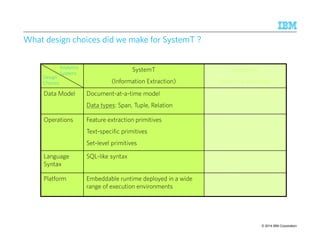
Downloaded 32 times




![~1500 lines of Java code
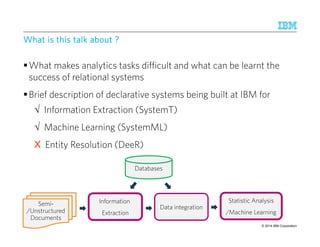
BBBBrrrreeeeaaaaddddtttthhhh
SSSSccccaaaalllleeee
Different Loss function
KL-divergence Wide varieties of ML models
450M+ tweets per day, …
© 2014 IBM Corporation
Challenges in Scalable CCChhhaaalllllleeennngggeeesss iiinnn SSScccaaalllaaabbbllleee MMMMaaaacccchhhhiiiinnnneeee LLLLeeeeaaaarrrrnnnniiiinnnngggg
topics topics words
V ≈ W H
documents
x
13 9/10/2014 IBM Research – Almaden
[Liu, WWW 2010]
• Billions of non-zeros within tens of hours
• Careful partitioning of data
• Maximize data locality and parallelism
% initialize W, H
while (~converged)
W = W*(V%*%t(H))/(W%*%H%*%t(H))
H = H*(t(W)%*%V)/(t(W)%*%W%*%H)
end
W = W*max(V%*%t(H) – alphaW JW, 0)/(W%*%H%*%t(H))
H = H*max(t(W)%*%V – alphaH JH, 0)/(t(W)%*%W%*%H)
W = W*((S*V)%*%t(H))/((S*(W%*%H))%*%t(H))
H = H*(t(W)%*%(S*V))/(t(W)%*%(S*(W%*%H)))
Regularizers
JW,JH
Weighted Sq Loss/
Matrix Completion Setting
Parallel implementation is half the story !
Typical application requires experimenting with multiple variants
W = W*(V/(W%*%H) %*% t(H))/(E*%t(H))
CCCCoooommmmpppplllleeeexxxxiiiittttyyyy
In implementation
H = H*(t(W)%*%(V/(W%*%H)))/(t(W)%*%E)](https://image.slidesharecdn.com/2014-140925134140-phpapp02/85/The-Power-of-Declarative-Analytics-13-320.jpg)


