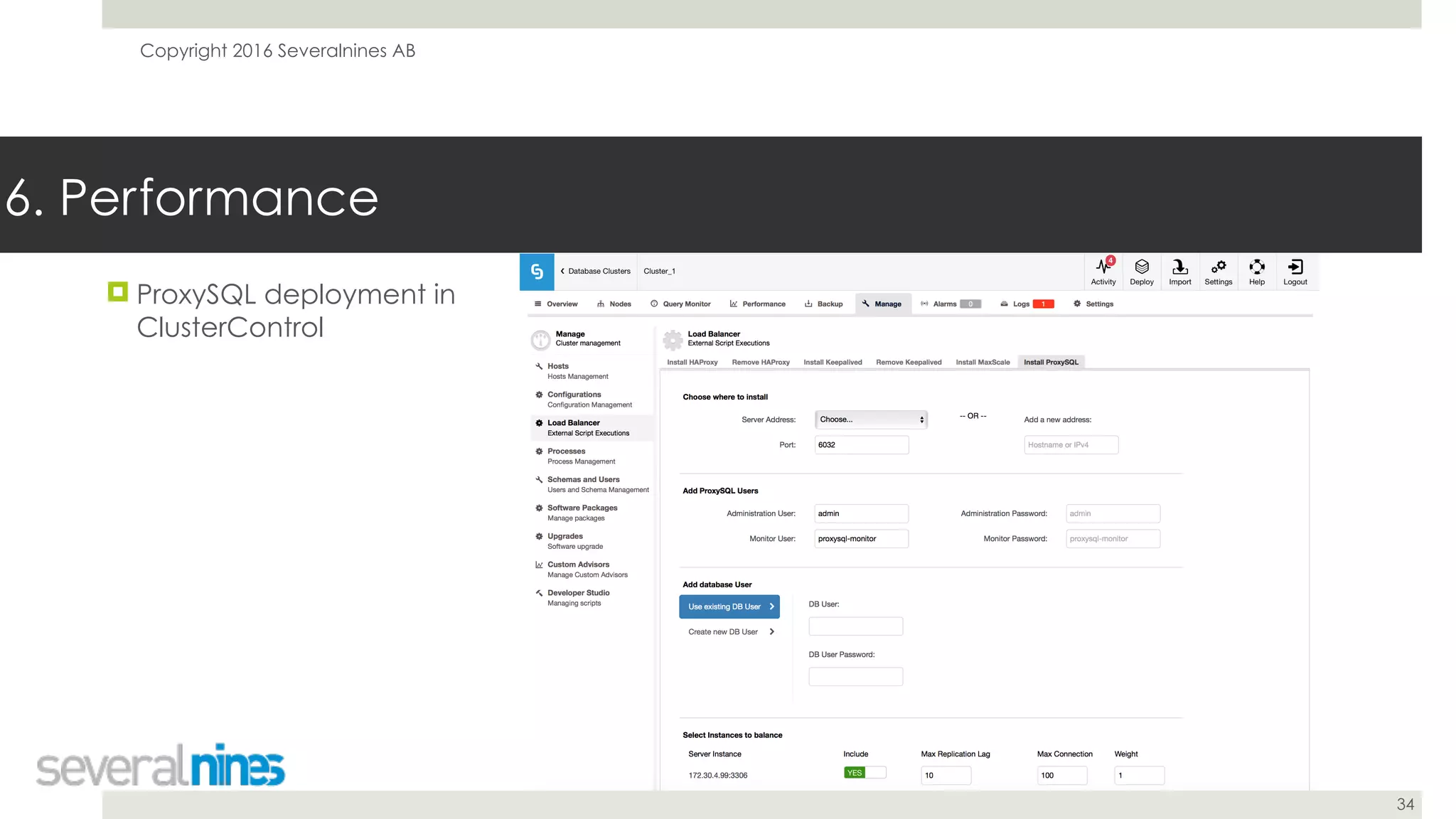









The document is a guide for successfully implementing MySQL replication, covering essential aspects such as sanity checks, operating system configuration, backup methods, performance optimization, and disaster recovery strategies. It emphasizes the importance of proper setup, monitoring, and management to minimize replication lag and maintain data consistency. Additionally, it provides insights into tools and best practices for database administrators to efficiently handle schema changes and optimize database performance.



























































































![Computer Networks 01[1 using all terms].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computernetworks011-251214040533-327dd9f8-thumbnail.jpg?width=640&height=640&fit=bounds)

