Download to read offline


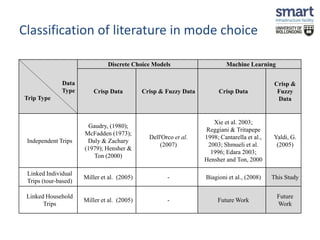
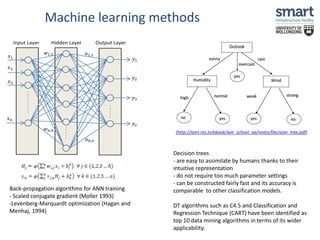
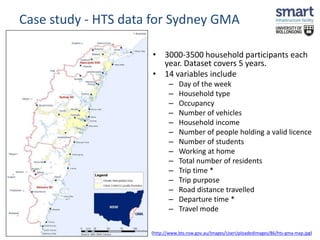

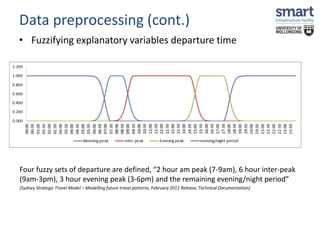
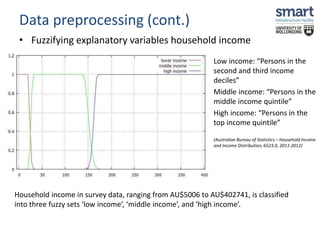
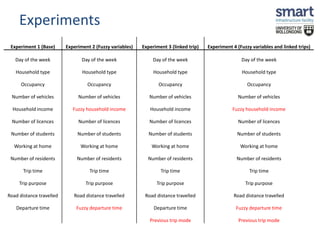
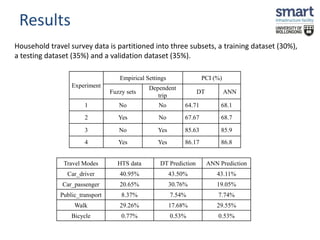



This document discusses a study on estimating travel mode choices using data mining and fuzzy techniques, focusing on household trips in Sydney. It details the methodology involving artificial neural networks and decision trees, incorporating fuzzy sets for certain variables to enhance predictive accuracy. The results indicate that incorporating fuzzy and tour-based models outperforms traditional crisp data approaches in predicting travel modes.




















































































