Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
NAVER D2
PDF, PPTX
3,933 views
제 5회 Lisp 세미나 - 클로저 개발팀을 위한 지속적인 통합
클로저 개발팀을 대상으로 하여 데이터베이스, 테스트, 배포 등의 지속적인 통합 설정 및 경험을 공유합니다.
Software
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 37
2
/ 37
3
/ 37
4
/ 37
5
/ 37
6
/ 37
7
/ 37
8
/ 37
9
/ 37
10
/ 37
11
/ 37
12
/ 37
13
/ 37
14
/ 37
15
/ 37
16
/ 37
17
/ 37
18
/ 37
19
/ 37
20
/ 37
21
/ 37
22
/ 37
23
/ 37
24
/ 37
25
/ 37
26
/ 37
27
/ 37
28
/ 37
29
/ 37
30
/ 37
31
/ 37
32
/ 37
33
/ 37
34
/ 37
35
/ 37
36
/ 37
37
/ 37
More Related Content
PDF
송창규, unity build로 빌드타임 반토막내기, NDC2010
by
devCAT Studio, NEXON
PPTX
[하코사세미나]미리보는 대규모 자바스크립트 어플리케이션 개발
by
정석 양
PPTX
Nodejs, PhantomJS, casperJs, YSlow, expressjs
by
기동 이
PPTX
Airflow를 이용한 데이터 Workflow 관리
by
YoungHeon (Roy) Kim
PDF
Node.js 시작하기
by
Huey Park
PDF
[오픈소스컨설팅] Docker를 활용한 Gitlab CI/CD 구성 테스트
by
Ji-Woong Choi
PDF
Python server-101
by
Huey Park
PDF
Node.js 현재와 미래
by
JeongHun Byeon
송창규, unity build로 빌드타임 반토막내기, NDC2010
by
devCAT Studio, NEXON
[하코사세미나]미리보는 대규모 자바스크립트 어플리케이션 개발
by
정석 양
Nodejs, PhantomJS, casperJs, YSlow, expressjs
by
기동 이
Airflow를 이용한 데이터 Workflow 관리
by
YoungHeon (Roy) Kim
Node.js 시작하기
by
Huey Park
[오픈소스컨설팅] Docker를 활용한 Gitlab CI/CD 구성 테스트
by
Ji-Woong Choi
Python server-101
by
Huey Park
Node.js 현재와 미래
by
JeongHun Byeon
What's hot
PDF
[1B4]안드로이드 동시성_프로그래밍
by
NAVER D2
PPTX
Leadweb Nodejs
by
근호 최
PDF
[1A4]자바스크립트 라이브러리 개발 운영 경험기
by
NAVER D2
PDF
[243]kaleido 노현걸
by
NAVER D2
PPTX
GraphQL overview
by
기동 이
PDF
GraphQL overview #2
by
기동 이
PPTX
What is the meteor?
by
Peter YoungSik Yun
PDF
도커(Docker) 메트릭스 & 로그 수집
by
Daegwon Kim
PDF
[H3 2012] 내컴에선 잘되던데? - vagrant로 서버와 동일한 개발환경 꾸미기
by
KTH, 케이티하이텔
PDF
[야생의 땅: 듀랑고] 지형 관리 완전 자동화 - 생생한 AWS와 Docker 체험기
by
Sumin Byeon
PDF
[244] 분산 환경에서 스트림과 배치 처리 통합 모델
by
NAVER D2
PPTX
이기종 멀티코어 기반의 Open cv 응용 사례 및 효율적인 어플리케이션 디자인
by
Seunghwa Song
PDF
옛날 웹 개발자가 잠깐 맛본 Vue.js 소개
by
beom kyun choi
PDF
Big query at GDG Korea Cloud meetup
by
Jude Kim
PDF
닷넷프레임워크에서 Redis 사용하기
by
흥배 최
PDF
Docker (Compose) 활용 - 개발 환경 구성하기
by
raccoony
PDF
Docker 기본 및 Docker Swarm을 활용한 분산 서버 관리 A부터 Z까지 [전체모드에서 봐주세요]
by
David Lee
PDF
[121]네이버 효과툰 구현 이야기
by
NAVER D2
PDF
20141229 dklee docker
by
DK Lee
PDF
Puppet과 자동화된 시스템 관리
by
Keon Ahn
[1B4]안드로이드 동시성_프로그래밍
by
NAVER D2
Leadweb Nodejs
by
근호 최
[1A4]자바스크립트 라이브러리 개발 운영 경험기
by
NAVER D2
[243]kaleido 노현걸
by
NAVER D2
GraphQL overview
by
기동 이
GraphQL overview #2
by
기동 이
What is the meteor?
