Methodology Taxonomy of Normalization Edits Analyzes Effect on Parsing, NER, TTS
•Download as PPT, PDF•
0 likes•190 views

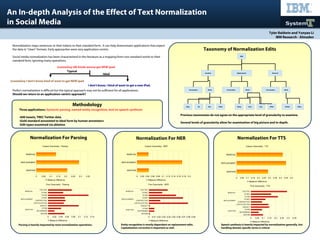
This document proposes a taxonomy for characterizing different types of text normalization edits based on their level of granularity and impact on downstream natural language processing applications like syntactic parsing, named-entity recognition, and text-to-speech synthesis. It examines the effects of coarse-grained edit types like addition, replacement, and removal as well as more fine-grained types like corrections to verb forms, determiners, capitalization, contractions, slang, and Twitter-specific terms. The analysis found that parsing is impacted by most normalization operations, entity recognition depends strongly on replacements, and speech synthesis benefits broadly from normalization but requires handling domain-specific terms.
Recommended

Recommended
More Related Content
More from Yunyao Li
More from Yunyao Li (20)
Recently uploaded
Recently uploaded (20)
Methodology Taxonomy of Normalization Edits Analyzes Effect on Parsing, NER, TTS
- 1. Methodology Taxonomy of Normalization Edits Tyler Baldwin and Yunyao Li IBM Research - Almaden An In-depth Analysis of the Effect of Text Normalization in Social Media Normalization For Parsing Normalization maps sentences or their tokens to their standard form. It can help downstream applications that expect the data in “clean” formats. Early approaches were very application-centric. Social media normalization has been characterized in the literature as a mapping from non-standard words to their standard form, ignoring many operations. Perfect normalization is difficult but the typical approach may not be sufficient for all applications. Should we return to an application-centric approach? Previous taxonomies do not agree on the appropriate level of granularity to examine. Several levels of granularity allow for examination of big picture and in-depth. Three applications: Syntactic parsing, named-entity recognition, text-to-speech synthesis -600 tweets, TREC Twitter data -Gold standard annotated to ideal form by human annotators -Edit types examined via ablation Normalization For NER Normalization For TTS ADDITION REPLACEMENT REMOVAL 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 Coarse Granularity - Parsing F-Measure Difference BEVERB DETERMINER OTHER SUBJECT CAPITALIZATION CONTRACTION OTHER SLANG OTHER TWITTER ADDITION REPLACEMENT REMOVAL 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 Fine Granularity - NER F-Measure Difference BEVERB DETERMINER OTHER SUBJECT CAPITALIZATION CONTRACTION OTHER SLANG OTHER TWITTER ADDITION REPLACEMENT REMOVAL 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 Fine Granularity - Parsing F-Measure Difference ADDITION REPLACEMENT REMOVAL 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 Coarse Granularity - NER F-Measure Difference BEVERB DETERMINER OTHER SUBJECT CAPITALIZATION CONTRACTION OTHER SLANG OTHER TWITTER ADDITION REPLACEMENT REMOVAL 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 Fine Granularity - TTS F-Measure Difference ADDITION REPLACEMENT REMOVAL 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 Coarse Granularity - TTS F-Measure Difference Edit Insertion Replacement Removal Punctuation Word Word Word Subj. Be Det. Other Slang Cont. Cap. Other Twitter Other Punctuation Punctuation Parsing is heavily impacted by most normalization operations. Entity recognition is mostly dependent on replacement edits. Capitalization correction is important as well. Speech synthesis is heavily impacted by normalization generally, but handling domain-specific terms is critical. @someGuy idk kinda wanna get NEW ipad @someGuy I don't know kind of want to get NEW ipad I don't know, I kind of want to get a new iPad. Typical Ideal