Download to read offline


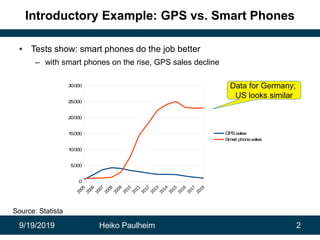
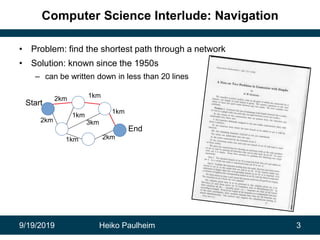
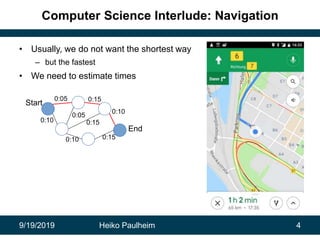


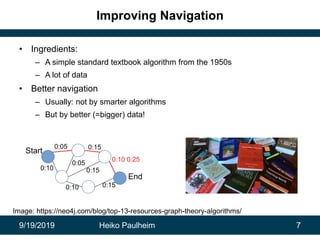
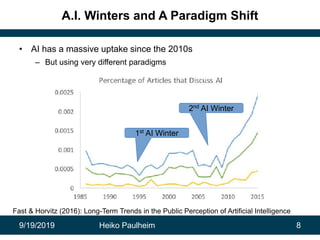

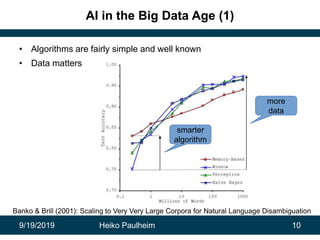
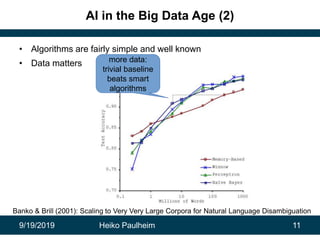


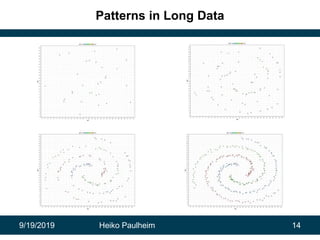






This document discusses how modern artificial intelligence relies on massive amounts of data rather than complex algorithms. It provides examples of how companies like Google, Facebook, and WeChat have improved services by utilizing long datasets from many users and merging different types of wide data. The author argues that while algorithms are typically well-known, data ownership allows companies to gain market power since data availability is crucial for artificial intelligence systems.























![[EN] Breaking the Barriers of Traditional Records Management | Ulrich Kampffm...](https://cdn.slidesharecdn.com/ss_thumbnails/20081212dlm20forumbreaking20the20barrierskff1-140510065101-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
























