by
Peter YoungSik Yun
도커(Docker) 메트릭스 & 로그 수집
by
Daegwon Kim
[H3 2012] 내컴에선 잘되던데? - vagrant로 서버와 동일한 개발환경 꾸미기
by
KTH, 케이티하이텔
[야생의 땅: 듀랑고] 지형 관리 완전 자동화 - 생생한 AWS와 Docker 체험기
by
Sumin Byeon
[244] 분산 환경에서 스트림과 배치 처리 통합 모델
by
NAVER D2
이기종 멀티코어 기반의 Open cv 응용 사례 및 효율적인 어플리케이션 디자인
by
Seunghwa Song
옛날 웹 개발자가 잠깐 맛본 Vue.js 소개
by
beom kyun choi
Big query at GDG Korea Cloud meetup
by
Jude Kim
닷넷프레임워크에서 Redis 사용하기
by
흥배 최
Docker (Compose) 활용 - 개발 환경 구성하기
by
raccoony
Docker 기본 및 Docker Swarm을 활용한 분산 서버 관리 A부터 Z까지 [전체모드에서 봐주세요]
by
David Lee
[121]네이버 효과툰 구현 이야기
by
NAVER D2
20141229 dklee docker
by
DK Lee
Puppet과 자동화된 시스템 관리
by
Keon Ahn
Viewers also liked
PDF
제 5회 Lisp 세미나 - Graphics Programming in Clojure
by
NAVER D2
PDF
core.logic (Clojure)
by
Seonho Kim
PDF
동시성 프로그래밍 하기 좋은 Clojure
by
Eunmin Kim
PDF
Re frame
by
Sang-Kyu Park
PDF
Dragon: A Distributed Object Storage at Yahoo! JAPAN (WebDB Forum 2017)
by
Yahoo!デベロッパーネットワーク
PDF
Dragon: A Distributed Object Storage at Yahoo! JAPAN (WebDB Forum 2017 / E...
by
Yahoo!デベロッパーネットワーク
PDF
Clojure Monad
by
Eunmin Kim
제 5회 Lisp 세미나 - Graphics Programming in Clojure
by
NAVER D2
core.logic (Clojure)
by
Seonho Kim
동시성 프로그래밍 하기 좋은 Clojure
by
Eunmin Kim
Re frame
by
Sang-Kyu Park
Dragon: A Distributed Object Storage at Yahoo! JAPAN (WebDB Forum 2017)
by
Yahoo!デベロッパーネットワーク
Dragon: A Distributed Object Storage at Yahoo! JAPAN (WebDB Forum 2017 / E...
by
Yahoo!デベロッパーネットワーク
Clojure Monad
by
Eunmin Kim
Similar to 제 5회 Lisp 세미나 - 클로저 개발팀을 위한 지속적인 통합
PDF
webservice scaling for newbie
by
DaeMyung Kang
PDF
Partner Story(Megazone): 금융사 실전 프로젝트 DeepDive
by
Elasticsearch
PPTX
Event Storming and Implementation Workshop
by
uEngine Solutions
PDF
니름: 쉬운 SOA 단위 테스트
by
효준 강
PDF
[pgday.Seoul 2022] 서비스개편시 PostgreSQL 도입기 - 진소린 & 김태정
by
PgDay.Seoul
PDF
The platform 2011
by
NAVER D2
PDF
스마일게이트 서버개발캠프 - HGHSS - 합격하소서
by
ServerDevCamp
PDF
MongoDB 하루만에 끝내기
by
Seongkuk Park
PPTX
Continuous Integration
by
Donghyun Seo
PPTX
elasticsearch_적용 및 활용_정리
by
Junyi Song
PDF
DDD로 복잡함 다루기
by
beom kyun choi
PPTX
엘라스틱서치 이해하기 20160613
by
Yong Joon Moon
PDF
Scalable webservice
by
DaeMyung Kang
PPTX
Lw4.2
by
준호 정
PDF
[215]네이버콘텐츠통계서비스소개 김기영
by
NAVER D2
PPTX
Team project(for fullstack)
by
형석 장
PPTX
Team project(for fullstack)
by
형석 장
PDF
[D2] java 애플리케이션 트러블 슈팅 사례 & pinpoint
by
NAVER D2
PPTX
[211] HBase 기반 검색 데이터 저장소 (공개용)
by
NAVER D2
PDF
Custom DevOps Monitoring System in MelOn (with InfluxDB + Telegraf + Grafana)
by
Seungmin Yu
webservice scaling for newbie
by
DaeMyung Kang
Partner Story(Megazone): 금융사 실전 프로젝트 DeepDive
by
Elasticsearch
Event Storming and Implementation Workshop
by
uEngine Solutions
니름: 쉬운 SOA 단위 테스트
by
효준 강
[pgday.Seoul 2022] 서비스개편시 PostgreSQL 도입기 - 진소린 & 김태정
by
PgDay.Seoul
The platform 2011
by
NAVER D2
스마일게이트 서버개발캠프 - HGHSS - 합격하소서
by
ServerDevCamp
MongoDB 하루만에 끝내기
by
Seongkuk Park
Continuous Integration
by
Donghyun Seo
elasticsearch_적용 및 활용_정리
by
Junyi Song
DDD로 복잡함 다루기
by
beom kyun choi
엘라스틱서치 이해하기 20160613
by
Yong Joon Moon
Scalable webservice
by
DaeMyung Kang
Lw4.2
by
준호 정
