Downloaded 23 times











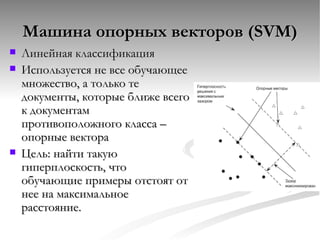



Документ содержит описание классификации и кластеризации документов, объясняя методы и подходы, такие как наивный баесовский подход, метод k ближайших соседей и машина опорных векторов. Классификация включает обучение с учителем и поиск разделяющих поверхностей для новых документов. Рассматриваются аспекты выбора признаков и сокращения пространства признаков для уменьшения вычислительной сложности.




























































