Downloaded 17 times











![Spark configuration 변경 방법
Spark configuration을 변경하기 위한 방법 여러가지가 있으나 각각은 config
값을 적용하는 시점이 달라 1번부터 우선순위가 가장 높게 반영된다.
1. SparkConf의 Set 함수를 이용하여 Runtime에서 설정 값을 변경한다.
2. spark-submit을 통해 설정값을 전달한다.
3. conf/spark-defaults.conf 파일을 직접 수정한다.
conf = spark.sparkContext._conf
.setAll([('spark.executor.memory', '4g'), ('spark.executor.cores','4')),('spark.driver.memory','4g’)])
spark.sparkContext.stop()
spark = SparkSession.builder.config(conf=conf).getOrCreate()
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster
--executor-memory 20G --num-executors 50
spark.executor.memory 18971M
spark.executor.cores 4
spark.yarn.executor.memoryOverheadFactor 0.1875](https://image.slidesharecdn.com/track5session3sparkworkloadexecutionoptimizationplanbasedonemrplatform-200821062610/75/EMR-Spark-AWS-AWS-Summit-Online-Korea-2020-21-2048.jpg)































![Docker를 이용한 EMR 클러스터 구성
다음과 같이 container-executor.json 파일을 생성하고 CLI를 통해 EMR 6.0.0
(베타) 클러스터를 시작 가능
[ { "Classification": "container-executor",
"Configurations": [ {
"Classification": "docker",
"Properties": { "docker.trusted.registries": "local,centos, your-public-repo,123456789123.dkr.ecr.us-east-
