Download to read offline



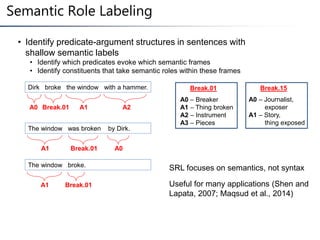






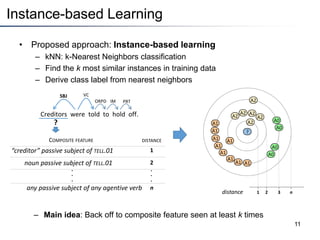




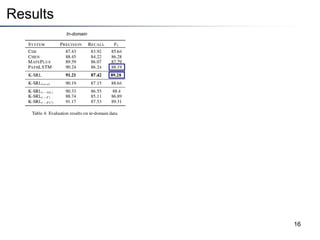


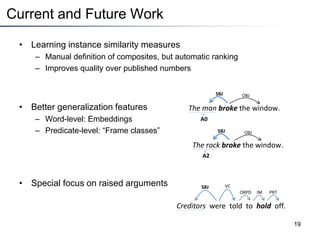



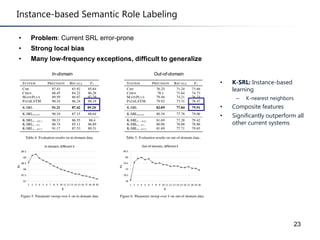




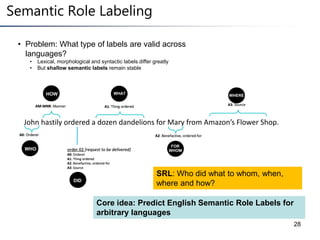
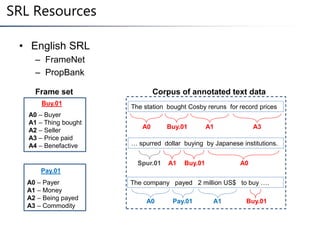

This document summarizes a research paper on instance-based learning for semantic role labeling (SRL). It presents a simple but effective k-nearest neighbors approach using composite features that outperforms previous SRL systems on both in-domain and out-of-domain evaluation. The approach models global argument constraints and addresses SRL challenges like heavy-tailed label distributions and low-frequency exceptions through explicit representation of local biases in composite features.

























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









