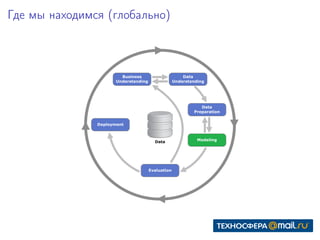
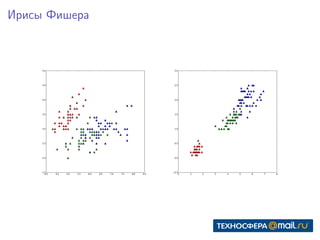
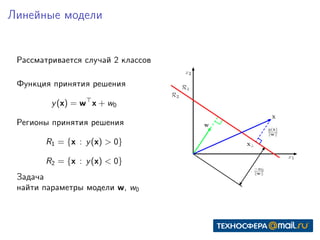
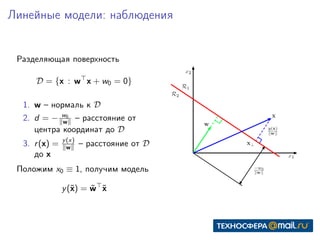
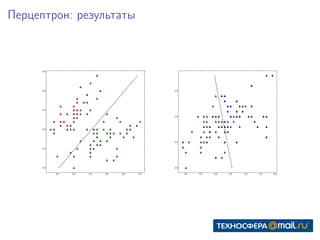
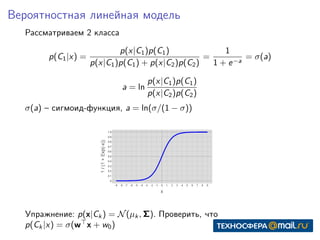
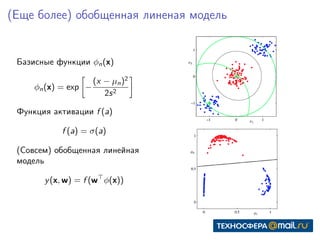
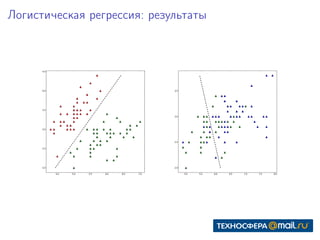
Документ представляет собой конспект занятия по линейным моделям в области data science. Он охватывает темы выбора модели, оптимизации параметров, классификации, а также различные подходы, такие как метод максимального правдоподобия и байесовский вывод. В конце приведены практические задания и ключевые даты для выполнения.