読んだ論文
・Chen, T., &Guestrin, C. (2016, August). XGBoost: A
scalable tree boosting system. In Proceedings of the 22nd
acm sigkdd international conference on knowledge
discovery and data mining (pp. 785-794). ACM.
・Friedman, J. H. (2001). Greedy function approximation: a
gradient boosting machine. Annals of statistics, 1189-1232.






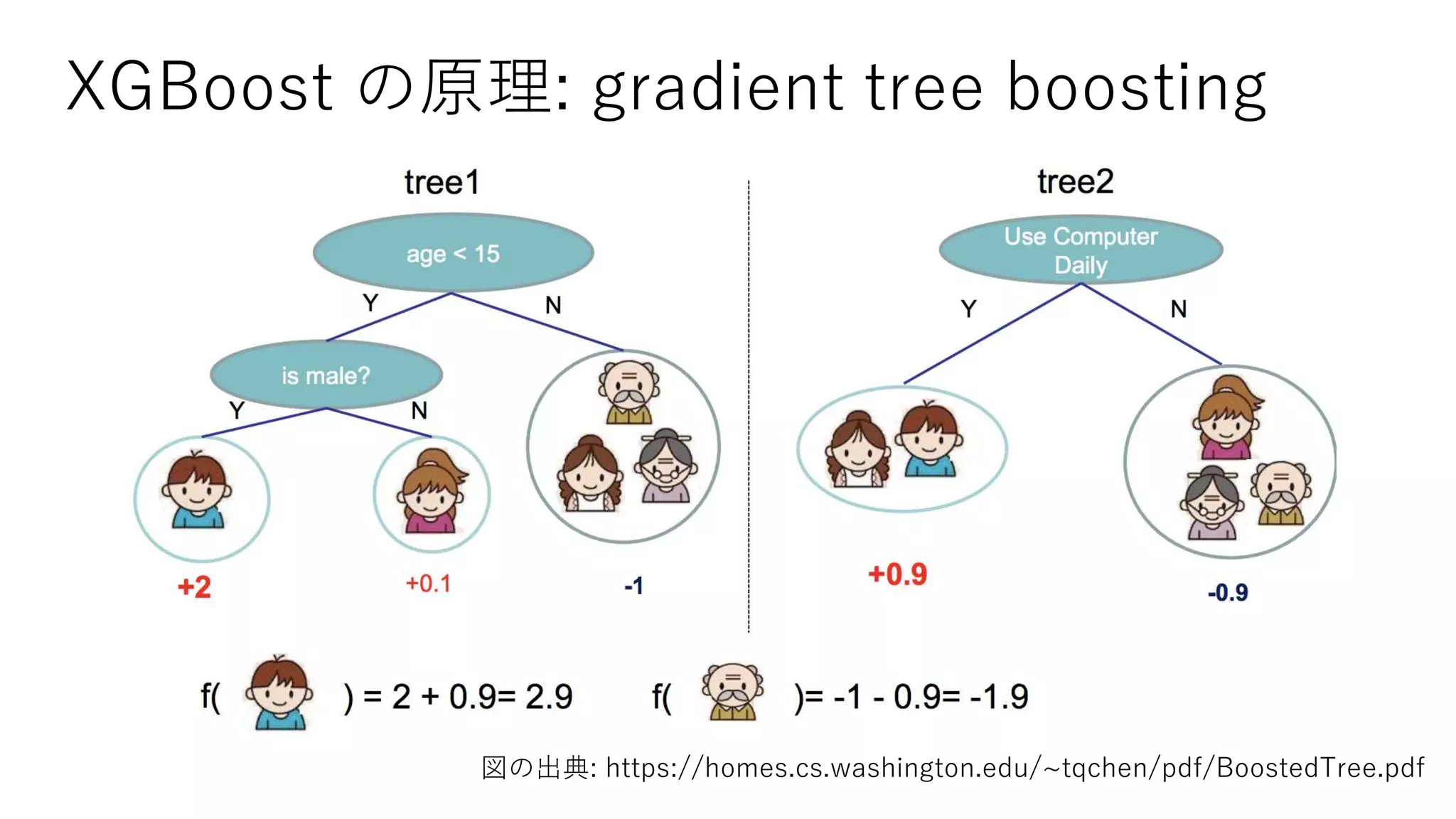