[215]네이버콘텐츠통계서비스소개 김기영
by
NAVER D2
Team project(for fullstack)
by
형석 장
Team project(for fullstack)
by
형석 장
[D2] java 애플리케이션 트러블 슈팅 사례 & pinpoint
by
NAVER D2
[211] HBase 기반 검색 데이터 저장소 (공개용)
by
NAVER D2
Custom DevOps Monitoring System in MelOn (with InfluxDB + Telegraf + Grafana)
by
Seungmin Yu
More from NAVER D2
PDF
[211] 인공지능이 인공지능 챗봇을 만든다
by
NAVER D2
PDF
[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...
by
NAVER D2
PDF
[215] Druid로 쉽고 빠르게 데이터 분석하기
by
NAVER D2
PDF
[245]Papago Internals: 모델분석과 응용기술 개발
by
NAVER D2
PDF
[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈
by
NAVER D2
PDF
[235]Wikipedia-scale Q&A
by
NAVER D2
PDF
[244]로봇이 현실 세계에 대해 학습하도록 만들기
by
NAVER D2
PDF
[243] Deep Learning to help student’s Deep Learning
by
NAVER D2
PDF
[234]Fast & Accurate Data Annotation Pipeline for AI applications
by
NAVER D2
PDF
Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing
by
NAVER D2
PDF
[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지
by
NAVER D2
PDF
[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기
by
NAVER D2
PDF
[224]네이버 검색과 개인화
by
NAVER D2
PDF
[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)
by
NAVER D2
PDF
[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기
by
NAVER D2
PDF
[213] Fashion Visual Search
by
NAVER D2
PDF
[232] TensorRT를 활용한 딥러닝 Inference 최적화
by
NAVER D2
PDF
[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지
by
NAVER D2
PDF
[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터
by
NAVER D2
PDF
[223]기계독해 QA: 검색인가, NLP인가?
by
NAVER D2
[211] 인공지능이 인공지능 챗봇을 만든다
by
NAVER D2
[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...
by
NAVER D2
[215] Druid로 쉽고 빠르게 데이터 분석하기
by
NAVER D2
[245]Papago Internals: 모델분석과 응용기술 개발
by
NAVER D2
[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈
by
NAVER D2
[235]Wikipedia-scale Q&A
by
NAVER D2
[244]로봇이 현실 세계에 대해 학습하도록 만들기
by
NAVER D2
[243] Deep Learning to help student’s Deep Learning
by
NAVER D2
[234]Fast & Accurate Data Annotation Pipeline for AI applications
by
NAVER D2
Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing
by
NAVER D2
[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지
by
NAVER D2
[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기
by
NAVER D2
[224]네이버 검색과 개인화
by
NAVER D2
[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)
by
NAVER D2
[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기
by
NAVER D2
[213] Fashion Visual Search
by
NAVER D2
[232] TensorRT를 활용한 딥러닝 Inference 최적화
by
NAVER D2
[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지
by
NAVER D2
[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터
by
NAVER D2
[223]기계독해 QA: 검색인가, NLP인가?
by
NAVER D2
제 5회 Lisp 세미나 - 클로저 개발팀을 위한 지속적인 통합
1.
클로저 개발팀을 위한 지속적인 통합 김만명 1 / 37
2.
소개 https://youtu.be/wiRmVsTarAI?t=3m22s https://github.com/infokraft 2 / 37
3.
무엇을 발표할까? CI(Continuous Integration; 지속적인 통합) 서비스 도입 과정과 결과 클로저 프로젝트 경험 3 / 37
4.
최근 프로젝트 https://github.com/infokraft/toxfree/graphs/commit-activity 서버: Ring, Jetty, Compojure, MySQL 클라이언트: Reagent, re-frame, Datatables 플랫폼: Github, AWS 4 / 37
5.
