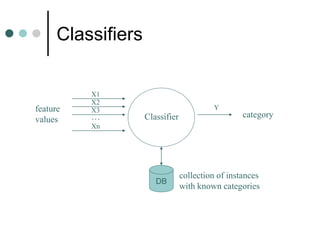
This document discusses supervised learning and the k-nearest neighbors (kNN) classification algorithm. kNN works by finding the k training instances nearest to a new instance, and predicting the new instance's class based on the classes of its neighbors. The document covers how kNN handles numeric and non-numeric data, different distance measures, preprocessing data, variations of kNN, and its time complexity of O(mn) for m instances and n features.









































![k-nearestneighborknn-231215171119-a5cfb915.pptx [Read-Only].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/k-nearestneighborknn-231215171119-a5cfb915-251010013925-09814a4b-thumbnail.jpg?width=640&height=640&fit=bounds)




















