














![19
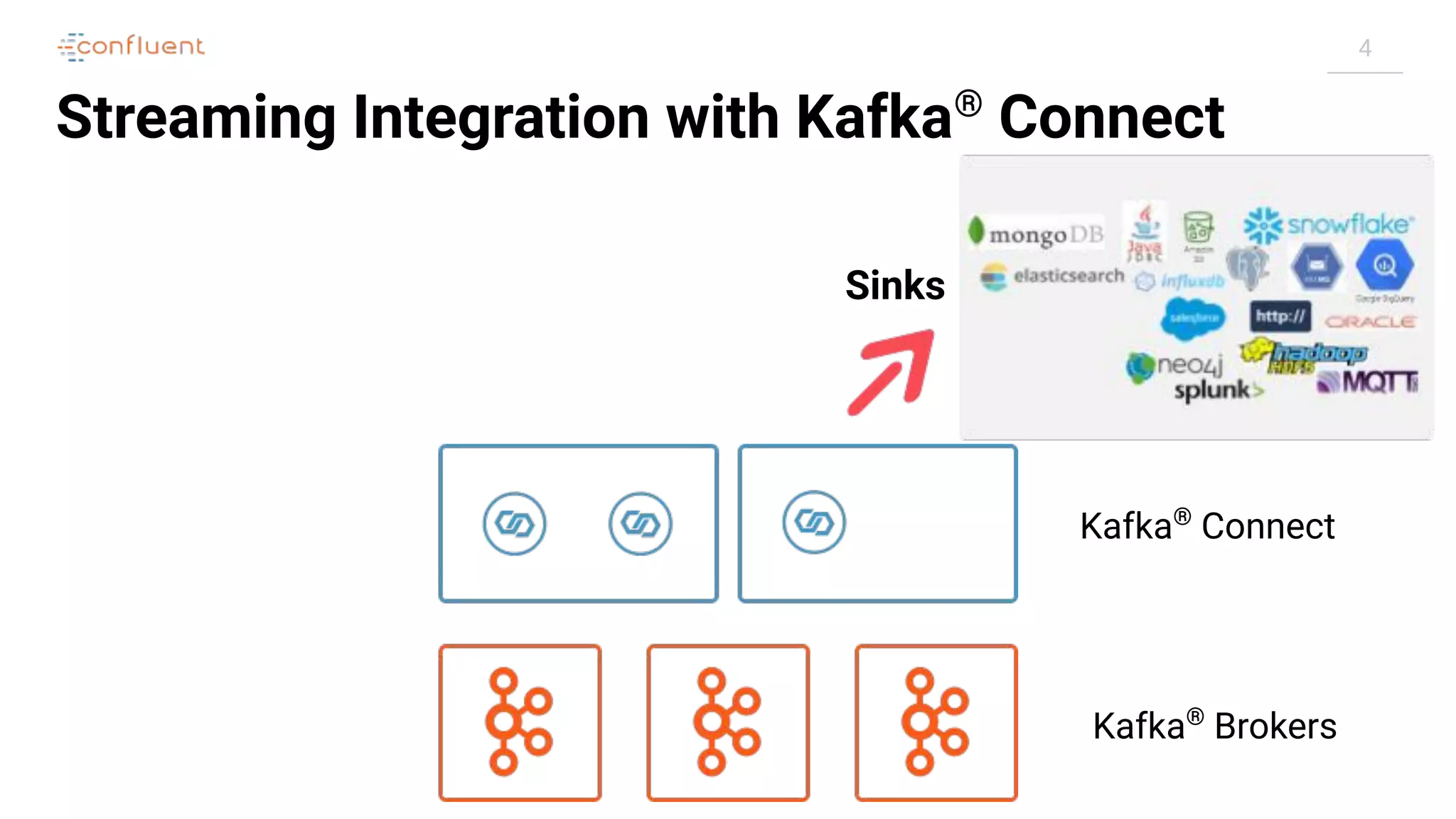
Connectors
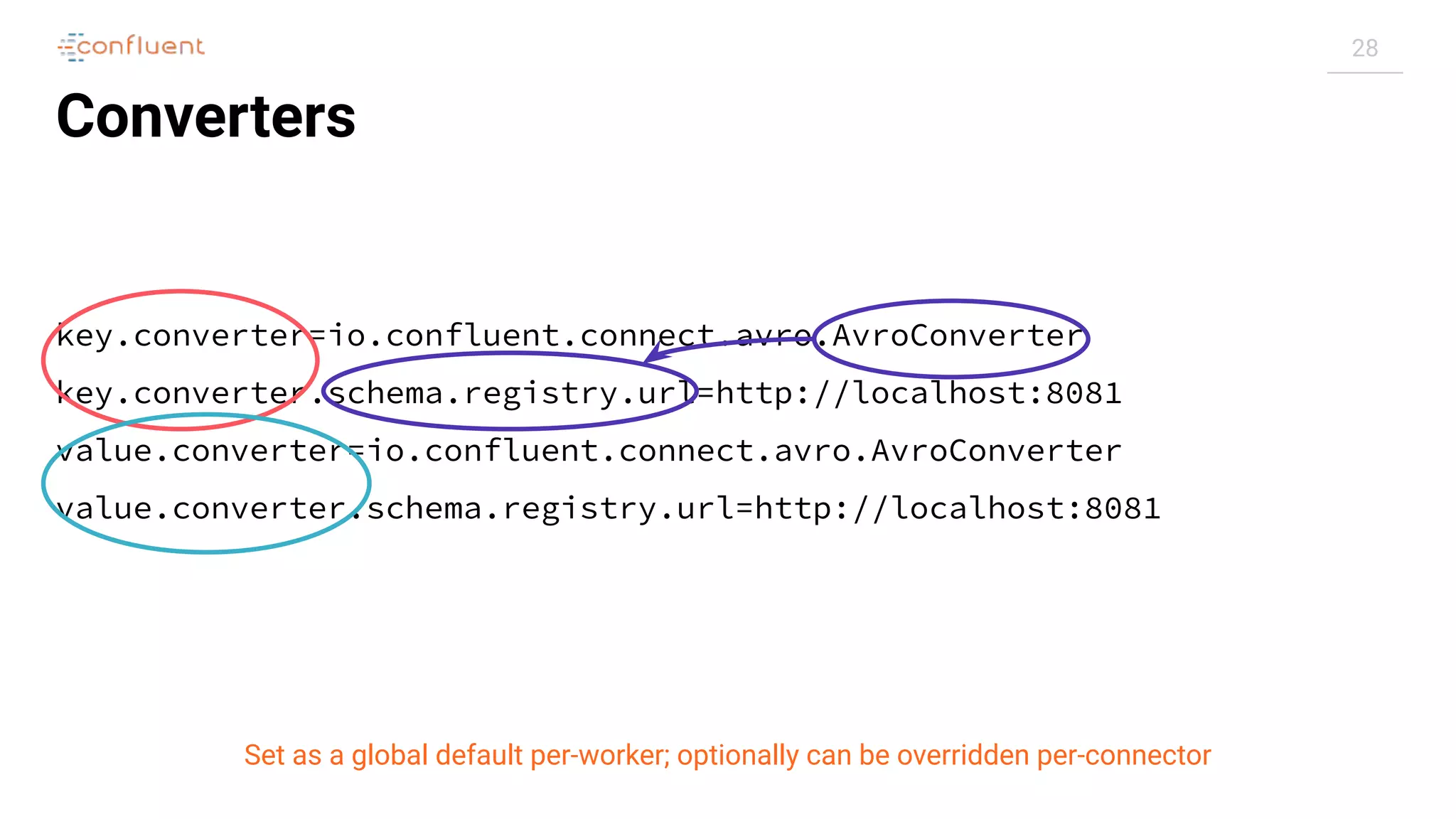
"config": {
[...]