CI 도입 이유 배포가 복잡 한 사람이 배포를 도맡는 현상 버그 때문에 개발이 지연되는 경험 5 / 37
6.
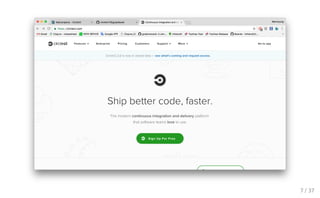
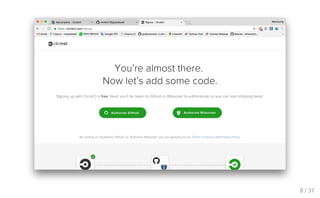
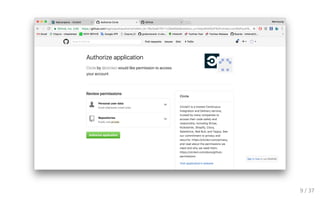
CI 선택 Github에서 많이 사용하는 CI 서비스 Travis CI : https://travis-ci.com/plans Circle CI : https://circleci.com/pricing/ 6 / 37
7.
7 / 37
8.
8 / 37
9.
9 / 37
10.
10 / 37
11.
11 / 37
12.
12 / 37
13.
13 / 37
14.
알림 1. 이메일 2. 채팅 지원 서비스 사용예 3. 상태 배지 사용예 4. 웹훅(Webhook) 14 / 37
15.
CircleCI 설정 수정 circle.yml https://circleci.com/docs/manually/ 15 / 37
16.
데이터베이스 circle.yml database: override: - mysql -u
root -vvf < create-test-db.sql create-test-db.sql CREATE DATABASE `toxfree_test` character set utf8; 16 / 37
17.
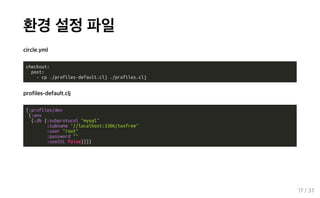
환경 설정 파일 circle.yml checkout: post: - cp ./profiles-default.clj
./profiles.clj profiles-default.clj {:profiles/dev {:env {:db {:subprotocol "mysql" :subname "//localhost:3306/toxfree" :user "root" :password "" :useSSL false}}}} 17 / 37
18.
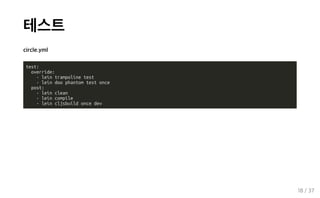
테스트 circle.yml test: override: - lein trampoline
test - lein doo phantom test once post: - lein clean - lein compile - lein cljsbuild once dev 18 / 37
19.
테스트 지속적인 통합에서 테스트의 역할 서버 HTTP 요청 -->
--> --> 핸들러 쿼리단 DB HTTP 응답 <-- <-- <-- 단위 테스트: 핸들러 테스트, DB 테스트 우리가 테스트하고 싶은 것: 어떤 요청을 보내면 어떤 응답이 오나? 19 / 37
20.
테스트 지속적인 통합에서 테스트의 역할 서버 HTTP 요청 -->
--> --> 핸들러 쿼리단 DB HTTP 응답 <-- <-- <-- 단위 테스트: 핸들러 테스트, DB 테스트 통합 테스트: HTTP 요청과 응답을 이용해 서버단 테스트 20 / 37
21.
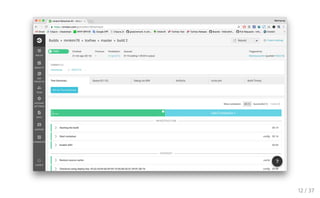
routing_test.clj (deftest depts-routing (with-test-db (let [{dept-id
"dept-id" :as create-res} (request :post "/dept/create" {"dept" "연구1실"})] (testing "/dept/create" (is (= {"dept-id" dept-id, "dept" "연구1실"} create-res))) (testing "/depts/read" (is (= [["dept-id" "dept"] [dept-id "연구1실"]] (request :get "/depts/read")))) (testing "/dept/update/:dept-id" (is (= {"dept-id" dept-id, "dept" "연구6실"} (request :post (str "/dept/update/" dept-id) {"dept" "연구6실"})))) (testing "update 확인" (is (= [["dept-id" "dept"] [dept-id "연구6실"]] (request :get "/depts/read")))) (testing "/dept/delete/:dept-id" (is (= dept-id (request :delete (str "/dept/delete/" dept-id))))) (testing "delete 확인" (is (= [["dept-id" "dept"]] (request :get "/depts/read"))))))) 21 / 37
22.