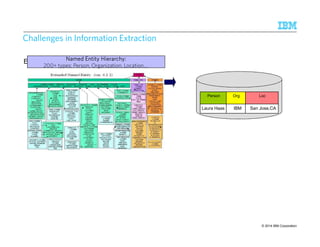
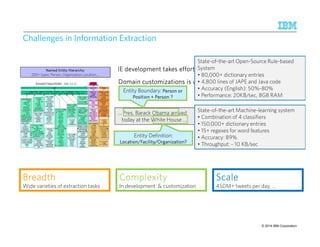
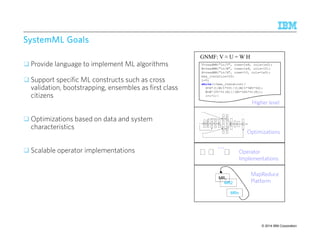
![SSSSttttaaaatttteeee-ooooffff-tttthhhheeee-aaaarrrrtttt:::: CCCCoooommmmmmmmoooonnnn PPPPaaaatttttttteeeerrrrnnnn SSSSppppeeeecccciiiiffffiiiiccccaaaattttiiiioooonnnn LLLLaaaannnngggguuuuaaaaggggeeee ((((CCCCPPPPSSSSLLLL))))
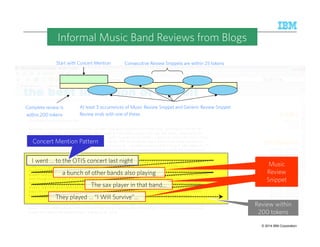
A common language to specify and represent extraction rules as cascading grammars
Developed jointly between SRI and Department of Defense (1999)
Example Rule: Band Member name followed within 5 tokens by Instrument clue is a Music Review Snippet
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. Aliquam erat volutpat. augue rutrum
lorem velit, sed RRRReeeevvvviiiieeeewwwwSSSSnnnniiiippppppppeeeetttt, hendrerit faucibus pede mi sed ipsum. Curabitur cursus tincidunt orci.
Pellentesque justo tellus , scelerisque quis, facilisis quis, interdum non, ante. Suspendisse feugiat, erat
〈BandMember〉 〈Token〉{0,5} 〈Instrument〉〈MusicReviewSnippet〉
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. luctus, risus in sagittis
facilisis BBBBaaaannnnddddMMMMeeeemmmmbbbbeeeerrrr tttthhhheeeeiiiirrrr lllleeeeaaaadddd vvvvooooccccaaaallll////IIIInnnnssssttttrrrruuuummmmeeeennnntttt hendrerit faucibus pede mi ipsum.
Curabitur cursus tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis quis,
Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
Proin JJJJoooonnnn FFFFoooorrrreeeemmmmaaaannnn tttthhhheeeeiiiirrrr lllleeeeaaaadddd vvvvooooccccaaaallll////
IIIInnnnssssttttrrrruuuummmmeeeennnntttt arcu tincidunt
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin in
sagittis , BBBBaaaannnnddddMMMMeeeemmmmbbbbeeeerrrr tttthhhheeeeiiiirrrr lllleeeeaaaadddd
vvvvooooccccaaaallll////gggguuuuiiiittttaaaarrrriiiisssstttt rutrum velit sed amet lt arcu tincidunt
〈〈Token〉[~ “([A-Z]w+)s+[A-Z]w+”] 〈BandMember〉〉 〈Token〉[~ “pipe | guitarist | …”] 〈Instrument〉
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Proin elementum neque at justo. Aliquam erat volutpat. Curabitur
risus in sagittis facilisis JJJJoooonnnn FFFFoooorrrreeeemmmmaaaannnn tttthhhheeeeiiiirrrr lllleeeeaaaadddd vvvvooooccccaaaallll////gggguuuuiiiittttaaaarrrriiiisssstttt hendrerit faucibus pede mi ipsum.
Curabitur cursus tincidunt orci. Pellentesque justo tellus , scelerisque quis, facilisis quis,
LLLLeeeevvvveeeellll 2222
LLLLeeeevvvveeeellll 1111
LLLLeeeevvvveeeellll 0000
© 2014 21 9/10/2014 IBM Research – Almaden IBM Corporation](https://image.slidesharecdn.com/2014-140925134140-phpapp02/85/The-Power-of-Declarative-Analytics-21-320.jpg)
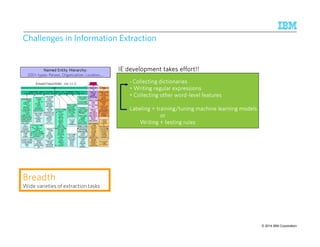
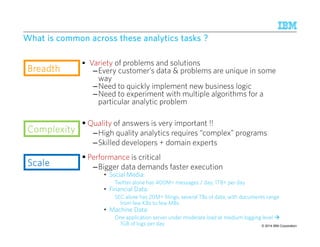
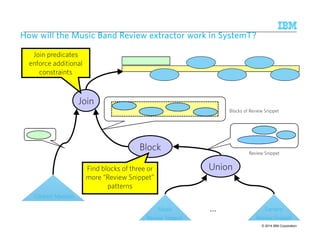
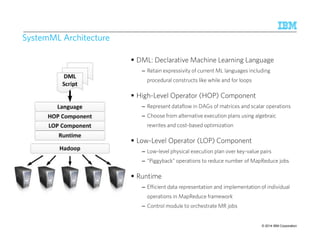
![WWWWhhhhyyyy iiiissss tttthhhhiiiissss nnnnooootttt ssssuuuuffffffffiiiicccciiiieeeennnntttt ????
Consecutive Review Snippets are within 25 tokens
Start with Concert Mention
At least 3 occurrences of Music Review Snippet or Generic Review Snippet
Review ends with one of these.
Complete review is
within 200 tokens
Counting and aggregations are not natural primitives in grammar and have to be handled in
custom code [Chiticariu, ACL 2010]
Finely tuned grammar-based extraction system, with custom code for counting and
aggregation, took ~ 6 hours to extract reviews from a million web logs
© 2014 22 9/10/2014 IBM Research – Almaden IBM Corporation](https://image.slidesharecdn.com/2014-140925134140-phpapp02/85/The-Power-of-Declarative-Analytics-22-320.jpg)
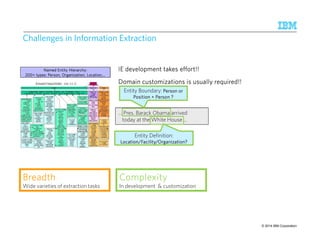
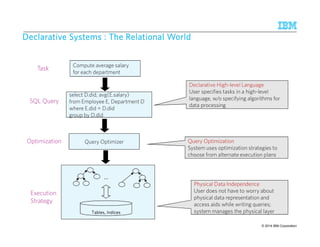
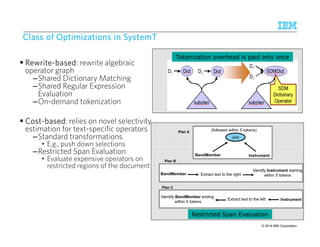
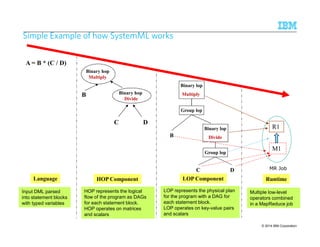
![SSSSyyyysssstttteeeemmmmTTTT – DDDDeeeeccccllllaaaarrrraaaattttiiiivvvveeee AAAApppppppprrrrooooaaaacccchhhh ttttoooo IIIInnnnffffoooorrrrmmmmaaaattttiiiioooonnnn EEEExxxxttttrrrraaaaccccttttiiiioooonnnn
Annotated
Document
Stream
AQL SystemT
Optimizer
SystemT
Runtime
Compiled
Operator
Graph
Rule language with
familiar SQL-like syntax
Specify annotator
semantics declaratively
Choose an efficient
execution plan that
implements the
semantics
Highly scalable,
embeddable Java
runtime
Input
Document
Stream
See SIGMOD 2010 tutorial [Chiticariu et al., 2010]
for details on other recent declarative IE systems
© 2014 23 9/10/2014 IBM Research – Almaden IBM Corporation](https://image.slidesharecdn.com/2014-140925134140-phpapp02/85/The-Power-of-Declarative-Analytics-23-320.jpg)
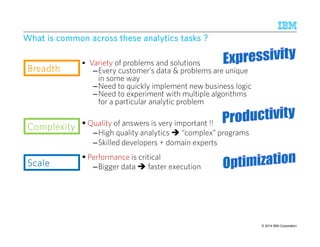
![Expressing Music Review Snippet Rule in AQL
BandMember Instrument
0-5 tokens
create view MusicReviewSnippet as
select B.name as member, I.value as instrument,
CombineSpans(B.name,I.value) as review
from BandMember B, Instrument I
where FollowsTok(B.name, I.value, 0, 5);
create view BandMember as
extract regex /[A-Z]w+s+[A-Z]w+] / on D.text
from Document D;
Choice of SQL-like syntax for AQL motivated by wider adoption of SQL
© 2014 24 9/10/2014 IBM Research – Almaden IBM Corporation](https://image.slidesharecdn.com/2014-140925134140-phpapp02/85/The-Power-of-Declarative-Analytics-24-320.jpg)