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:postgresql://postgres:5432/",
"topics": "asgard.demo.orders",
}](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-19-2048.jpg)

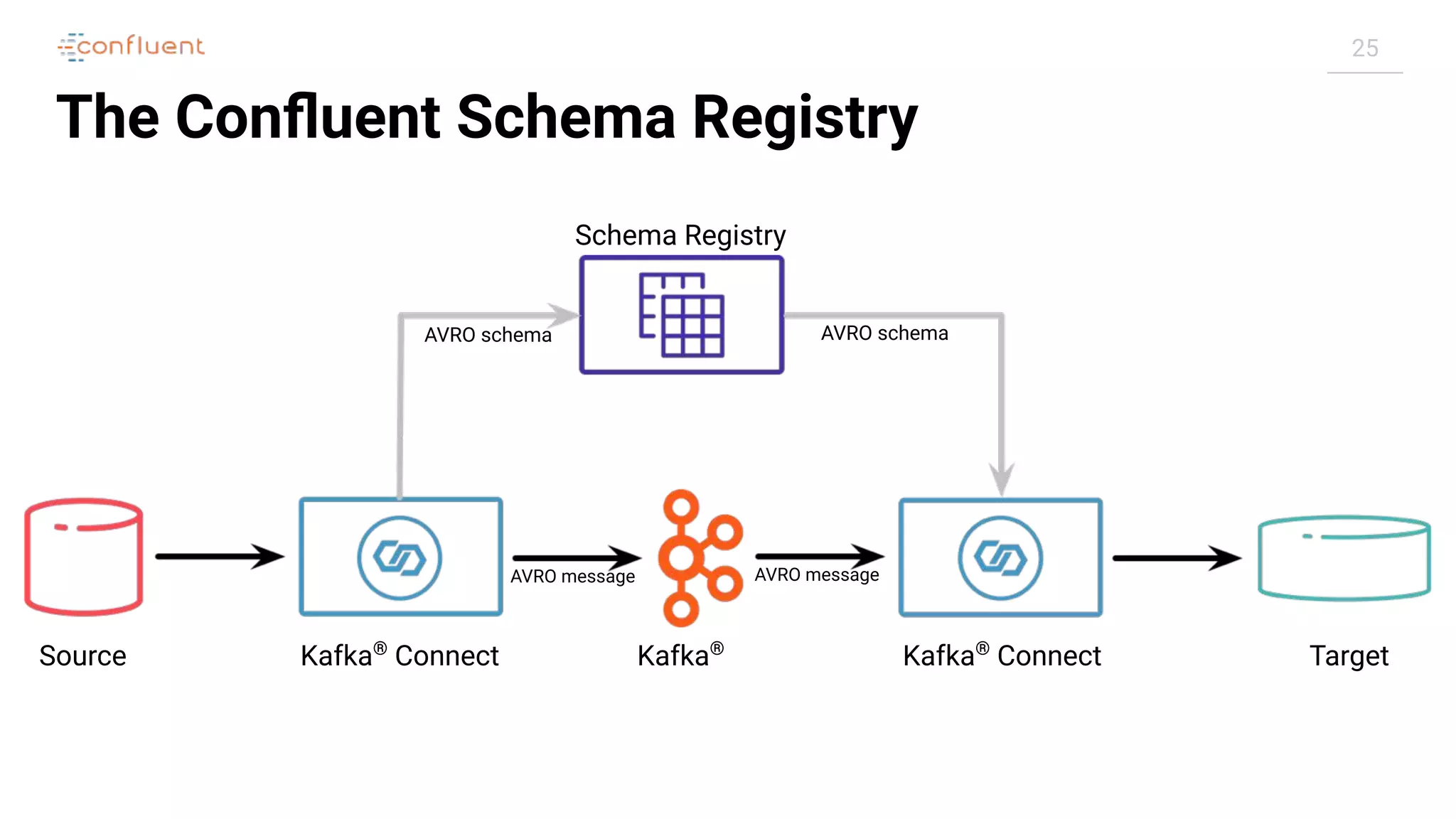
![21
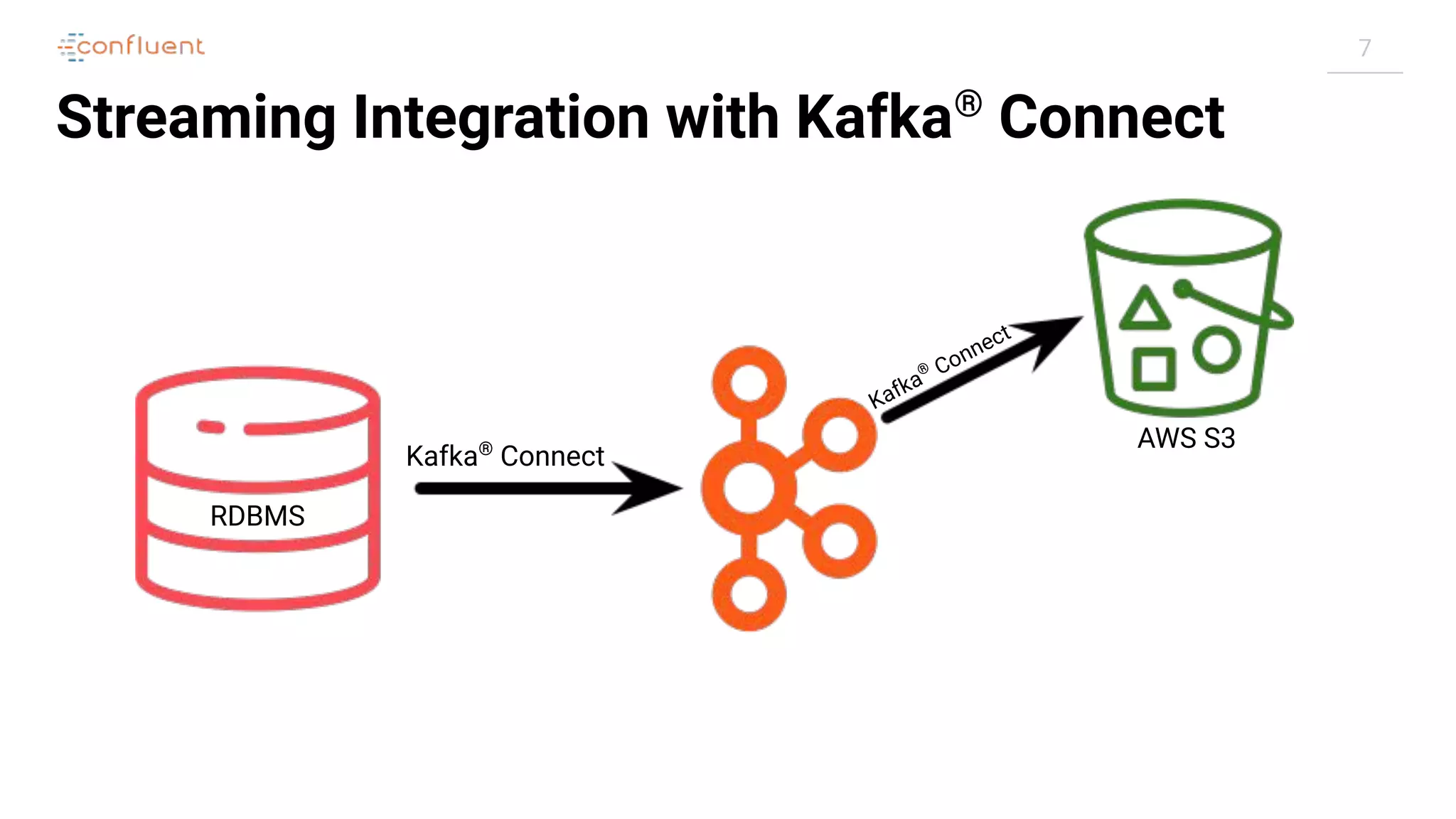
Converters
Source Kafka®
Connect Kafka®
Connector
Native Data Connect Record
Converter
Bytes[ ]](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-21-2048.jpg)






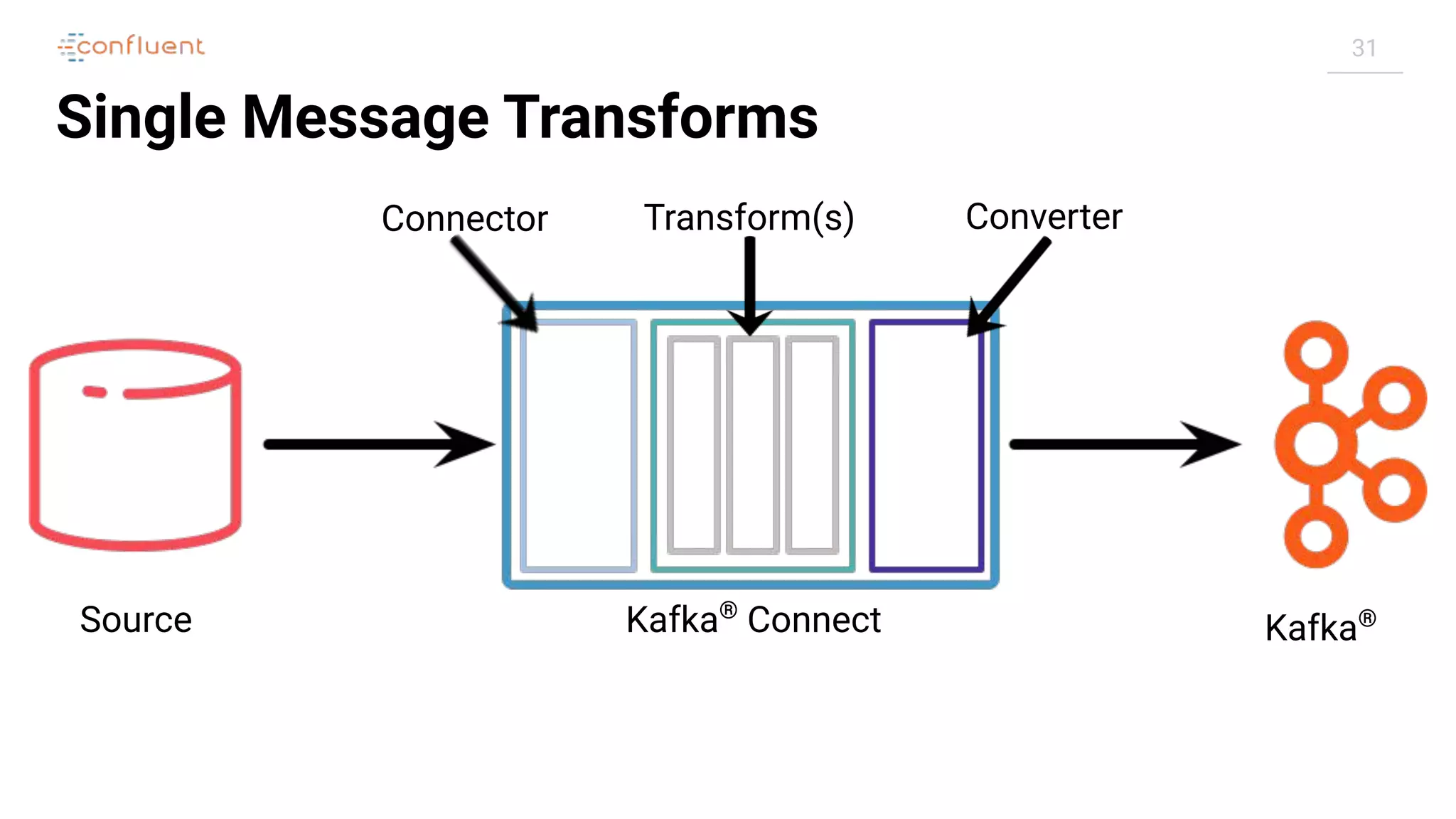
![32
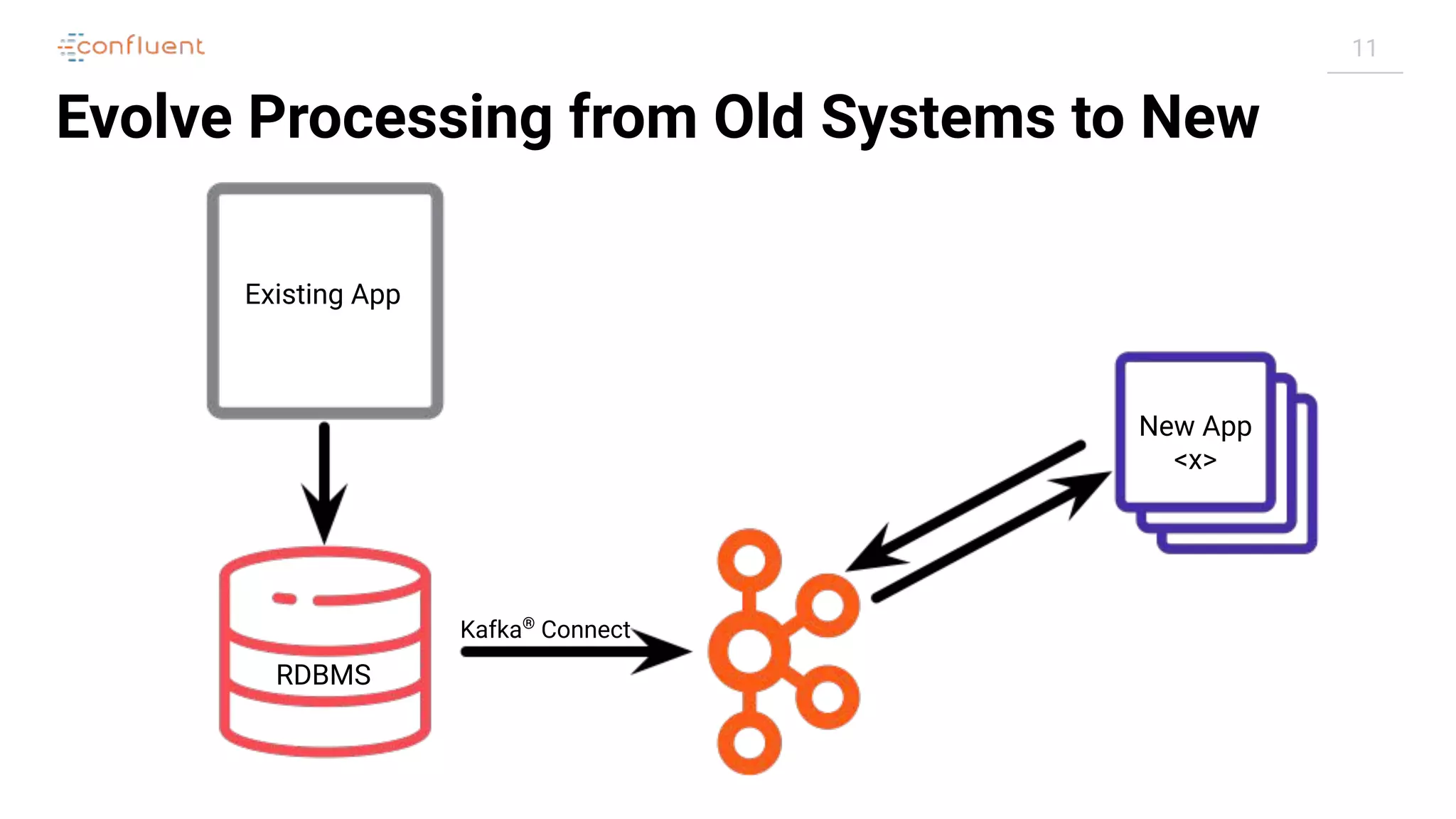
Single Message Transforms
"config": {
[...]
"transforms": "addDateToTopic,labelFooBar",
"transforms.addDateToTopic.type": "org.apache.kafka.connect.transforms.TimestampRouter",