routing_test.clj (deftest depts-routing (with-test-db (let [{dept-id
"dept-id" :as create-res} (request :post "/dept/create" {"dept" "연구1실"})] (testing "/dept/create" (is (= {"dept-id" dept-id, "dept" "연구1실"} create-res))) (testing "/depts/read" (is (= [["dept-id" "dept"] [dept-id "연구1실"]] (request :get "/depts/read")))) (testing "/dept/update/:dept-id" (is (= {"dept-id" dept-id, "dept" "연구6실"} (request :post (str "/dept/update/" dept-id) {"dept" "연구6실"})))) (testing "update 확인" (is (= [["dept-id" "dept"] [dept-id "연구6실"]] (request :get "/depts/read")))) (testing "/dept/delete/:dept-id" (is (= dept-id (request :delete (str "/dept/delete/" dept-id))))) (testing "delete 확인" (is (= [["dept-id" "dept"]] (request :get "/depts/read"))))))) 테스트 DB 를 대상으로 실행 한 테스트가 끝나면 테스트 DB 원상복구 22 / 37
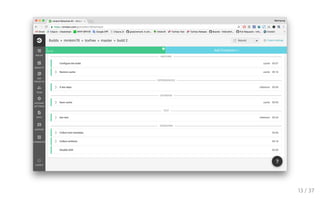
23.
routing_test.clj (deftest depts-routing (with-test-db (let [{dept-id
"dept-id" :as create-res} (request :post "/dept/create" {"dept" "연구1실"})] (testing "/dept/create" (is (= {"dept-id" dept-id, "dept" "연구1실"} create-res))) (testing "/depts/read" (is (= [["dept-id" "dept"] [dept-id "연구1실"]] (request :get "/depts/read")))) (testing "/dept/update/:dept-id" (is (= {"dept-id" dept-id, "dept" "연구6실"} (request :post (str "/dept/update/" dept-id) {"dept" "연구6실"})))) (testing "update 확인" (is (= [["dept-id" "dept"] [dept-id "연구6실"]] (request :get "/depts/read")))) (testing "/dept/delete/:dept-id" (is (= dept-id (request :delete (str "/dept/delete/" dept-id))))) (testing "delete 확인" (is (= [["dept-id" "dept"]] (request :get "/depts/read"))))))) (defmacro with-test-db [& body] `(jdbc/with-db-transaction [t-conn# test-db*] (jdbc/db-set-rollback-only! t-conn#) (with-redefs [db* t-conn#] ~@body))) 23 / 37
24.
routing_test.clj (deftest depts-routing (with-test-db (let [{dept-id
"dept-id" :as create-res} (request :post "/dept/create" {"dept" "연구1실"})] (testing "/dept/create" (is (= {"dept-id" dept-id, "dept" "연구1실"} create-res))) (testing "/depts/read" (is (= [["dept-id" "dept"] [dept-id "연구1실"]] (request :get "/depts/read")))) (testing "/dept/update/:dept-id" (is (= {"dept-id" dept-id, "dept" "연구6실"} (request :post (str "/dept/update/" dept-id) {"dept" "연구6실"})))) (testing "update 확인" (is (= [["dept-id" "dept"] [dept-id "연구6실"]] (request :get "/depts/read")))) (testing "/dept/delete/:dept-id" (is (= dept-id (request :delete (str "/dept/delete/" dept-id))))) (testing "delete 확인" (is (= [["dept-id" "dept"]] (request :get "/depts/read"))))))) (use-fixtures :once (fn [f] (init/migrate test-db*) (f))) 24 / 37
25.
routing_test.clj (deftest depts-routing (with-test-db (let [{dept-id
"dept-id" :as create-res} (request :post "/dept/create" {"dept" "연구1실"})] (testing "/dept/create" (is (= {"dept-id" dept-id, "dept" "연구1실"} create-res))) (testing "/depts/read" (is (= [["dept-id" "dept"] [dept-id "연구1실"]] (request :get "/depts/read")))) (testing "/dept/update/:dept-id" (is (= {"dept-id" dept-id, "dept" "연구6실"} (request :post (str "/dept/update/" dept-id) {"dept" "연구6실"})))) (testing "update 확인" (is (= [["dept-id" "dept"] [dept-id "연구6실"]] (request :get "/depts/read")))) (testing "/dept/delete/:dept-id" (is (= dept-id (request :delete (str "/dept/delete/" dept-id))))) (testing "delete 확인" (is (= [["dept-id" "dept"]] (request :get "/depts/read"))))))) 19개의 테스트, 94개의 단정문 25 / 37
26.
