Download to read offline








![Zurich Universities of Applied Sciences and Arts
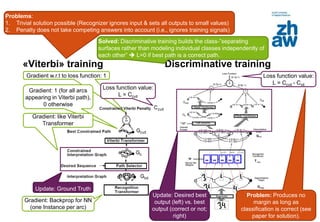
Remarks
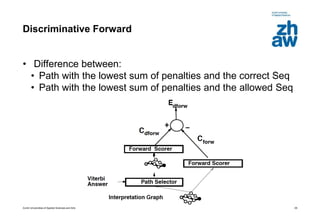
Discriminative training
• Uses all available training signals
• Utilizes “penalties”, not probabilities
No need for normalization
Enforcing normalization is
“complex, inefficient, time
consuming, ill-conditions the loss
function” [according to paper]
• Is the easiest/direct way to achieve
the objective of classification (as
opposed to Generative training,
that solves the more complex density
estimation task as an intermediary
result)
List of possible GT modules
• All building blocks of (C)NNs
(layers, nonlinearity etc.)
• Multiplexer (though not
differentiable w.r.t. to switching input)
can be used to dynamically rewire
GTN architecture per input
• min-function (though not
differentiable everywhere)
• Loss function
16](https://image.slidesharecdn.com/20150701learningendtoend-150702072006-lva1-app6892/85/Learning-End-to-End-16-320.jpg)




![Zurich Universities of Applied Sciences and Arts
Recognition
Transformer
• Iterates over all arcs in the segmentation graph and runs a
character recognizer [here: LeNet5 with 96 classes
(ASCII: 95, rubbish: 1)]
Field Graph
24
„5“ 0.2
„6“ 0.1
„7“ 0.5
CNN](https://image.slidesharecdn.com/20150701learningendtoend-150702072006-lva1-app6892/85/Learning-End-to-End-24-320.jpg)
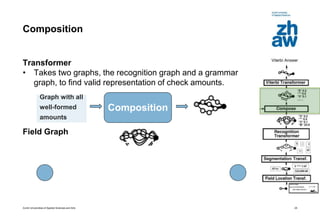
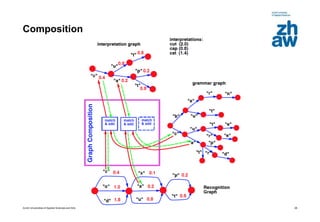






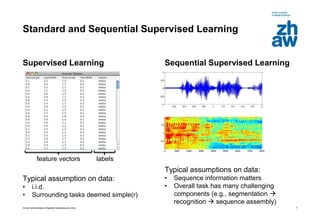
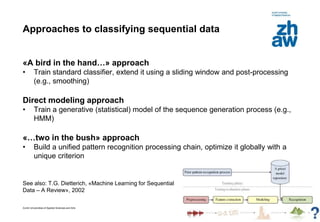
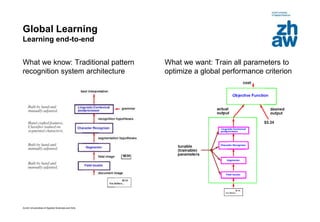
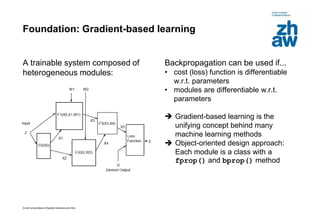
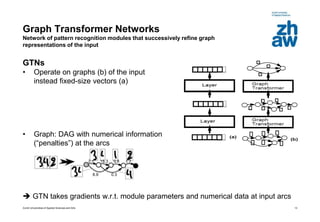
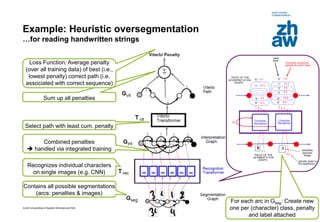
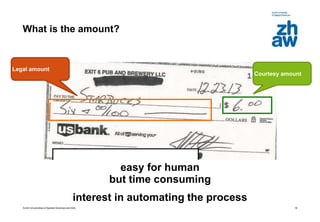
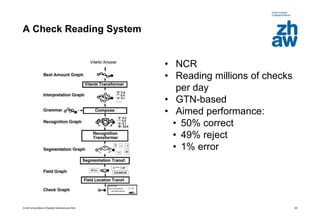
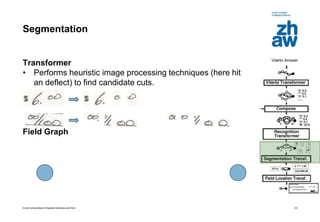
This document discusses using global learning and graph transformer networks to solve sequential supervised learning problems. It proposes training all modules of a machine learning system end-to-end using backpropagation to optimize a single global criterion, rather than training modules independently. As an example, it describes a system for reading handwritten check amounts that segments, recognizes characters, and assembles the output using a graph transformer network trained discriminatively.
























![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)










































