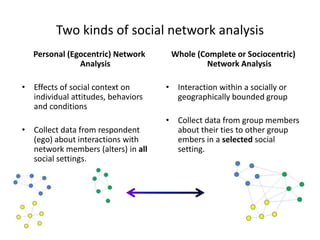
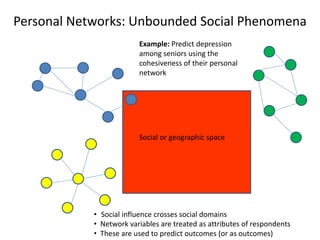
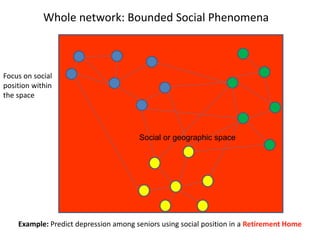
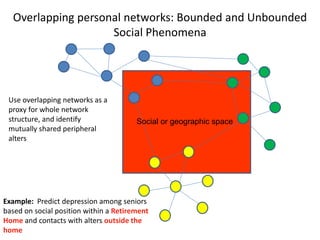
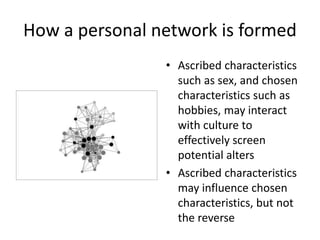
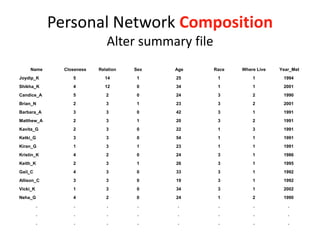
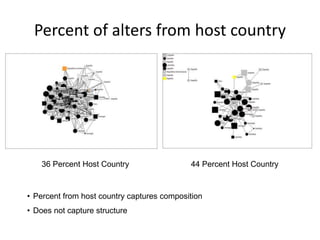
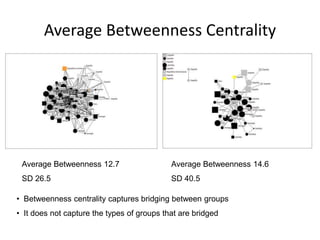
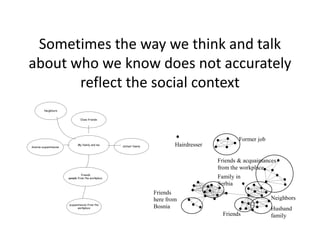
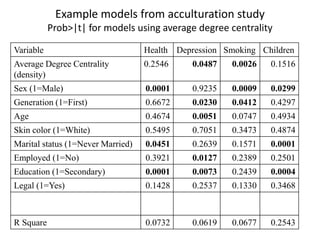
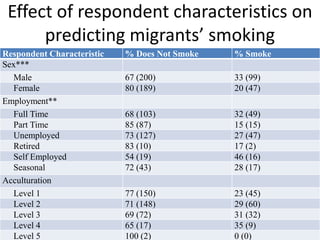
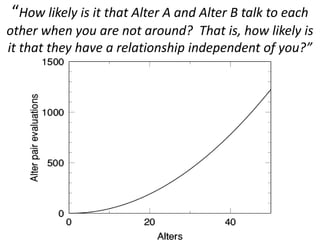
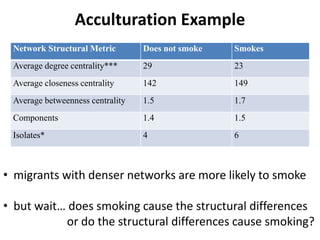
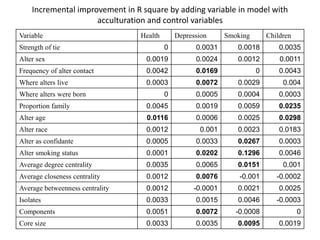
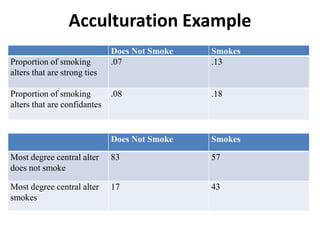
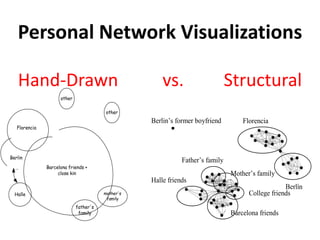
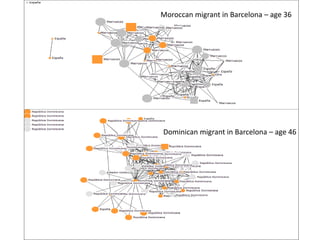
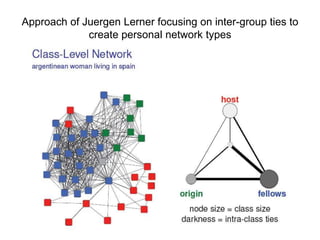
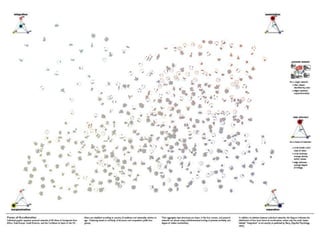
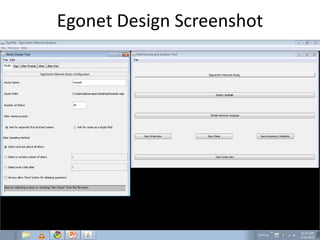
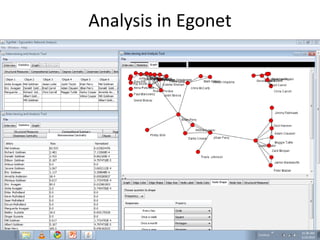
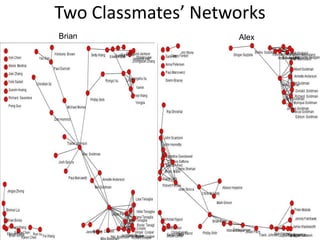
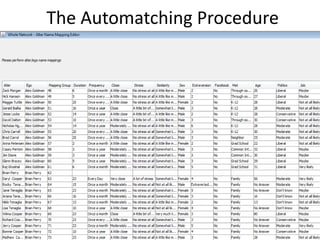