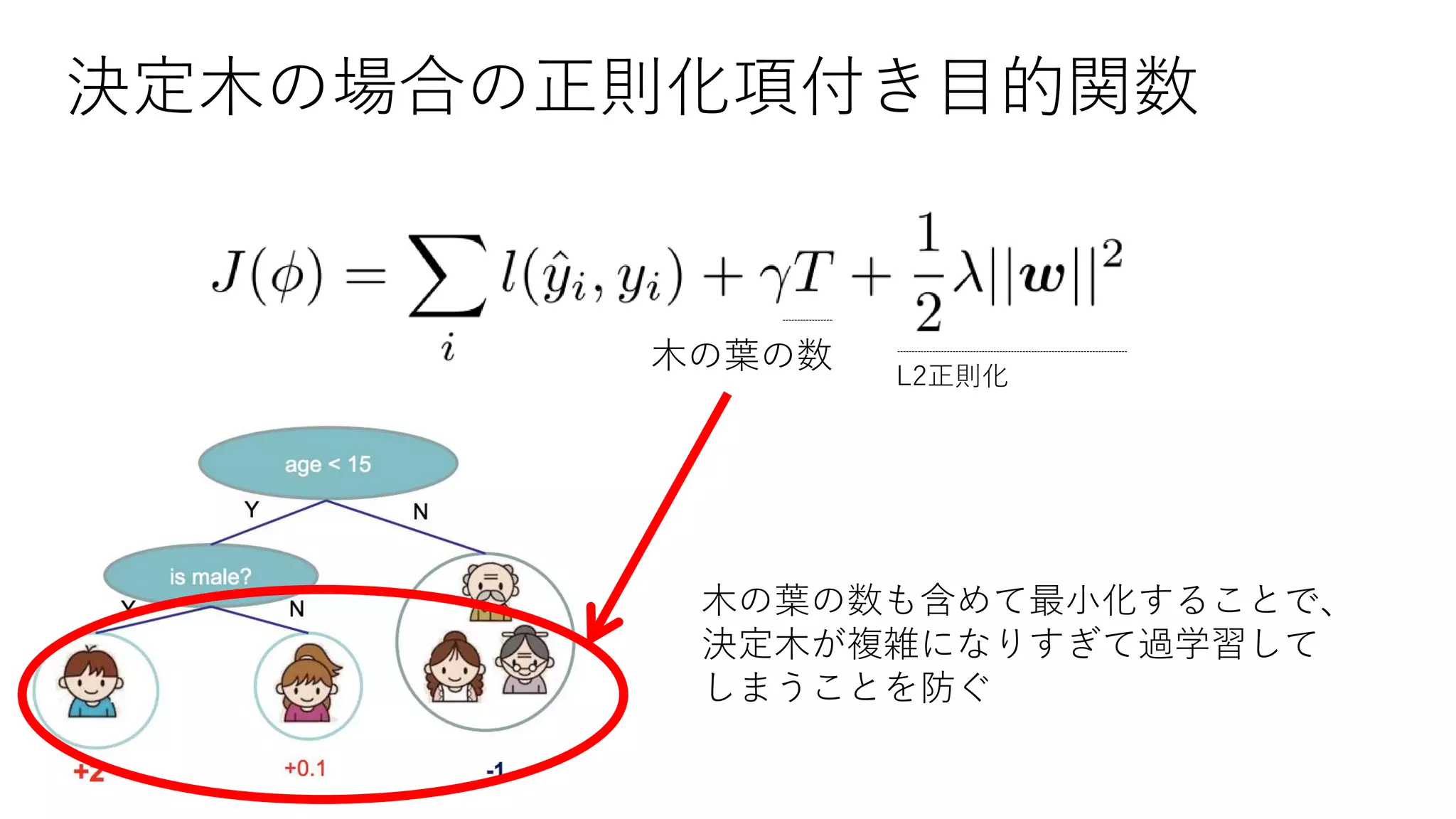



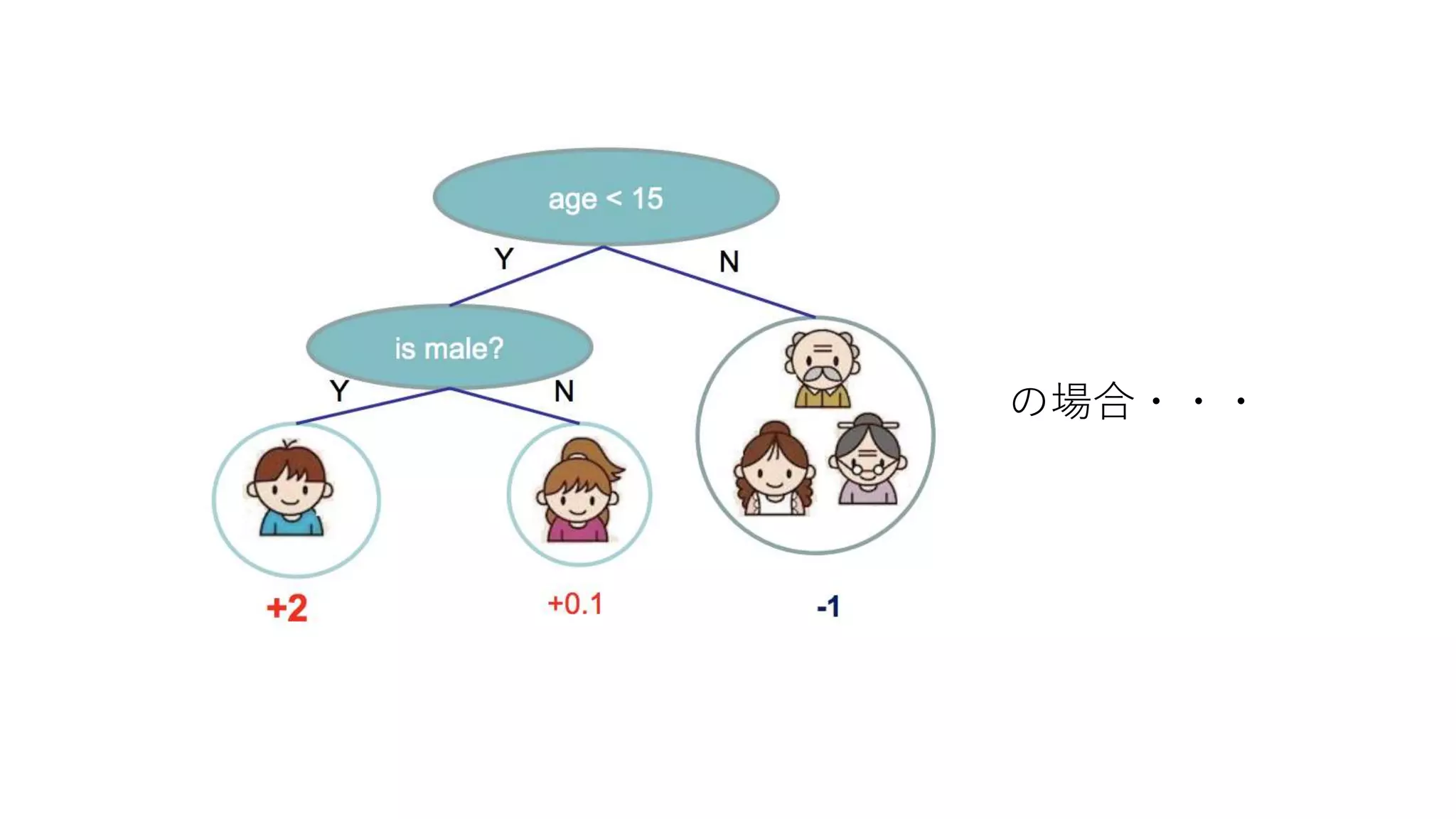
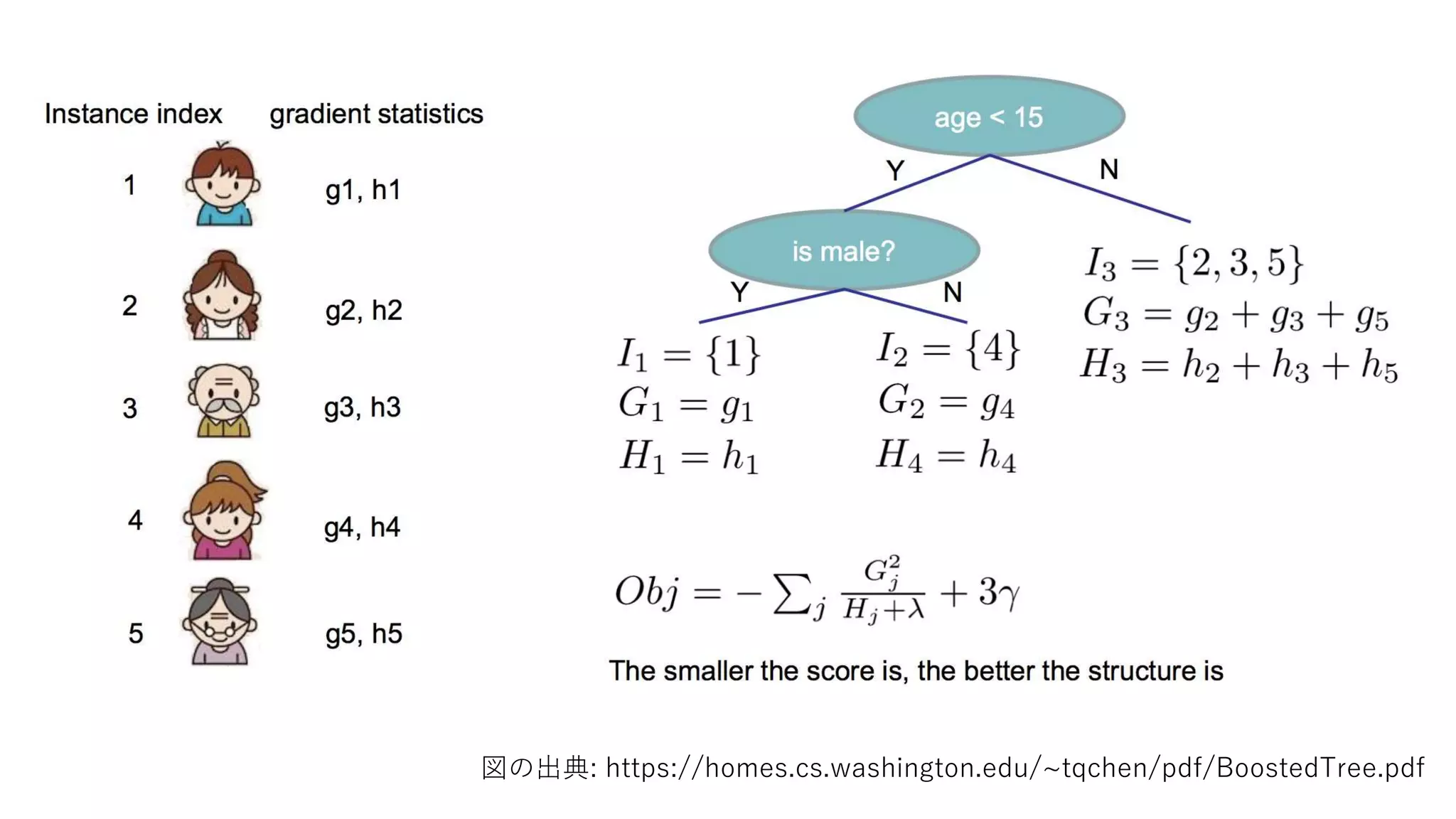


















![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]モデルベース強化学習とEnergy Based Model](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-191129002008-thumbnail.jpg?width=640&height=640&fit=bounds)

