routing_test.clj (deftest depts-routing (with-test-db (let [{dept-id
"dept-id" :as create-res} (request :post "/dept/create" {"dept" "연구1실"})] (testing "/dept/create" (is (= {"dept-id" dept-id, "dept" "연구1실"} create-res))) (testing "/depts/read" (is (= [["dept-id" "dept"] [dept-id "연구1실"]] (request :get "/depts/read")))) (testing "/dept/update/:dept-id" (is (= {"dept-id" dept-id, "dept" "연구6실"} (request :post (str "/dept/update/" dept-id) {"dept" "연구6실"})))) (testing "update 확인" (is (= [["dept-id" "dept"] [dept-id "연구6실"]] (request :get "/depts/read")))) (testing "/dept/delete/:dept-id" (is (= dept-id (request :delete (str "/dept/delete/" dept-id))))) (testing "delete 확인" (is (= [["dept-id" "dept"]] (request :get "/depts/read"))))))) 서버 수정할 때 안정감 최신 상태의 문서 26 / 37
27.
테스트 클라이언트 --> --> -->
HTTP 요청 브라우저 DOM 처리단 <-- <-- <-- HTTP 응답 27 / 37
28.
테스트 클라이언트 --> --> -->
HTTP 요청 브라우저 DOM 처리단 <-- <-- <-- HTTP 응답 단위 테스트: 처리단에서 변환로직 10개의 테스트, 49개의 단정문 28 / 37
29.
테스트 클라이언트 --> --> -->
HTTP 요청 브라우저 DOM 처리단 <-- <-- <-- HTTP 응답 클라이언트 수정시 안정감 29 / 37
30.
배포 개발 절차 Git 협업 방법 https://github.com/infokraft/toxfree/pull/138 https://github.com/infokraft/toxfree/pull/261 마스터 브랜치에 머지되면 테스트 서버에 바로 배포해서 확인 30 / 37
31.
배포 다양한 배포 방법 https://circleci.com/docs/ 31 / 37
32.
배포 SSH 키 세팅 32 / 37
33.
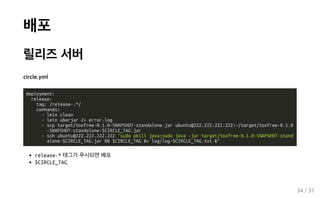
배포 테스트 서버 circle.yml deployment: master: branch: master commands: - lein
clean - lein uberjar 2> error.log - scp target/toxfree-0.1.0-SNAPSHOT-standalone.jar ubuntu@111.111.111.111:~/target - ssh ubuntu@111.111.111.111 "sudo pkill java;sudo java -jar target/toxfree-0.1.0-SNAPSHOT-stand alone.jar 80 &> log/log-$CIRCLE_BUILD_NUM.txt &" 마스터 브랜치에 커밋이 되면 배포 $CIRCLE_BUILD_NUM 테스트 서버에서 확인 33 / 37
34.
배포 릴리즈 서버 circle.yml deployment: release: tag: /release-.*/ commands: - lein
clean - lein uberjar 2> error.log - scp target/toxfree-0.1.0-SNAPSHOT-standalone.jar ubuntu@222.222.222.222:~/target/toxfree-0.1.0 -SNAPSHOT-standalone-$CIRCLE_TAG.jar - ssh ubuntu@222.222.222.222 "sudo pkill java;sudo java -jar target/toxfree-0.1.0-SNAPSHOT-stand alone-$CIRCLE_TAG.jar 80 $CIRCLE_TAG &> log/log-$CIRCLE_TAG.txt &" release-* 태그가 푸시되면 배포 $CIRCLE_TAG 34 / 37
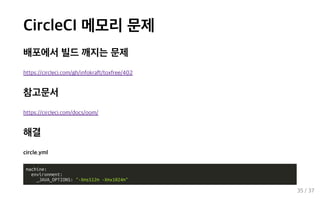
35.
CircleCI 메모리 문제 배포에서 빌드 깨지는 문제 https://circleci.com/gh/infokraft/toxfree/402 참고문서 https://circleci.com/docs/oom/ 해결 circle.yml machine: environment: _JAVA_OPTIONS: "-Xms512m -Xmx1024m" 35 / 37
36.
느낀점 쉬운 배포 오류를 빨리 발견 엔드 투 엔드(End to End) 테스트 기대: 참고 팀을 위한 툴? 36 / 37
37.