1.amazonaws.com",
"docker.privileged-containers.registries": "local,centos, your-public-repo,123456789123.dkr.ecr.us-east-
1.amazonaws.com" } } ] } ]
$ aws emr create-cluster
--name "EMR-6-Beta Cluster"
--region $REGION
--release-label emr-6.0.0-beta
--applications Name=Hadoop Name=Spark
--service-role EMR_DefaultRole
--ec2-attributes KeyName=$KEYPAIR,InstanceProfile=EMR_EC2_DefaultRole,SubnetId=$SUBNET_ID
--instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=$INSTANCE_TYPE
InstanceGroupType=CORE,InstanceCount=2,InstanceType=$INSTANCE_TYPE
--configuration file://container-executor.json](https://image.slidesharecdn.com/track5session3sparkworkloadexecutionoptimizationplanbasedonemrplatform-200821062610/75/EMR-Spark-AWS-AWS-Summit-Online-Korea-2020-79-2048.jpg)



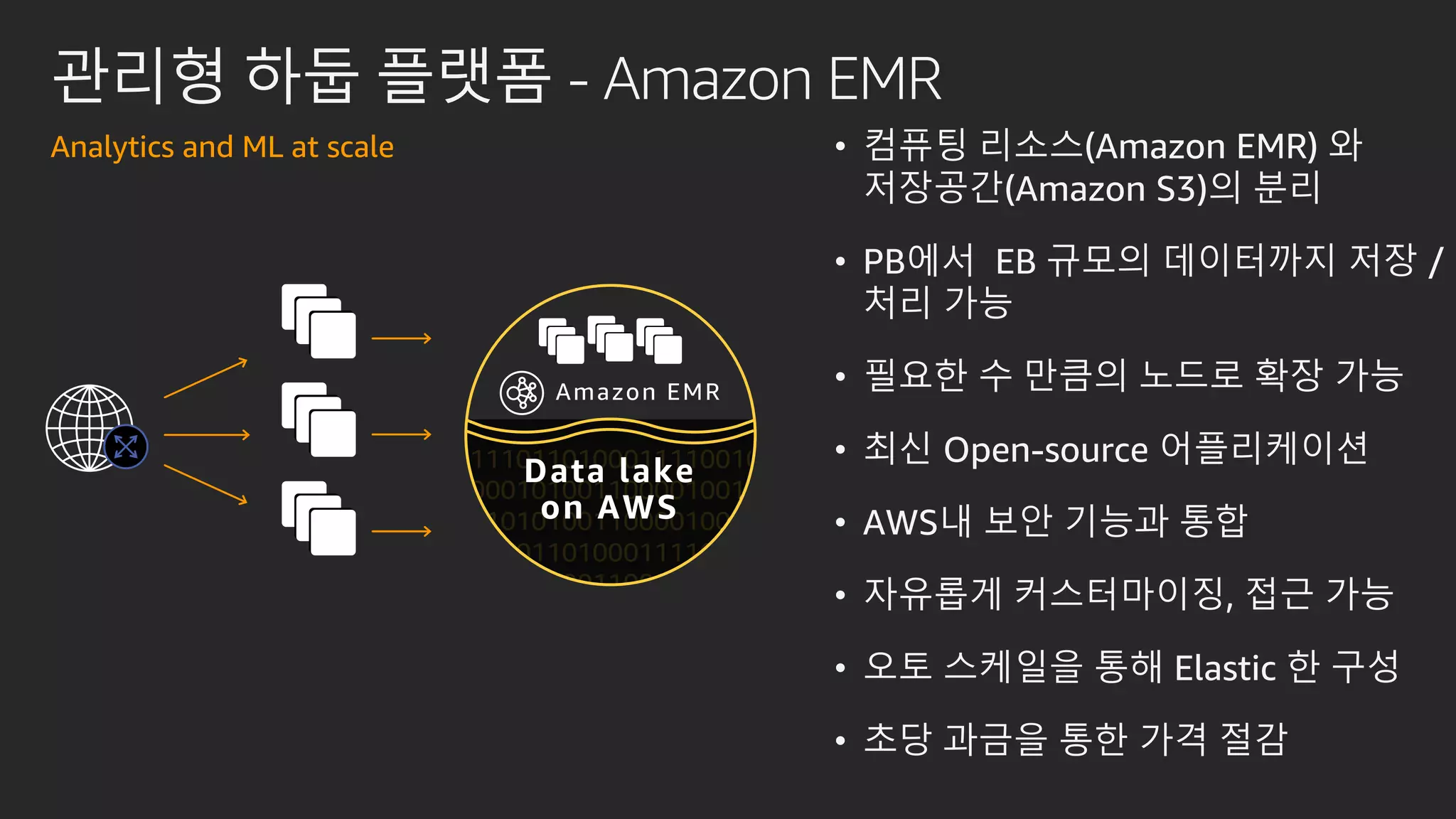
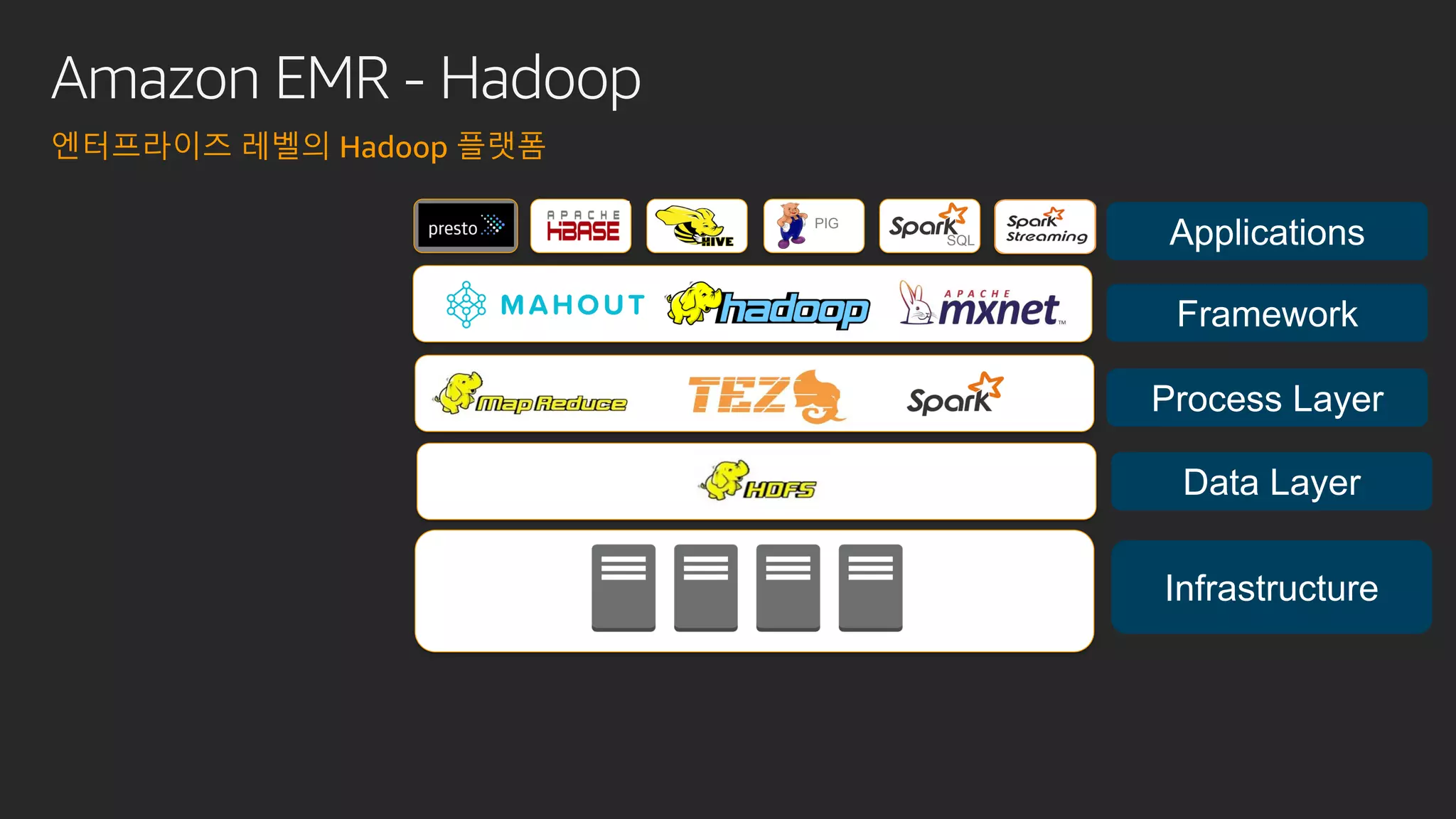
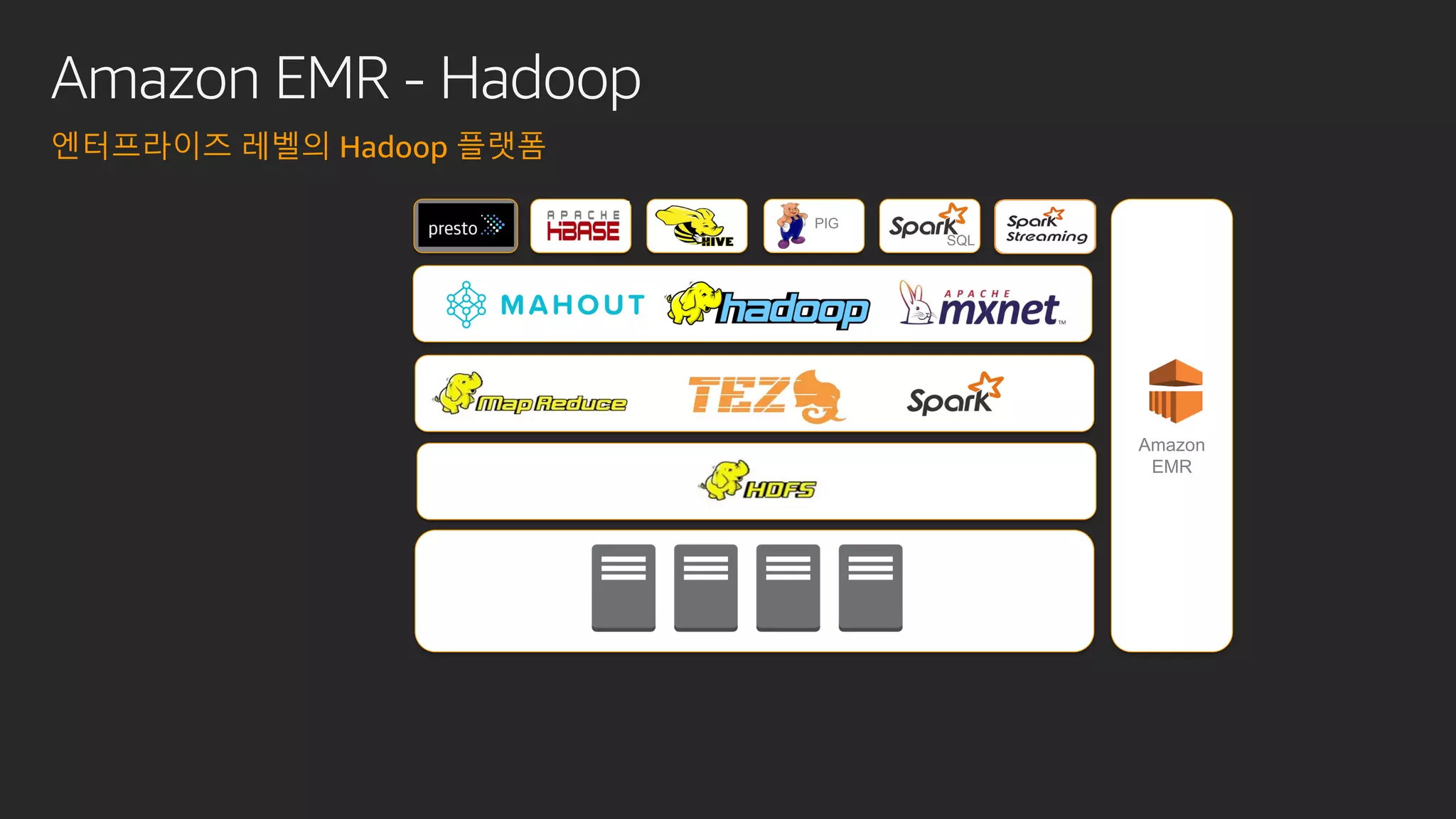
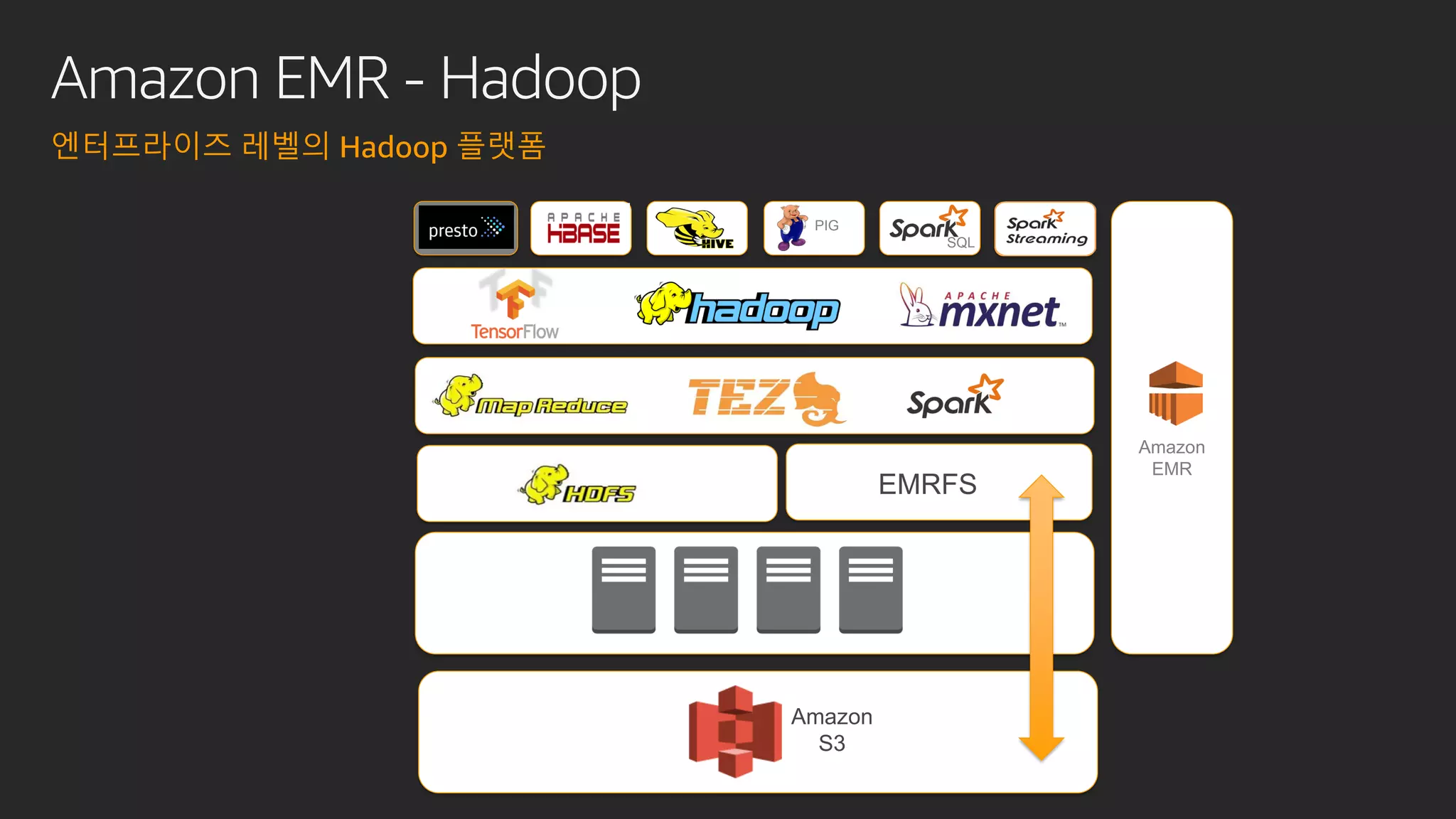
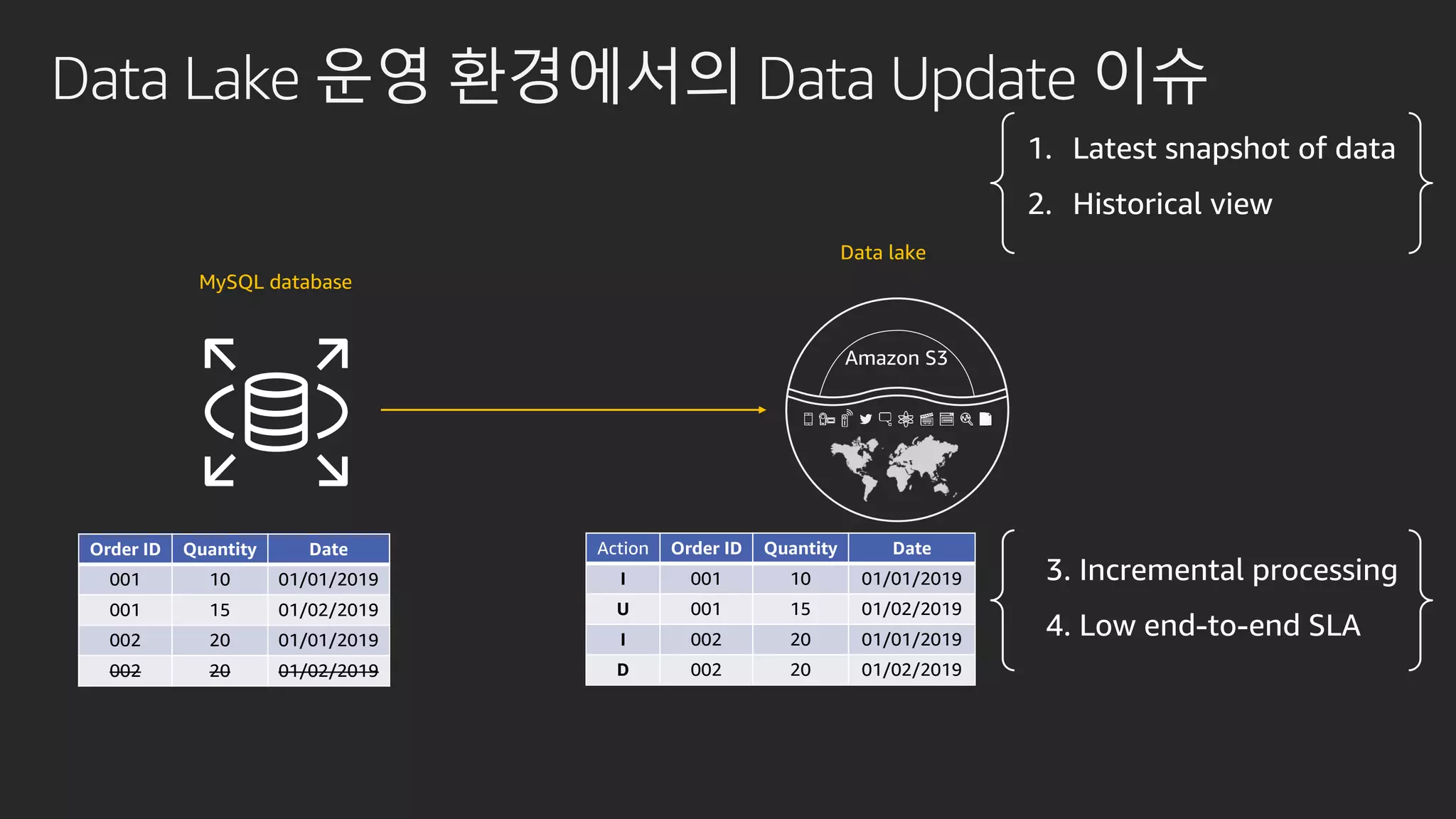
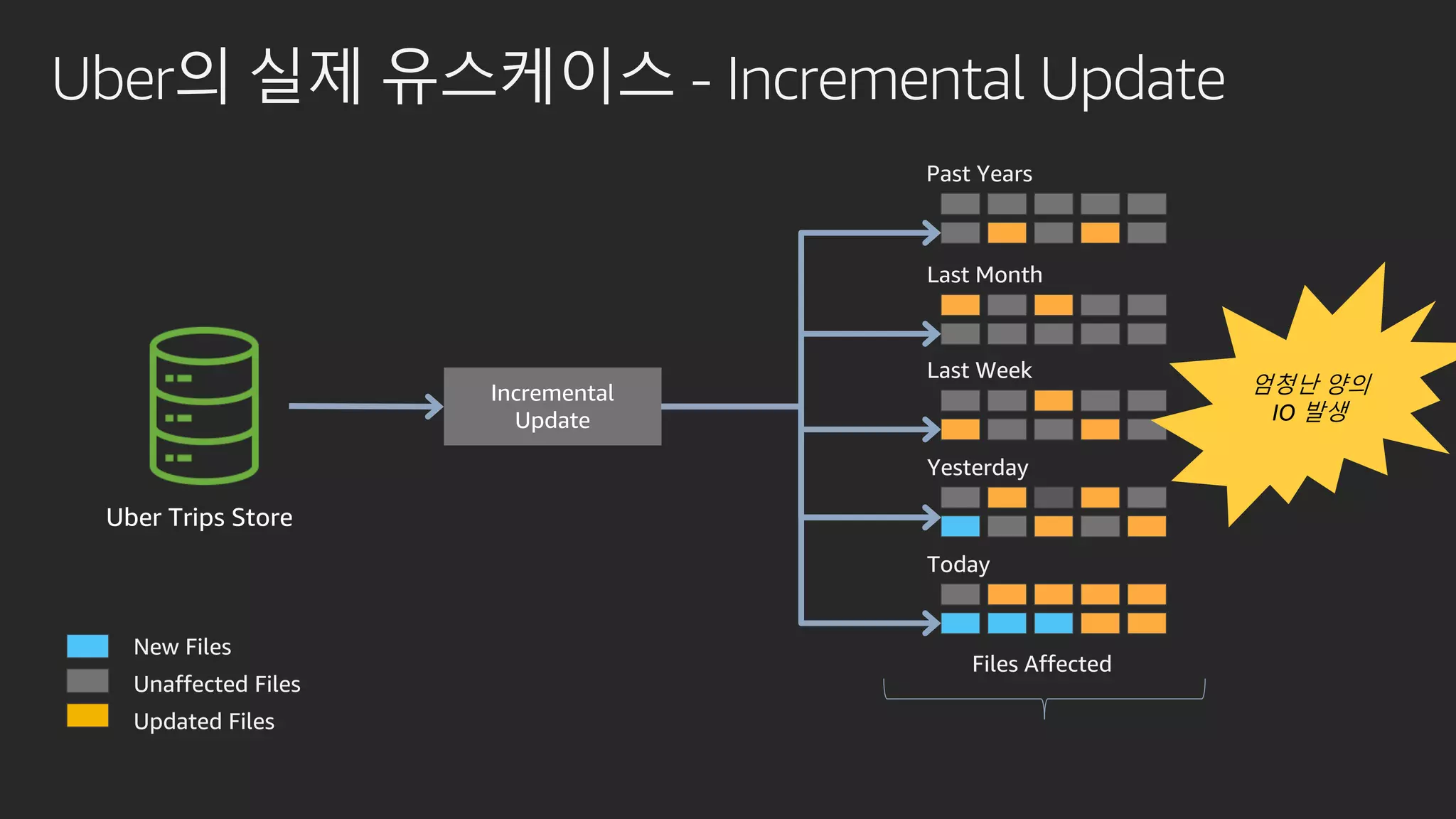
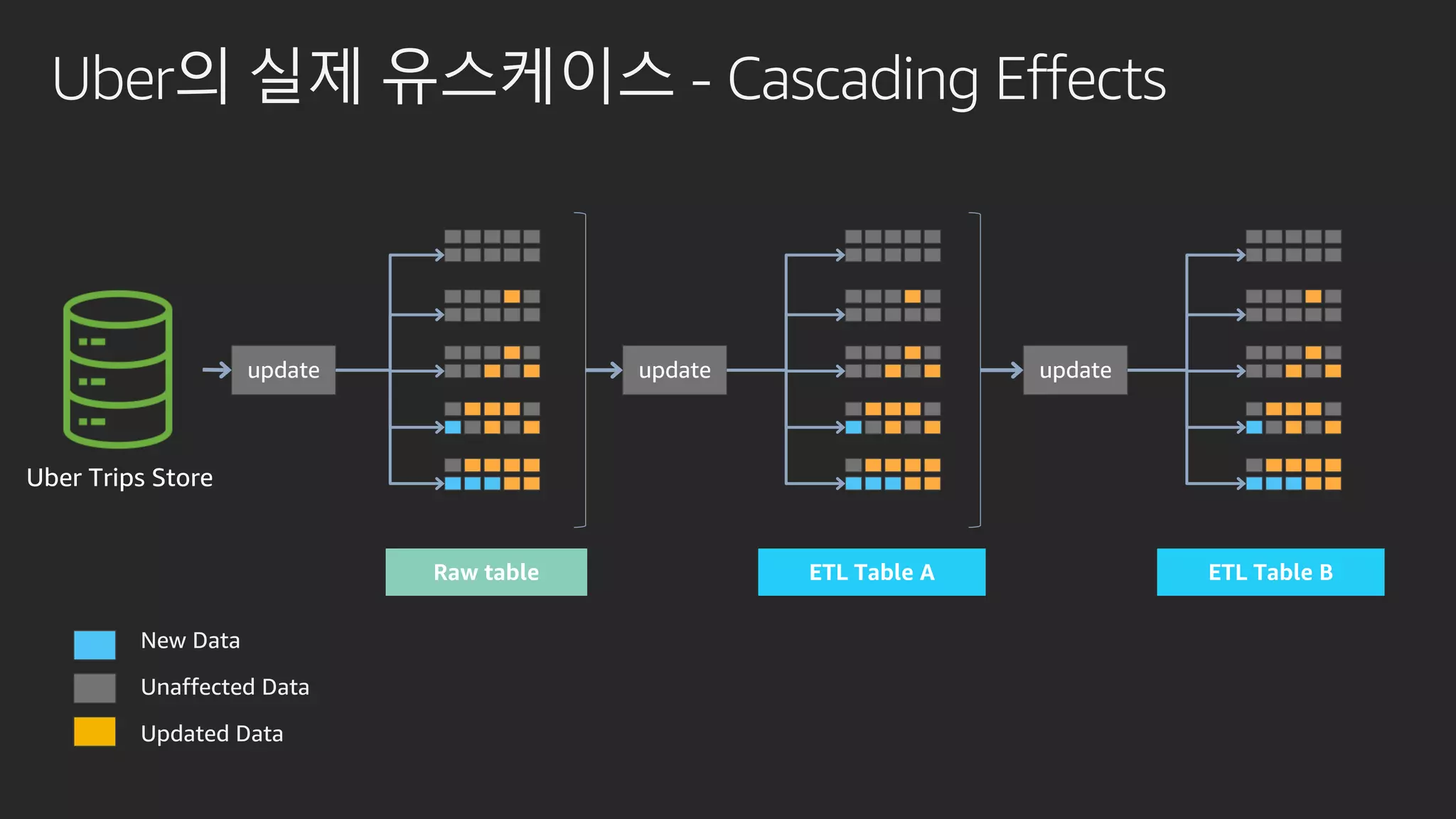
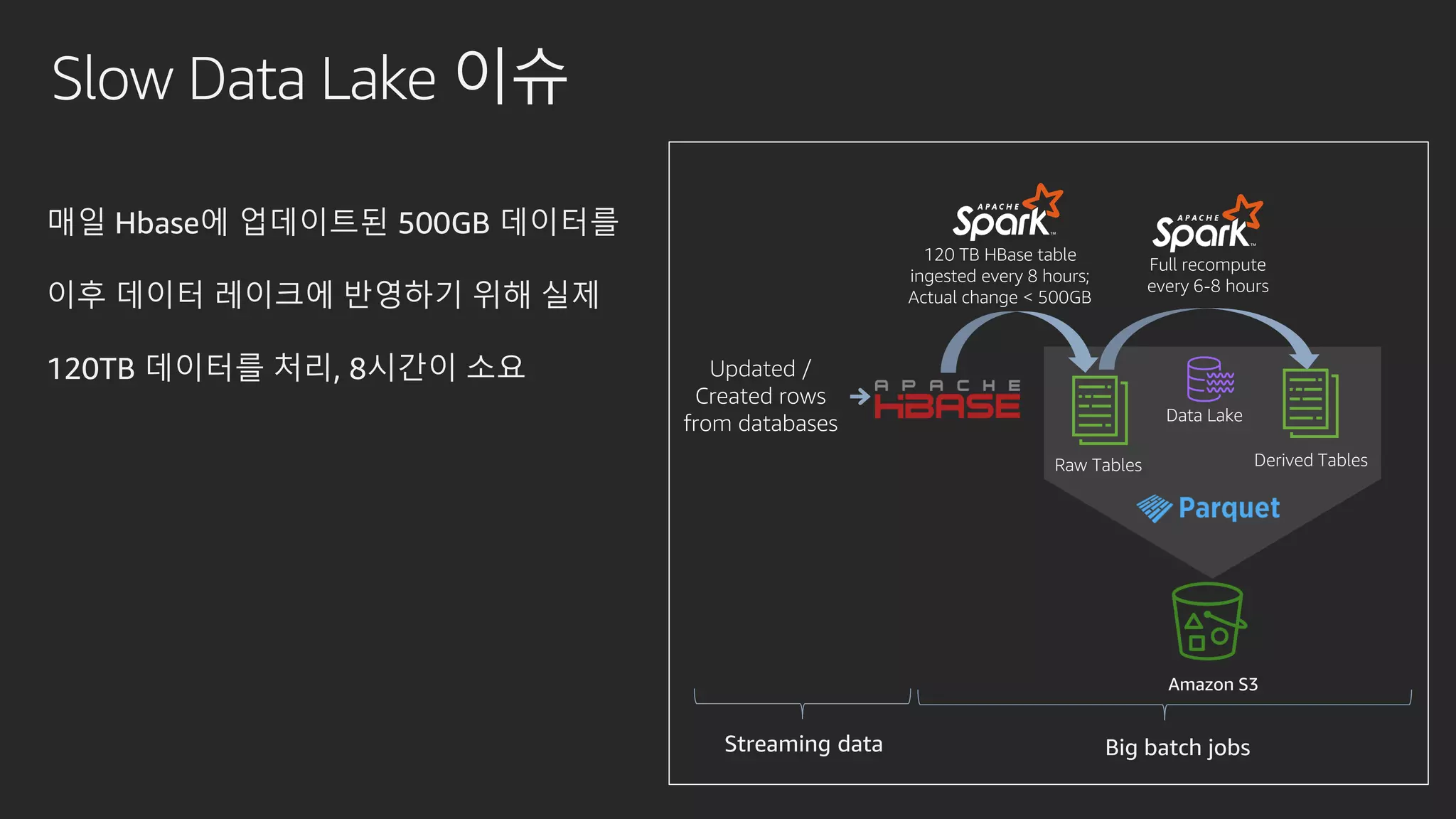
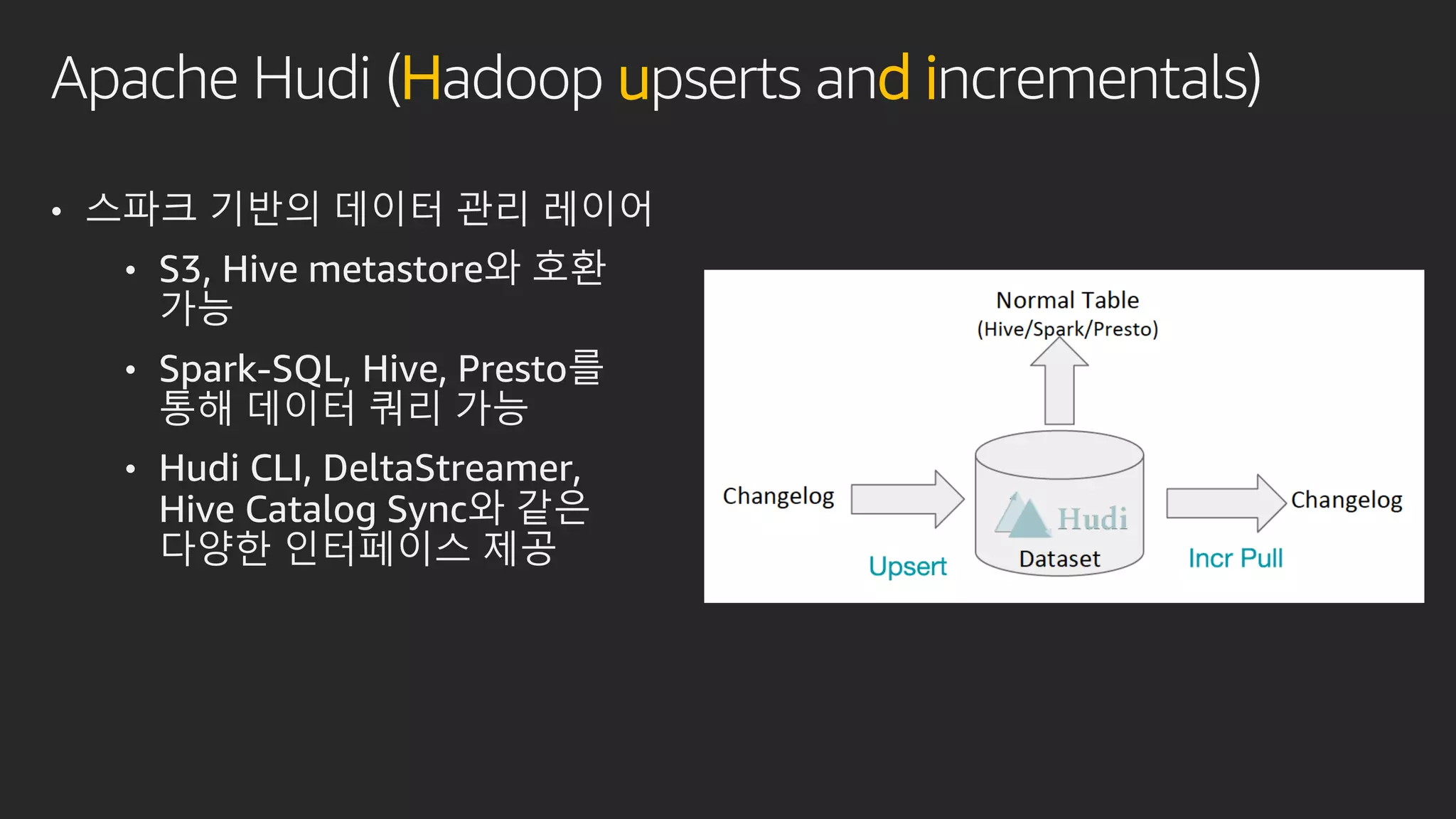
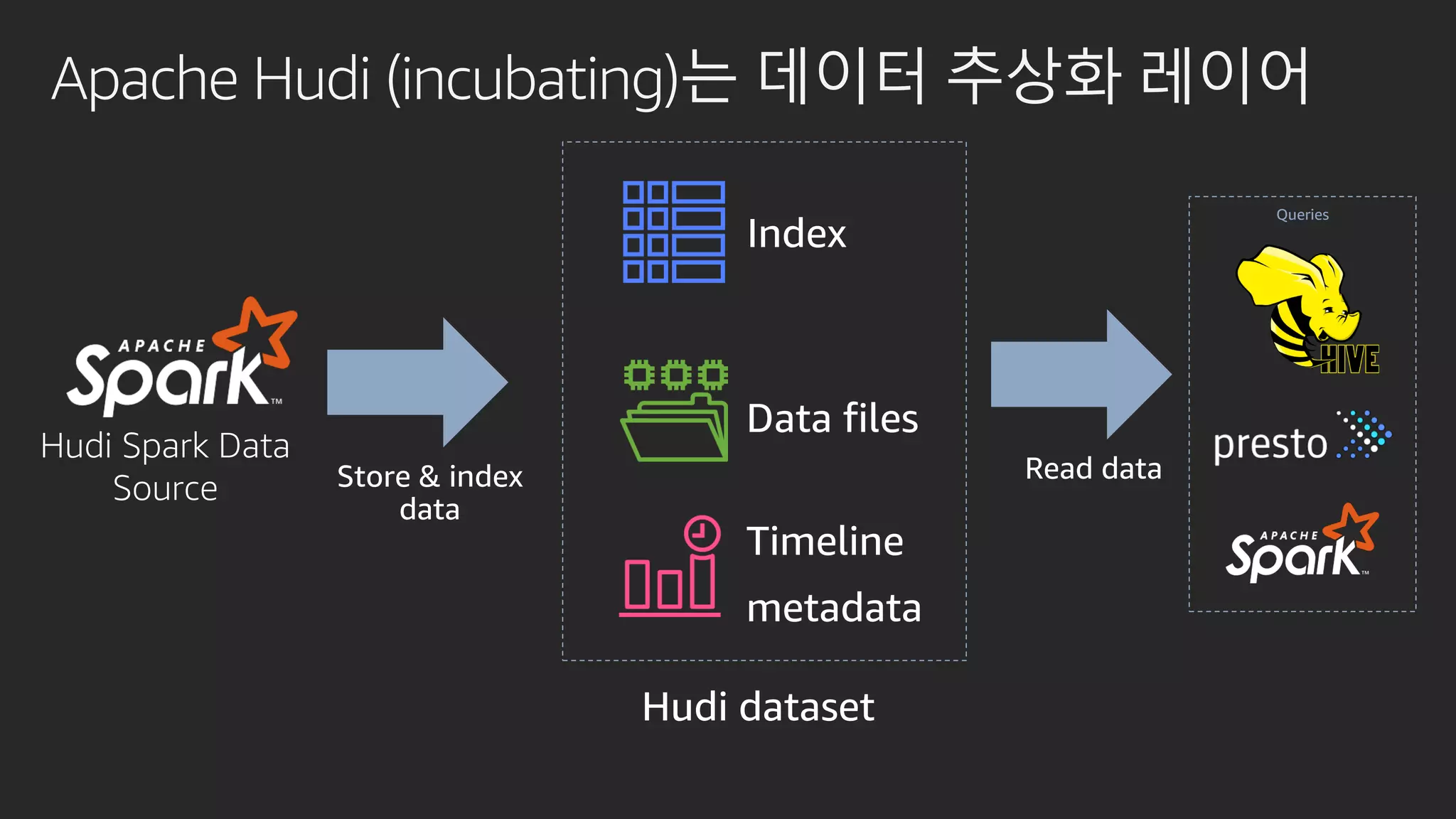