"transforms.addDateToTopic.topic.format": "${topic}-${timestamp}",
"transforms.addDateToTopic.timestamp.format": "YYYYMM",
"transforms.labelFooBar.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.labelFooBar.renames": "delivery_address:shipping_address",
}](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-32-2048.jpg)
![33
Single Message Transforms
"config": {
[...]
"transforms": "addDateToTopic,labelFooBar",
"transforms.addDateToTopic.type": "org.apache.kafka.connect.transforms.TimestampRouter",
"transforms.addDateToTopic.topic.format": "${topic}-${timestamp}",
"transforms.addDateToTopic.timestamp.format": "YYYYMM",
"transforms.labelFooBar.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.labelFooBar.renames": "delivery_address:shipping_address",
}
Transforms config](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-33-2048.jpg)
![34
Single Message Transforms
"config": {
[...]
"transforms": "addDateToTopic,labelFooBar",
"transforms.addDateToTopic.type": "org.apache.kafka.connect.transforms.TimestampRouter",
"transforms.addDateToTopic.topic.format": "${topic}-${timestamp}",
"transforms.addDateToTopic.timestamp.format": "YYYYMM",
"transforms.labelFooBar.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.labelFooBar.renames": "delivery_address:shipping_address",
}
Apply these transforms
Transforms config](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-34-2048.jpg)
![35
Single Message Transforms
"config": {
[...]