감사합니다 37 / 37
Download











![routing_test.clj
(deftest depts-routing
(with-test-db
(let [{dept-id "dept-id" :as create-res}
(request :post "/dept/create" {"dept" "연구1실"})]
(testing "/dept/create"
(is (= {"dept-id" dept-id, "dept" "연구1실"}
create-res)))
(testing "/depts/read"
(is (= [["dept-id" "dept"] [dept-id "연구1실"]]
(request :get "/depts/read"))))
(testing "/dept/update/:dept-id"
(is (= {"dept-id" dept-id, "dept" "연구6실"}
(request :post (str "/dept/update/" dept-id) {"dept" "연구6실"}))))
(testing "update 확인"
(is (= [["dept-id" "dept"] [dept-id "연구6실"]]
(request :get "/depts/read"))))
(testing "/dept/delete/:dept-id"
(is (= dept-id
(request :delete (str "/dept/delete/" dept-id)))))
(testing "delete 확인"
(is (= [["dept-id" "dept"]]
(request :get "/depts/read")))))))
21 / 37](https://image.slidesharecdn.com/120161112-1st-session-clojure-ci-161129122546/85/5-Lisp-21-320.jpg)
![routing_test.clj
(deftest depts-routing
(with-test-db
(let [{dept-id "dept-id" :as create-res}
(request :post "/dept/create" {"dept" "연구1실"})]
(testing "/dept/create"
(is (= {"dept-id" dept-id, "dept" "연구1실"}
create-res)))
(testing "/depts/read"
(is (= [["dept-id" "dept"] [dept-id "연구1실"]]
(request :get "/depts/read"))))
(testing "/dept/update/:dept-id"
(is (= {"dept-id" dept-id, "dept" "연구6실"}
(request :post (str "/dept/update/" dept-id) {"dept" "연구6실"}))))
(testing "update 확인"
(is (= [["dept-id" "dept"] [dept-id "연구6실"]]
(request :get "/depts/read"))))
(testing "/dept/delete/:dept-id"
(is (= dept-id
(request :delete (str "/dept/delete/" dept-id)))))
(testing "delete 확인"
(is (= [["dept-id" "dept"]]
(request :get "/depts/read")))))))
테스트 DB 를 대상으로 실행
한 테스트가 끝나면 테스트 DB 원상복구
22 / 37](https://image.slidesharecdn.com/120161112-1st-session-clojure-ci-161129122546/85/5-Lisp-22-320.jpg)
![routing_test.clj
(deftest depts-routing
(with-test-db
(let [{dept-id "dept-id" :as create-res}
(request :post "/dept/create" {"dept" "연구1실"})]
(testing "/dept/create"
(is (= {"dept-id" dept-id, "dept" "연구1실"}
create-res)))
(testing "/depts/read"
(is (= [["dept-id" "dept"] [dept-id "연구1실"]]
(request :get "/depts/read"))))
(testing "/dept/update/:dept-id"
(is (= {"dept-id" dept-id, "dept" "연구6실"}
(request :post (str "/dept/update/" dept-id) {"dept" "연구6실"}))))
(testing "update 확인"
(is (= [["dept-id" "dept"] [dept-id "연구6실"]]
(request :get "/depts/read"))))
(testing "/dept/delete/:dept-id"
(is (= dept-id
(request :delete (str "/dept/delete/" dept-id)))))
(testing "delete 확인"
(is (= [["dept-id" "dept"]]
(request :get "/depts/read")))))))
(defmacro with-test-db [& body]
`(jdbc/with-db-transaction [t-conn# test-db*]
(jdbc/db-set-rollback-only! t-conn#)
(with-redefs [db* t-conn#]
~@body)))
23 / 37](https://image.slidesharecdn.com/120161112-1st-session-clojure-ci-161129122546/85/5-Lisp-23-320.jpg)
![routing_test.clj
(deftest depts-routing
(with-test-db
(let [{dept-id "dept-id" :as create-res}
(request :post "/dept/create" {"dept" "연구1실"})]
(testing "/dept/create"
(is (= {"dept-id" dept-id, "dept" "연구1실"}
create-res)))
(testing "/depts/read"
(is (= [["dept-id" "dept"] [dept-id "연구1실"]]
(request :get "/depts/read"))))
(testing "/dept/update/:dept-id"
(is (= {"dept-id" dept-id, "dept" "연구6실"}
(request :post (str "/dept/update/" dept-id) {"dept" "연구6실"}))))
(testing "update 확인"
(is (= [["dept-id" "dept"] [dept-id "연구6실"]]
(request :get "/depts/read"))))
(testing "/dept/delete/:dept-id"
(is (= dept-id
(request :delete (str "/dept/delete/" dept-id)))))
(testing "delete 확인"
(is (= [["dept-id" "dept"]]
(request :get "/depts/read")))))))
(use-fixtures
:once
(fn [f]
(init/migrate test-db*)
(f)))
24 / 37](https://image.slidesharecdn.com/120161112-1st-session-clojure-ci-161129122546/85/5-Lisp-24-320.jpg)
![routing_test.clj
(deftest depts-routing
(with-test-db
