Downloaded 138 times























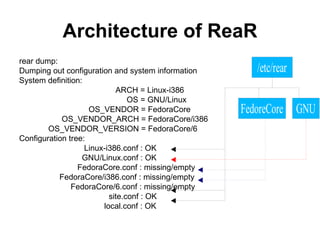





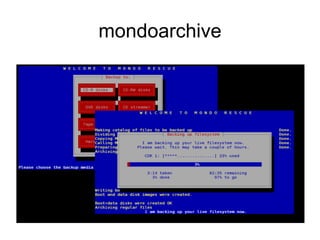


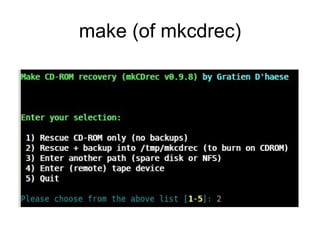



The document provides an extensive overview of Linux disaster recovery solutions, highlighting the importance of having a disaster recovery plan (DRP) beyond just backups. It compares various commercial and open-source solutions, outlining their pros and cons, and emphasizes the need for immediate action in case of disasters while ensuring system reliability through testing and proper recovery strategies. The document also includes insights from testing different solutions like Mondorescue, mkcdrec, and Relax-and-Recover (rear) on Linux systems.












































