"transforms": "addDateToTopic,labelFooBar",
"transforms.addDateToTopic.type": "org.apache.kafka.connect.transforms.TimestampRouter",
"transforms.addDateToTopic.topic.format": "${topic}-${timestamp}",
"transforms.addDateToTopic.timestamp.format": "YYYYMM",
"transforms.labelFooBar.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.labelFooBar.renames": "delivery_address:shipping_address",
}
Apply these transforms
Transforms config Config per Transform](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-35-2048.jpg)



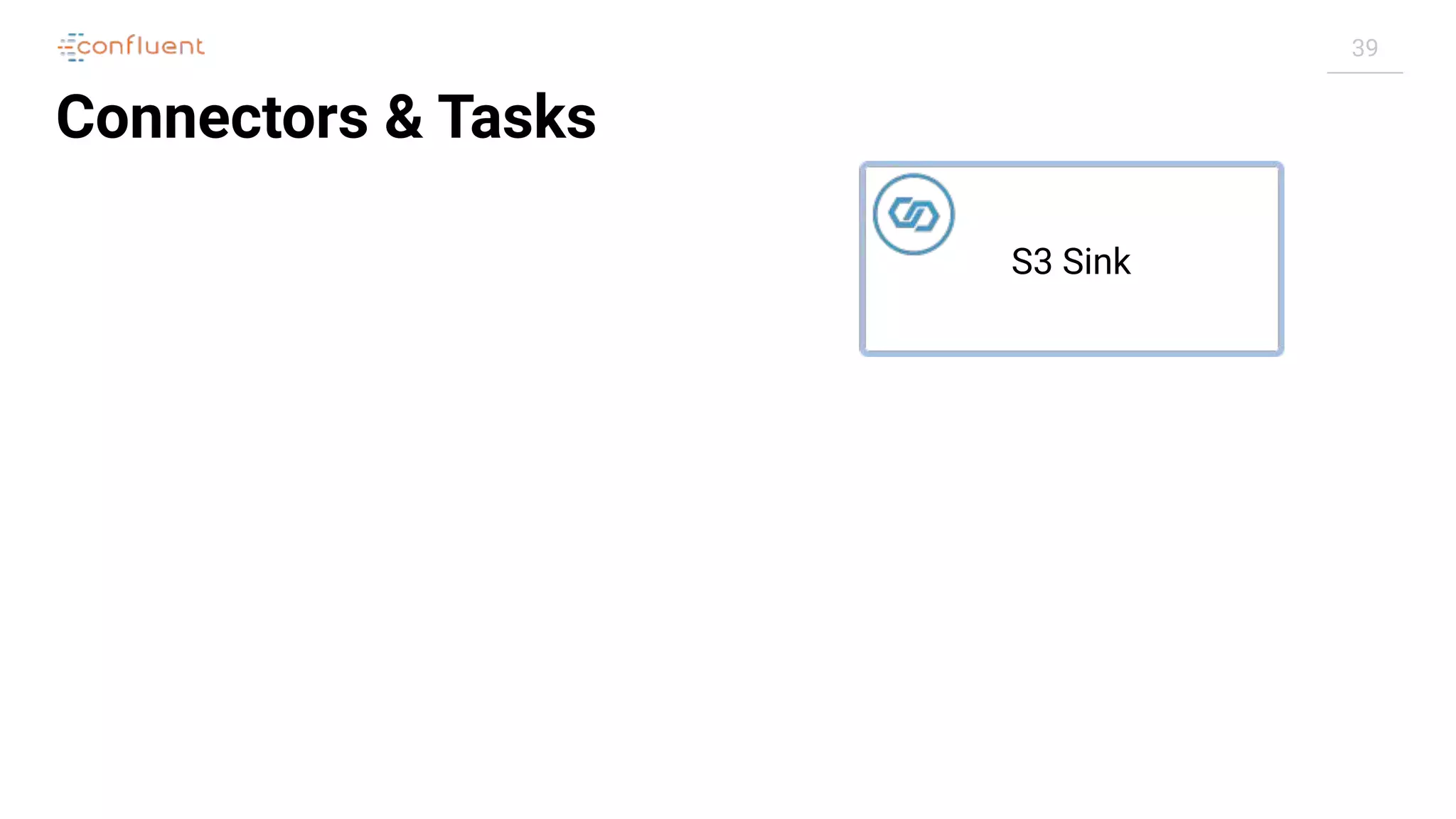
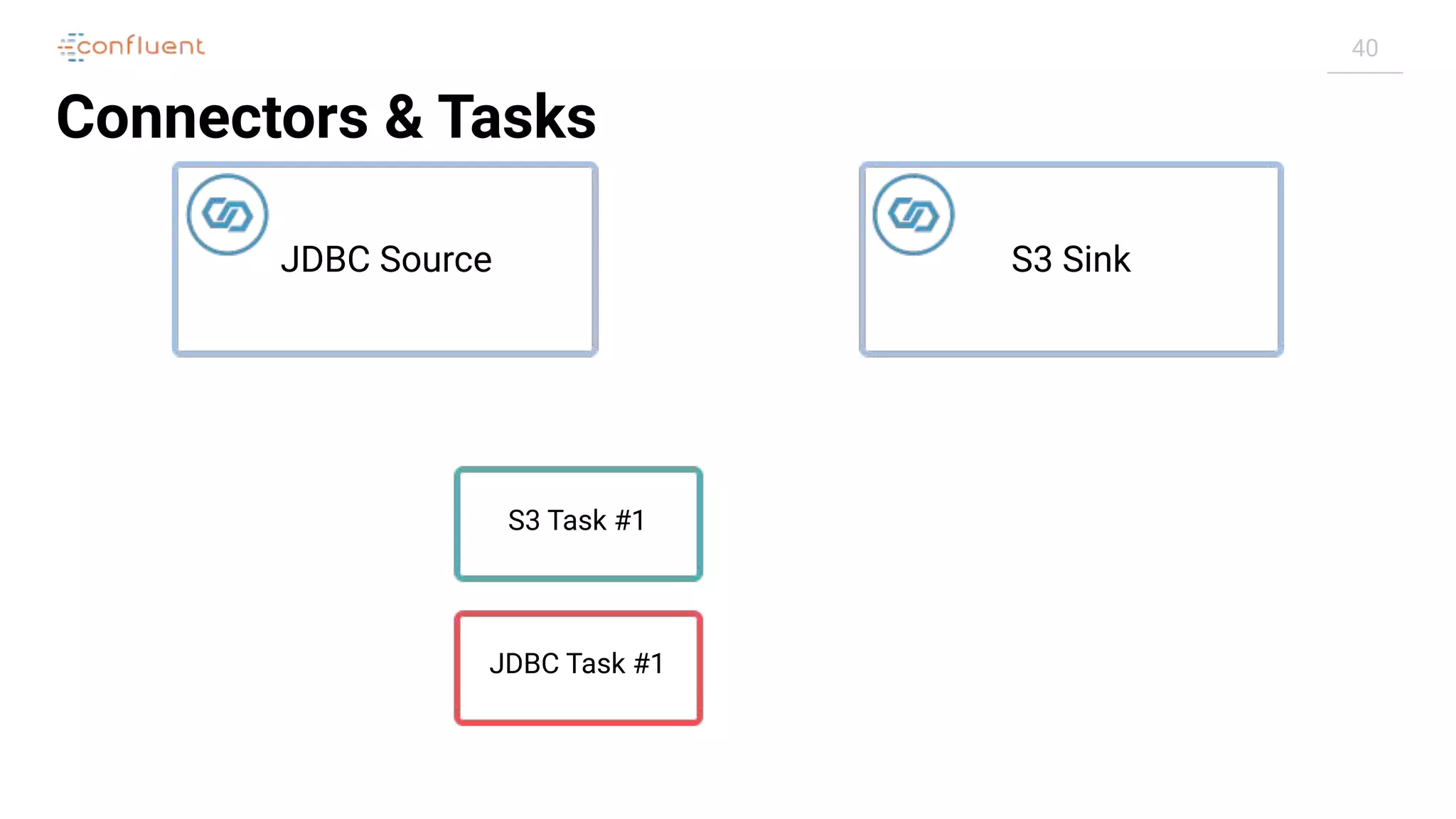










![51
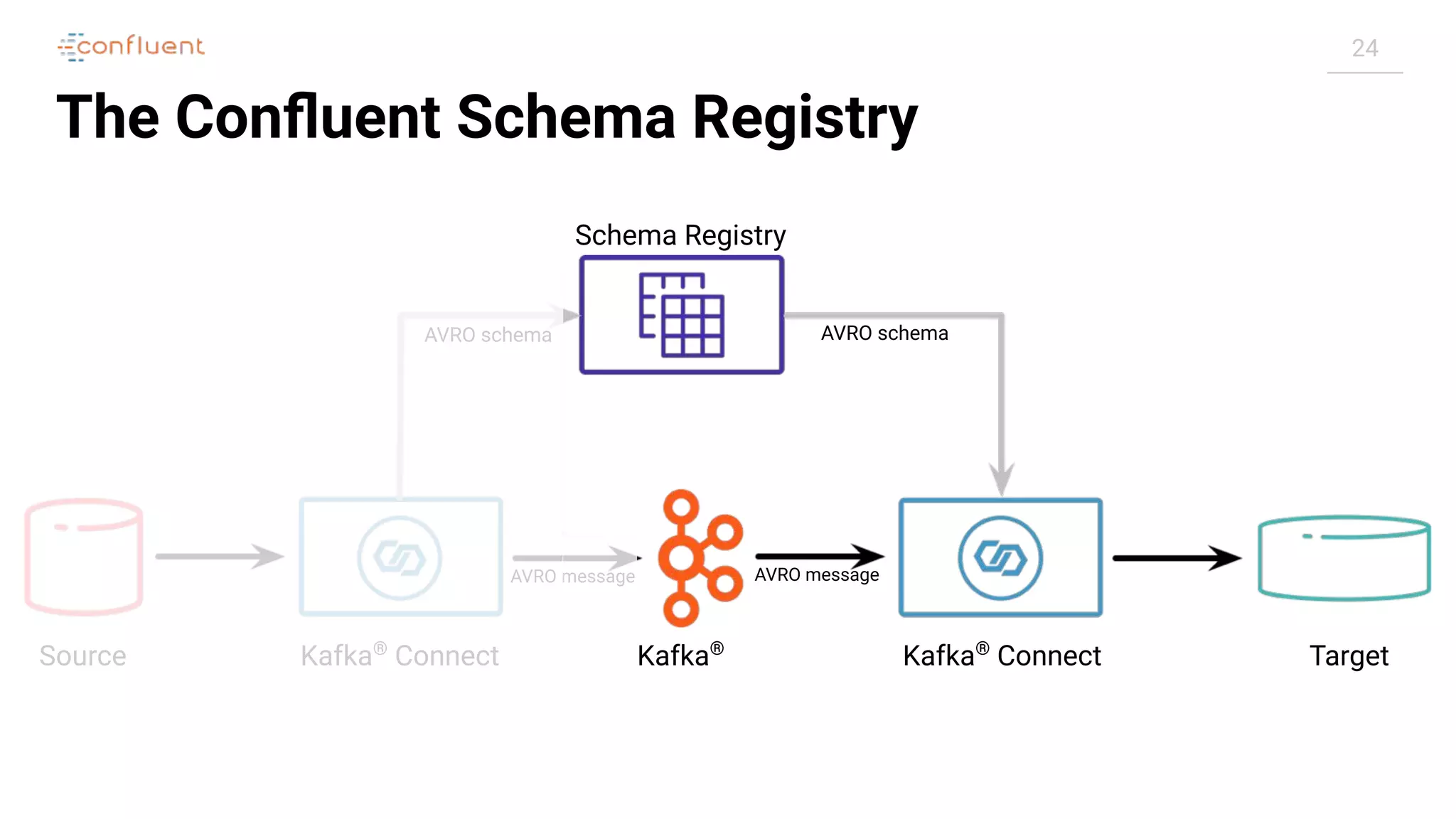
Troubleshooting Kafka®
Connect
Task
Connector
RUNNING
FAILED
$ curl -s "http://localhost:8083/connectors/source-debezium-orders/status" |
jq '.connector.state'
"RUNNING"
$ curl -s "http://localhost:8083/connectors/source-debezium-orders/status" |
jq '.tasks[0].state'
"FAILED"](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-51-2048.jpg)
![52
Troubleshooting Kafka®
Connect
$curl -s "http://localhost:8083/connectors/source-debezium-orders-00/status" | jq '.tasks[0].trace'
"org.apache.kafka.connect.errors.ConnectExceptionntat
io.debezium.connector.mysql.AbstractReader.wrap(AbstractReader.java:230)ntat