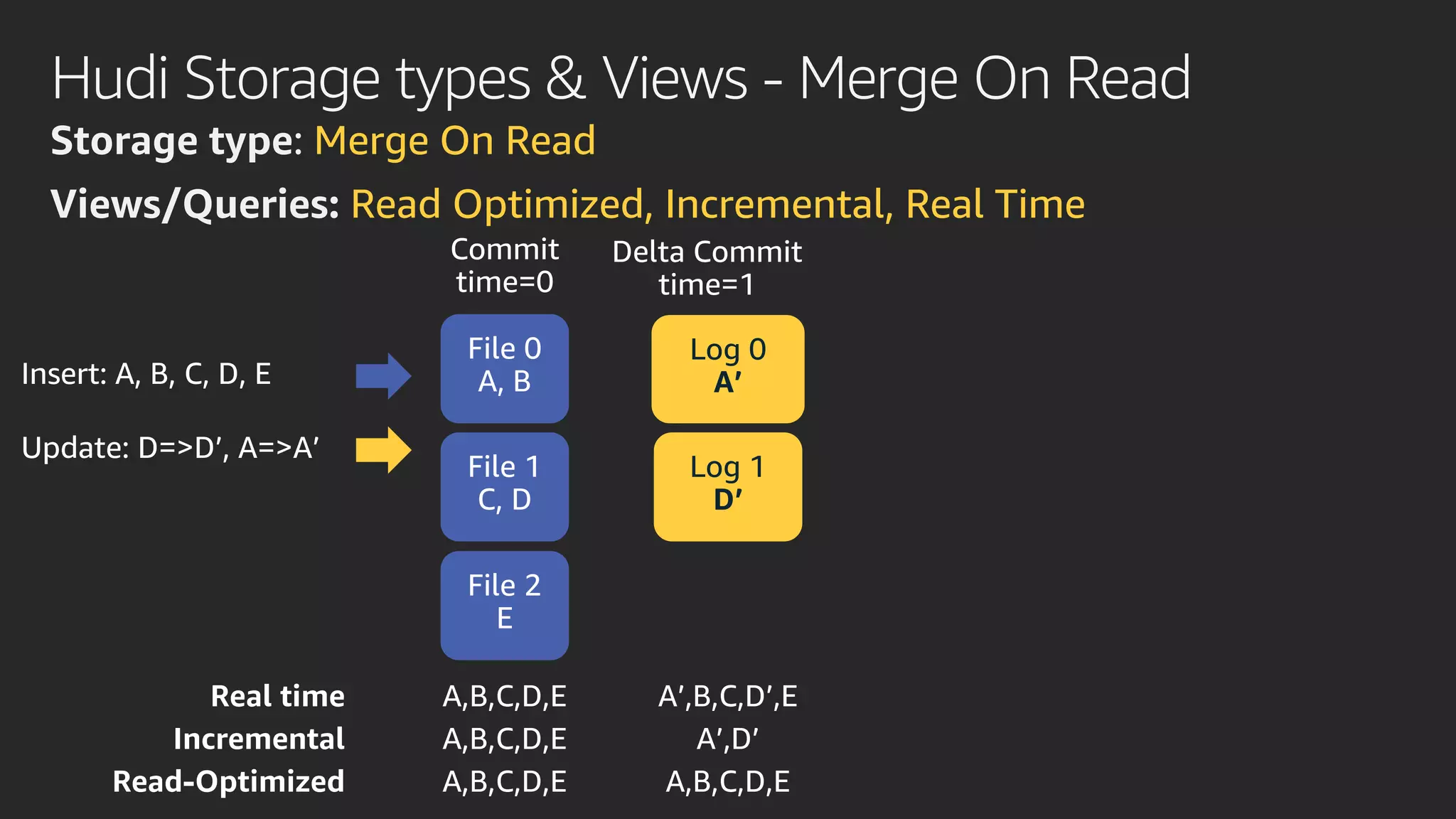
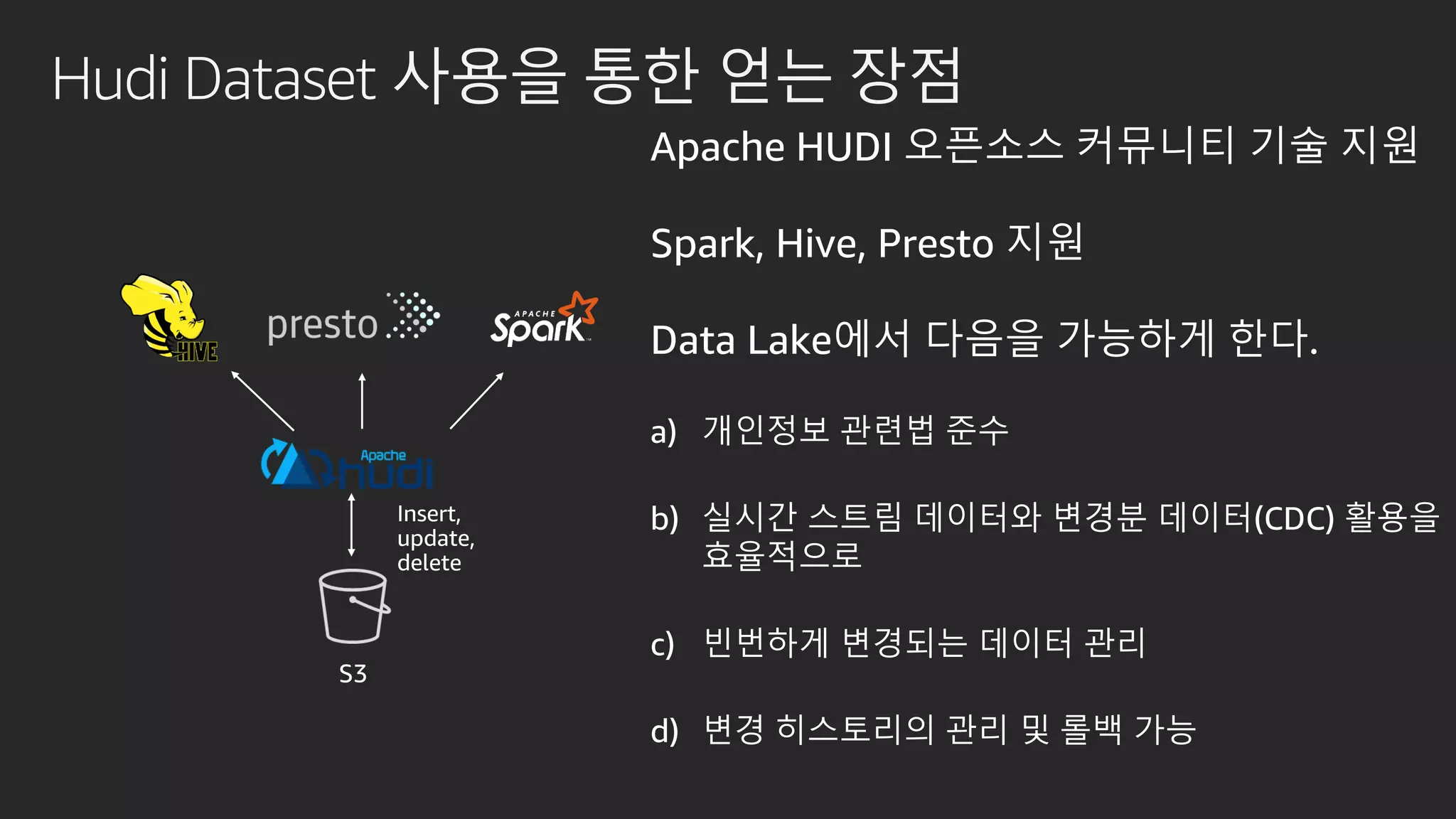
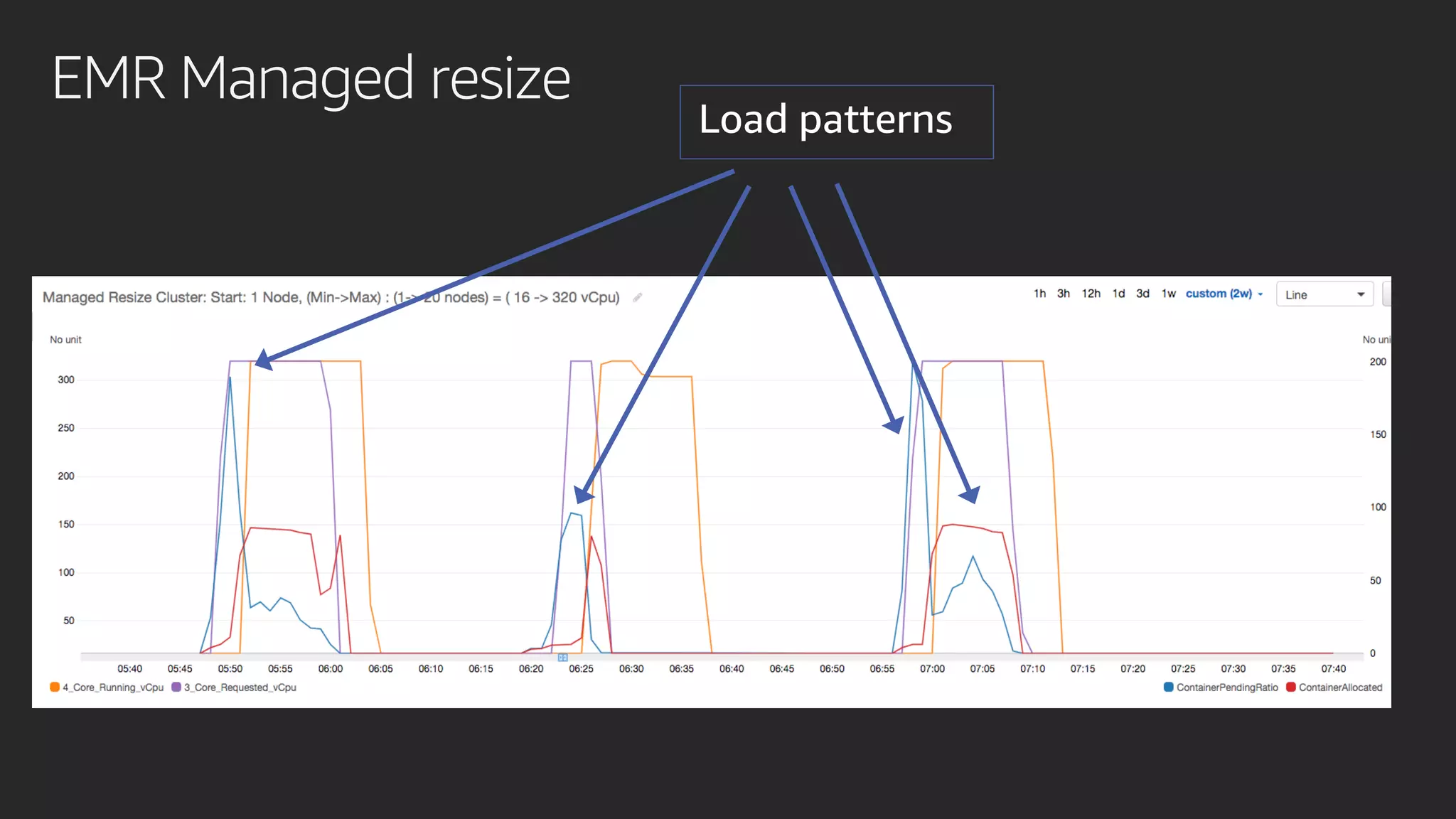
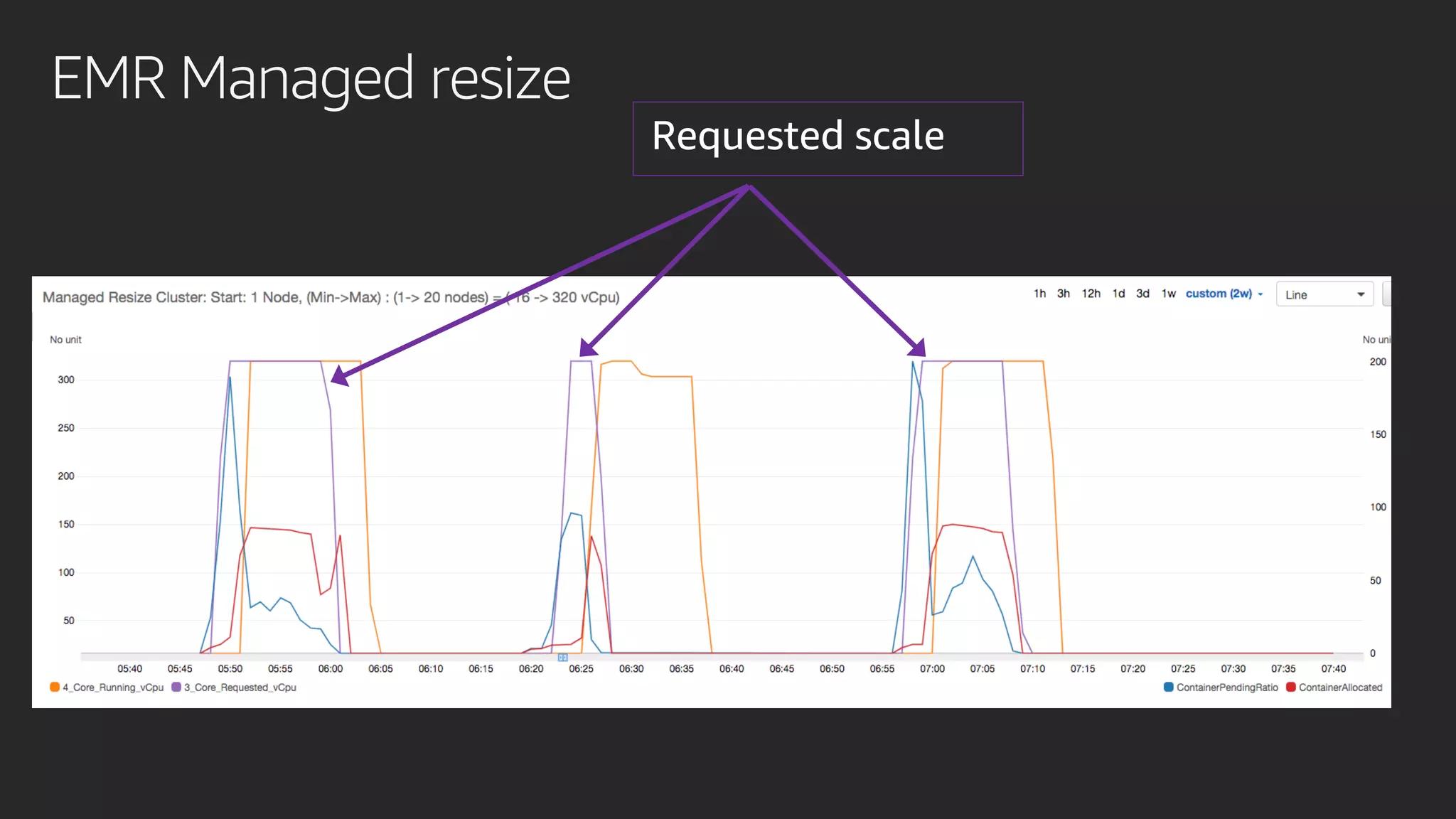
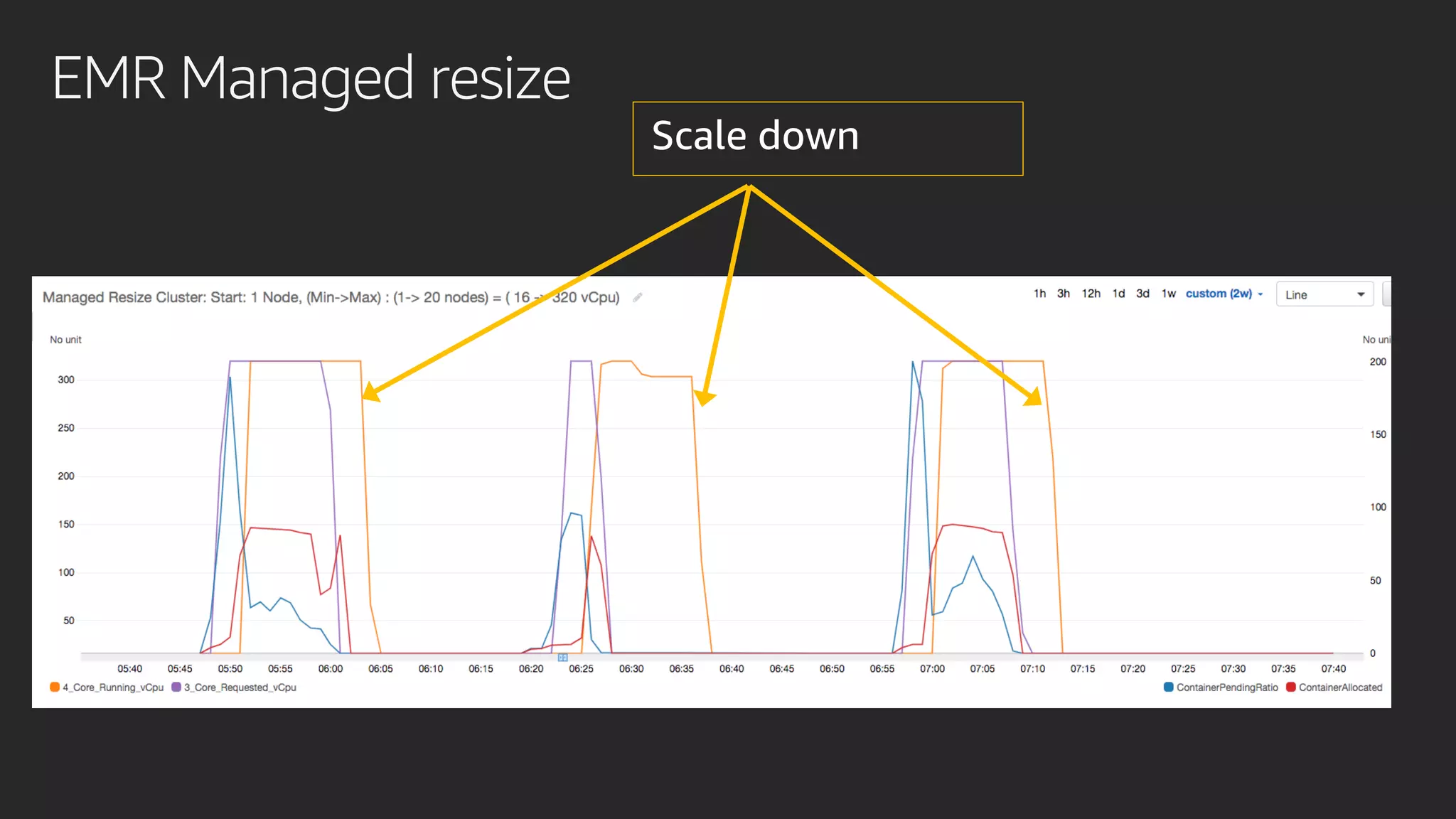
발표영상 다시보기: https://youtu.be/hPvBst9TPlI S3 기반의 데이터레이크에서 대량의 데이터 변환과 처리에 사용될 수 있는 가장 대표적인 솔루션이 Apache Spark 입니다. EMR 플랫폼 환경에서 쉽게 적용 가능한 Apache Spark의 성능 향상 팁을 소개합니다. 또한 데이터의 레코드 레벨 업데이트, 리소스 확장, 권한 관리 및 모니터링과 같은 다양한 데이터 워크로드 관리 최적화 방안을 함께 살펴봅니다.




![[AWS Builders] Effective AWS Glue](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws301effectiveawsgluetaehyunkim-190306061037-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)







![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)









![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)