Download to read offline


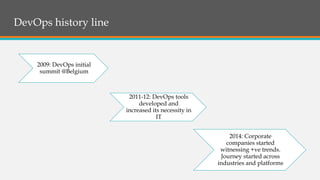

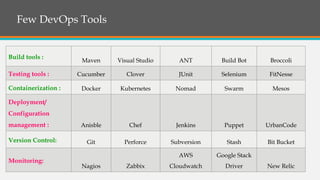




The document discusses DevOps as a process model that integrates development and operations, emphasizing its evolution, tools, and best practices. It highlights the significance of performance metrics like MTBF, MTTR, and MTRS, along with common pitfalls and bad practices in implementing DevOps. Additionally, it lists various DevOps certifications and tools across different stages of the software life cycle.



















































