io.debezium.connector.mysql.AbstractReader.failed(AbstractReader.java:197)ntat
io.debezium.connector.mysql.BinlogReader$ReaderThreadLifecycleListener.onCommunicationFailure(BinlogReader.java:
1018)ntat com.github.shyiko.mysql.binlog.BinaryLogClient.listenForEventPackets(BinaryLogClient.java:950)ntat
com.github.shyiko.mysql.binlog.BinaryLogClient.connect(BinaryLogClient.java:580)ntat
com.github.shyiko.mysql.binlog.BinaryLogClient$7.run(BinaryLogClient.java:825)ntat
java.lang.Thread.run(Thread.java:748)nCaused by: java.io.EOFExceptionntat
com.github.shyiko.mysql.binlog.io.ByteArrayInputStream.read(ByteArrayInputStream.java:190)ntat
com.github.shyiko.mysql.binlog.io.ByteArrayInputStream.readInteger(ByteArrayInputStream.java:46)ntat
com.github.shyiko.mysql.binlog.event.deserialization.EventHeaderV4Deserializer.deserialize(EventHeaderV4Deserial
izer.java:35)ntat
com.github.shyiko.mysql.binlog.event.deserialization.EventHeaderV4Deserializer.deserialize(EventHeaderV4Deserial
izer.java:27)ntat
com.github.shyiko.mysql.binlog.event.deserialization.EventDeserializer.nextEvent(EventDeserializer.java:212)nt
at io.debezium.connector.mysql.BinlogReader$1.nextEvent(BinlogReader.java:224)ntat
