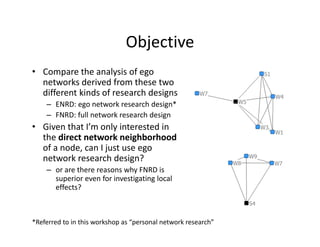
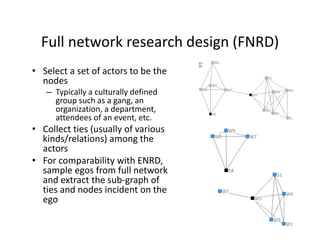
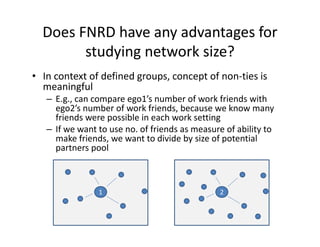
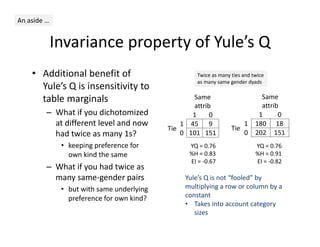
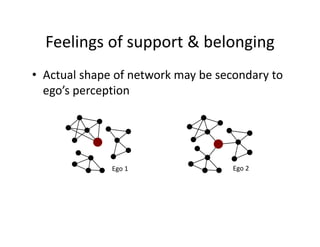
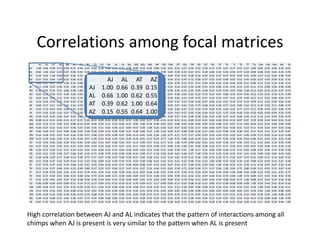
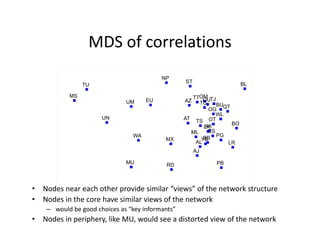
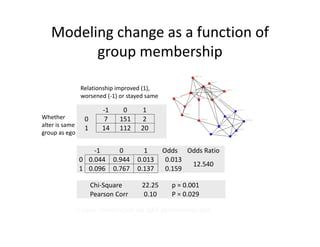
This document discusses methods for analyzing personal networks derived from ego network research designs (ENRDs) and full network research designs (FNRDs). It argues that while ENRDs have advantages in terms of cost, validity of data, and ethics, FNRDs allow for additional analyses like examining non-ties, network context, and incoming ties. Both designs can be used to measure network size, composition, and homophily, though FNRDs provide more context. Overall, the document aims to compare the utility of these approaches for investigating local network effects.