(let [{dept-id "dept-id" :as create-res}
(request :post "/dept/create" {"dept" "연구1실"})]
(testing "/dept/create"
(is (= {"dept-id" dept-id, "dept" "연구1실"}
create-res)))
(testing "/depts/read"
(is (= [["dept-id" "dept"] [dept-id "연구1실"]]
(request :get "/depts/read"))))
(testing "/dept/update/:dept-id"
(is (= {"dept-id" dept-id, "dept" "연구6실"}
(request :post (str "/dept/update/" dept-id) {"dept" "연구6실"}))))
(testing "update 확인"
(is (= [["dept-id" "dept"] [dept-id "연구6실"]]
(request :get "/depts/read"))))
(testing "/dept/delete/:dept-id"
(is (= dept-id
(request :delete (str "/dept/delete/" dept-id)))))
(testing "delete 확인"
(is (= [["dept-id" "dept"]]
(request :get "/depts/read")))))))
19개의 테스트, 94개의 단정문
25 / 37](https://image.slidesharecdn.com/120161112-1st-session-clojure-ci-161129122546/85/5-Lisp-25-320.jpg)
![routing_test.clj
(deftest depts-routing
(with-test-db
(let [{dept-id "dept-id" :as create-res}
(request :post "/dept/create" {"dept" "연구1실"})]
(testing "/dept/create"
(is (= {"dept-id" dept-id, "dept" "연구1실"}
create-res)))
(testing "/depts/read"
(is (= [["dept-id" "dept"] [dept-id "연구1실"]]
(request :get "/depts/read"))))
(testing "/dept/update/:dept-id"
(is (= {"dept-id" dept-id, "dept" "연구6실"}
(request :post (str "/dept/update/" dept-id) {"dept" "연구6실"}))))
(testing "update 확인"
(is (= [["dept-id" "dept"] [dept-id "연구6실"]]
(request :get "/depts/read"))))
(testing "/dept/delete/:dept-id"
(is (= dept-id
(request :delete (str "/dept/delete/" dept-id)))))
(testing "delete 확인"
(is (= [["dept-id" "dept"]]
(request :get "/depts/read")))))))
서버 수정할 때 안정감
최신 상태의 문서
26 / 37](https://image.slidesharecdn.com/120161112-1st-session-clojure-ci-161129122546/85/5-Lisp-26-320.jpg)








![[하코사세미나]미리보는 대규모 자바스크립트 어플리케이션 개발](https://cdn.slidesharecdn.com/ss_thumbnails/hacosakimsuho-151208014839-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[오픈소스컨설팅] Docker를 활용한 Gitlab CI/CD 구성 테스트](https://cdn.slidesharecdn.com/ss_thumbnails/dockergitlabci-cd-180103202327-thumbnail.jpg?width=640&height=640&fit=bounds)


![[1B4]안드로이드 동시성_프로그래밍](https://cdn.slidesharecdn.com/ss_thumbnails/1b4-140928080341-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[1A4]자바스크립트 라이브러리 개발 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/1a4-140928080702-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243]kaleido 노현걸](https://cdn.slidesharecdn.com/ss_thumbnails/243kaleido-161025011559-thumbnail.jpg?width=640&height=640&fit=bounds)




![[H3 2012] 내컴에선 잘되던데? - vagrant로 서버와 동일한 개발환경 꾸미기](https://cdn.slidesharecdn.com/ss_thumbnails/c6-vagrantshare-121107074434-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[야생의 땅: 듀랑고] 지형 관리 완전 자동화 - 생생한 AWS와 Docker 체험기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2016-160426115105-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244] 분산 환경에서 스트림과 배치 처리 통합 모델](https://cdn.slidesharecdn.com/ss_thumbnails/244-150915025618-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





![Docker 기본 및 Docker Swarm을 활용한 분산 서버 관리 A부터 Z까지 [전체모드에서 봐주세요]](https://cdn.slidesharecdn.com/ss_thumbnails/dockerandswarmmode-181009120848-thumbnail.jpg?width=640&height=640&fit=bounds)
![[121]네이버 효과툰 구현 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/121-150914011346-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)













![[pgday.Seoul 2022] 서비스개편시 PostgreSQL 도입기 - 진소린 & 김태정](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql-221121085744-f0fb1a8a-thumbnail.jpg?width=640&height=640&fit=bounds)









![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)


![[D2] java 애플리케이션 트러블 슈팅 사례 & pinpoint](https://cdn.slidesharecdn.com/ss_thumbnails/d2javapinpoint-150522091509-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)

![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)