com.github.shyiko.mysql.binlog.BinaryLogClient.listenForEventPackets(BinaryLogClient.java:922)nt... 3 moren"](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-52-2048.jpg)








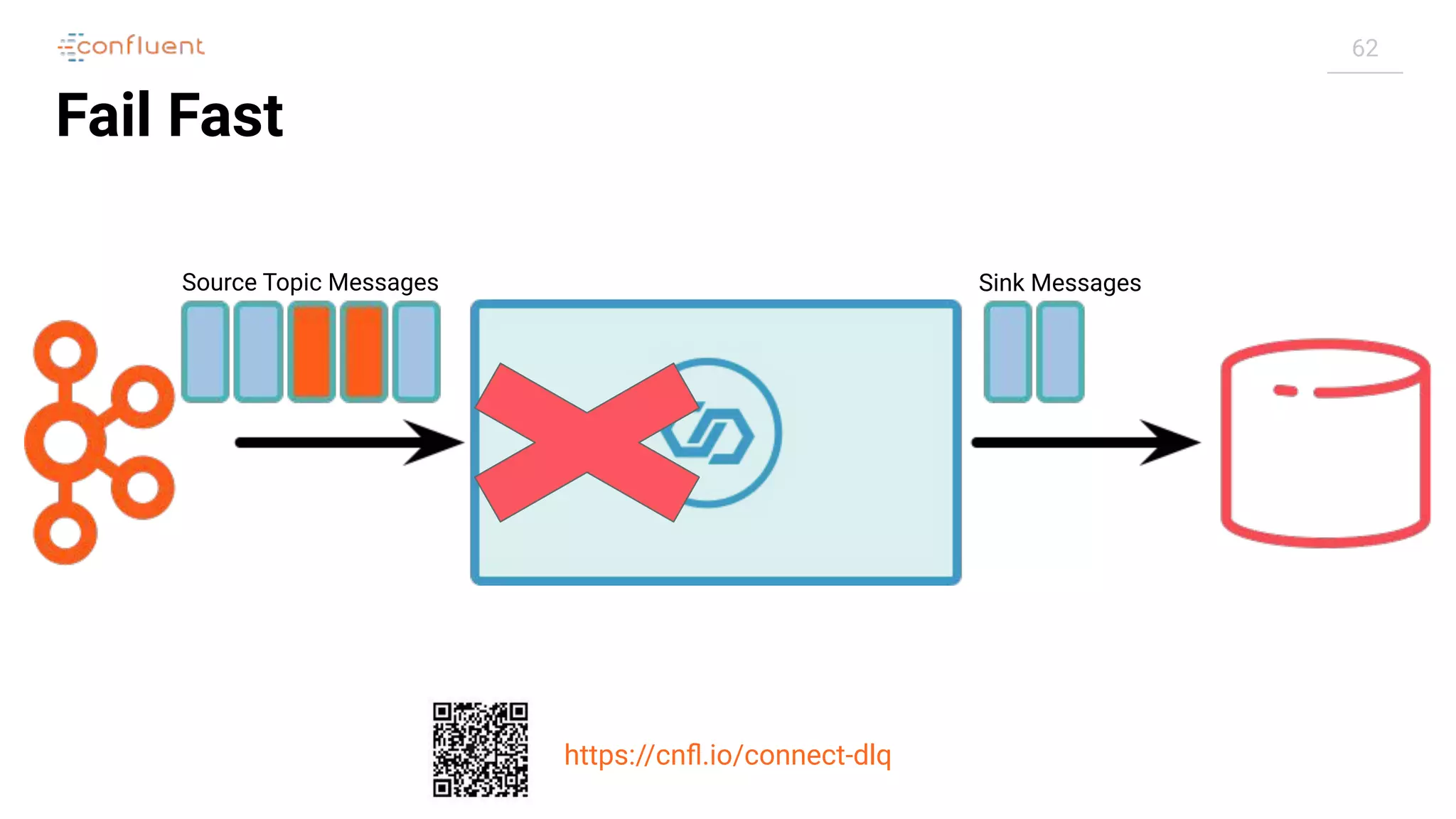
![61
Error Handling & Dead Letter Queues (DLQ)
https://cnfl.io/connect-dlq
Handled
● Convert (read/write from
Kafka®, [de]-serialisation)
● Transform
Not Handled
● Start (connections to a Data
Store)
● Poll / Put (read/write from/to
Data Store)*
* Can be retried by Kafka® Connect](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-61-2048.jpg)




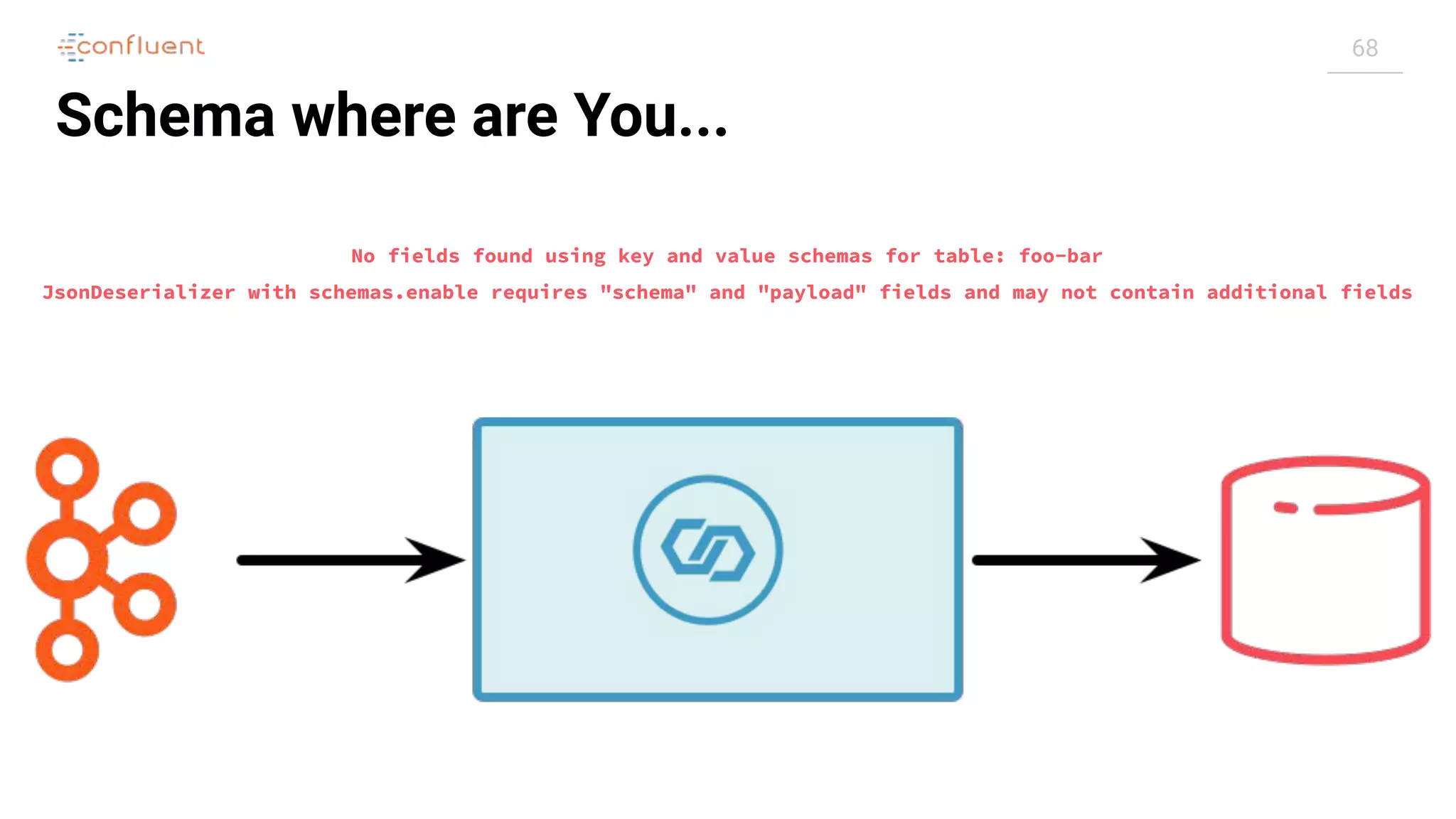
![69
Schema where are You...
$ http localhost:8081/subjects[...]
jq '.schema|fromjson'
{
"type": "record",
"name": "Value",
"namespace": "asgard.demo.ORDERS",
"fields": [
{
"name": "id",
"type": "int"
},
{
"name": "order_id",
"type": [
"null",
"int"
],
"default": null
},
{
"name": "customer_id",
"type": [
"null",
"int"
],
"default": null
},
$ kafkacat -b localhost:9092 -C -t mysql-debezium-asgard.demo.ORDERS
QF@Land RoverDefender 90SheffieldSwift LLC,54258 Michigan
Parkway(2019-05-09T13:42:28Z(2019-05-09T13:42:28Z
Schema
(from Schema Registry)
Messages
(AVRO)](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-69-2048.jpg)


![72
Schema where are You...
Schema
(Embedded per
JSON message)
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
[...]
],
"optional": true,
"name": "asgard.demo.ORDERS.Value"
},
"payload": {
"id": 611,
"order_id": 111,
"customer_id": 851,
"order_total_usd": 182190.93,
"make": "Kia",
"model": "Sorento",
"delivery_city": "Swindon",
"delivery_company": "Lehner,
Kuvalis and Schaefer",
"delivery_address": "31 Cardinal
Junction",
"CREATE_TS":
"2019-05-09T13:54:59Z",
"UPDATE_TS": "2019-05-09T13:54:59Z"
}
Messages
(JSON)
JsonDeserializer with schemas.enable requires "schema" and "payload" fields and may not contain additional fields](https://image.slidesharecdn.com/apachekafkameetupzurichatswissrefromzerotoherowithkafkaconnect20190826v01-190827124450/75/Apache-kafka-meet_up_zurich_at_swissre_from_zero_to_hero_with_kafka_connect_20190826v01-72-2048.jpg)




This document provides an overview of Kafka Connect and how it can be used to stream data between Kafka and other data systems. It discusses key Kafka Connect concepts like connectors, converters, transforms, deployment modes, and troubleshooting. The document contains configuration examples for connectors and transforms.











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