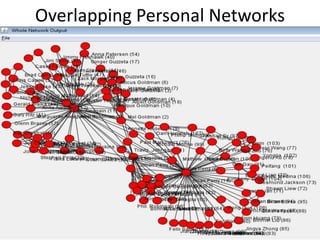
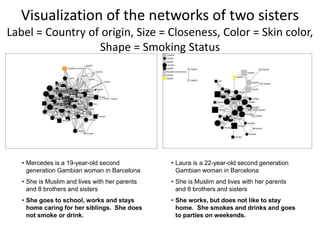
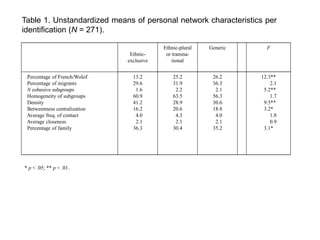
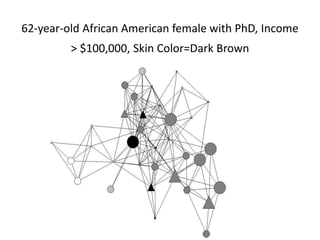
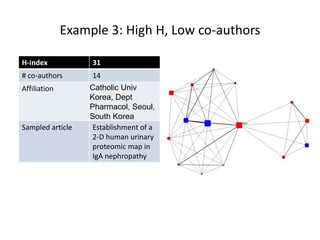
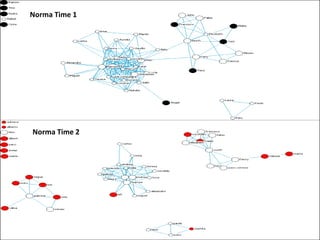
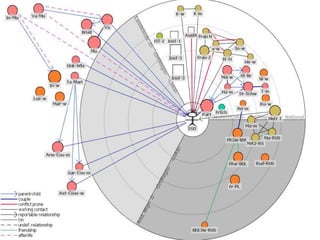
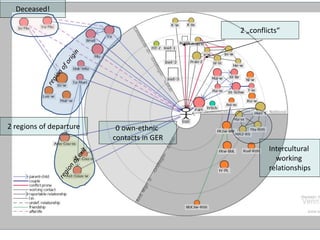
This document discusses two main types of social network analysis: personal (egocentric) network analysis and whole (sociocentric) network analysis. It notes that personal network analysis focuses on how social context affects individuals, collecting data from respondents about their interactions with network members. Whole network analysis looks at interaction within a bounded group, collecting data from all group members. However, it notes that the distinction is not simple, as personal networks are part of the spectrum of social observations within the larger whole network of the world.