![© 2014 IBM Corporation
Performance benefits using SystemT
[Chiticariu et al. ACL’10]
Music Band Review extraction task over a million web logs
– SystemT vs. the grammar implementation
• 10 minutes vs. ~ 6 hours
Named-entity extraction task over multiple document corpora
– SystemT throughput ranges from 400 – 900 KB/sec/core (depending on the size of
the document)
– SystemT vs. State-of-the-Art Learning-based System [Florian et al, CoNLL’03]
~ 50 times higher throughput
– SystemT vs. State-of-the-Art Grammar-based System [ANNIE, Cunningham et al,
ACL’02]
~ 10 - 50 times higher throughput
~ 60 - 90% less memory consumption
Revisiting the Twitter example, for keeping up with today’s tweets with 18 cores
– SystemT takes 30 minutes per day as opposed to running 24/7 for the state-of-the-art
system](https://image.slidesharecdn.com/2014-140925134140-phpapp02/85/The-Power-of-Declarative-Analytics-28-320.jpg)
![Runs fast ! But is SystemT expressive enough to compare on quality ?
[Chiticariu et al. ACL’10, EMNLP’10]
SystemT outperforms current best results on multiple benchmark datasets
– CoNLL 2003
• F-measure between 89% and 92% for Person, Organization and Location
tasks
• Beats the state-of-the-art results consistently by up to 4%
– Enron Email
• F-measure 85% for Person task
• Better than the state-of-the-art result by 7%
© 2014 29 9/10/2014 IBM Research – Almaden IBM Corporation](https://image.slidesharecdn.com/2014-140925134140-phpapp02/85/The-Power-of-Declarative-Analytics-29-320.jpg)






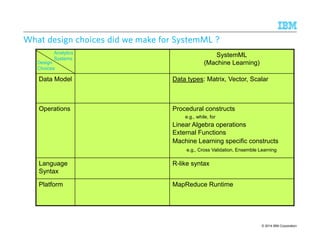


![Maintenance
© 2014 IBM Corporation
Tooling Research for the Development Life-Cycle
Development
[ACL’11,12,13,CHI’13]
Develop
Analyze Test
Deploy
Refine
Test
Task Analysis
• Concordance Viewer
• Active labeling
• Labeling tool
• Extraction plan
• Track provenance [VLDB’10]
• Contextual clue discovery[CIKM’11]
• Regex learning [EMNLP’08]
• Suggest rule changes [VLDB’10]
• Rule induction [EMNLP’12]
• Dictionary refinement [SIGMOD’13]
• Rule learning
• NE Interface [EMNLP’10]
• Tagger UI [SIGMOD’07]](https://image.slidesharecdn.com/2014-140925134140-phpapp02/85/The-Power-of-Declarative-Analytics-43-320.jpg)



The document discusses the challenges and advancements in declarative analytics, particularly within IBM's systems for information extraction and machine learning. It outlines case studies in sentiment analysis in banking, drug discovery, and water cost indexing, highlighting the importance of data-driven decision-making. The presentation emphasizes the complexities involved in data extraction and the significance of high-quality analytics in handling big data efficiently.























































































