Downloaded 10 times



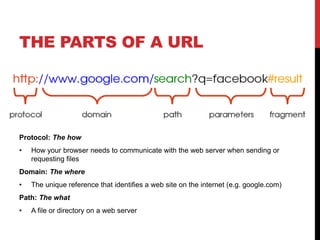

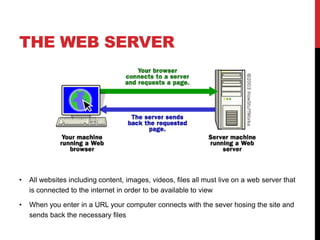












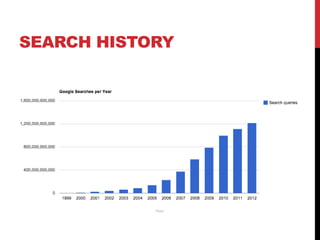


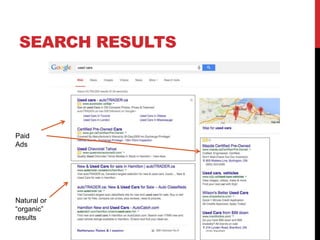



The document discusses the anatomy of a URL and its key components. It explains that a URL identifies network resources on the internet using a protocol, domain name, and path. The protocol specifies how the browser communicates with the web server, such as HTTP. The domain name identifies the website. The path refers to files or directories on the server. Web browsers use URLs to locate and access web pages by translating HTML code. Search engines also use URLs to index website content and return search results when users enter queries.































































