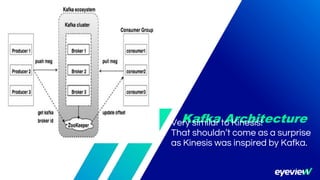
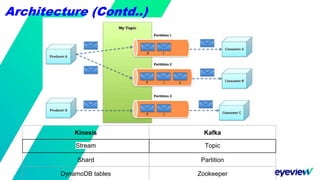
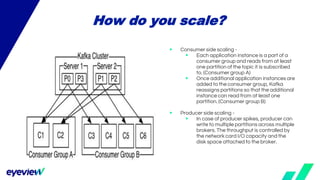
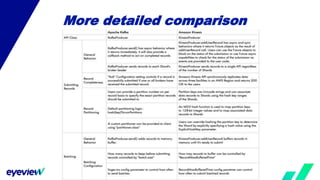
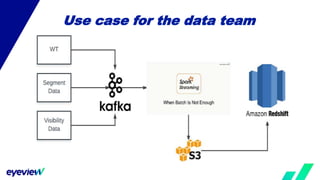
This document compares the architectures of Kafka and Kinesis. Both have similar architectures, with Kafka brokers storing messages in partitions and consumers subscribing to topics. The document finds that Kafka has higher throughput and lower costs than Kinesis due to Kinesis' throughput limits. It also notes headaches with Kinesis' throughput limits and management overhead. The document recommends switching from Kinesis to Kafka for these reasons.





























































![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)


















