
Download as PDF, PPTX






![Node
CPU
(Core)
CPU
(Thread)
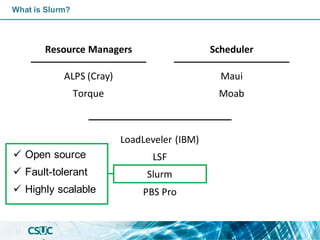
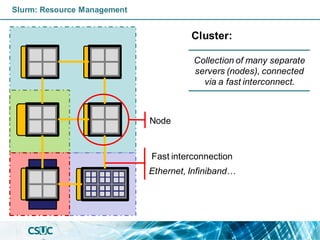
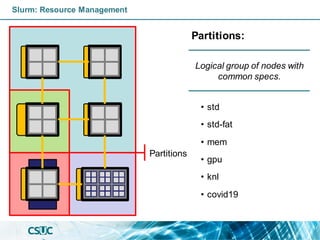
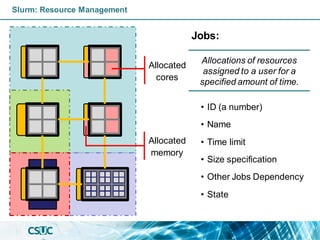
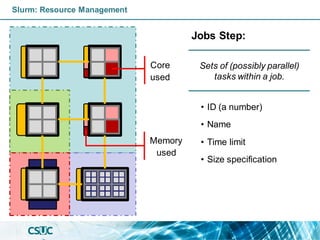
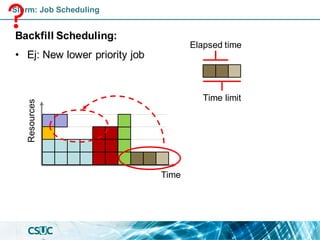
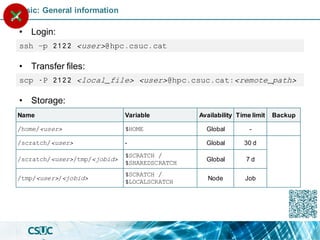
Slurm: Resource Management
Nodes:
• pirineus[1-44]
• pirineus[45-50]
• canigo[1,2]
• pirineusgpu[1-4]
• pirineusknl[1-4]
GPGPU
(GRES)
Individual computer
component of an HPC
system.](https://image.slidesharecdn.com/formacioslurm-211217092552/85/Introduction-to-SLURM-8-320.jpg)



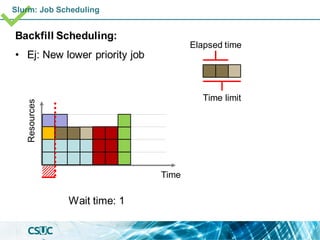



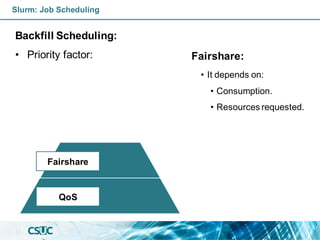

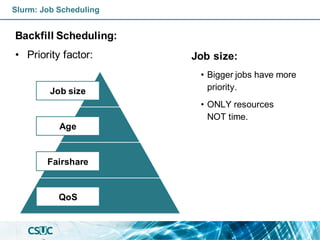

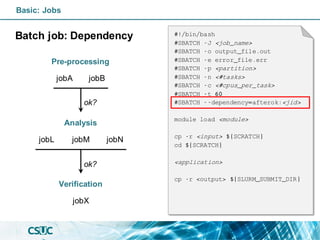
![Basic: Jobs
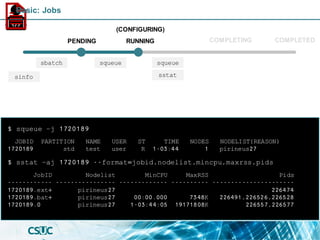
Batch job: Dependency
• after:<jobid>[:<jobid>...]
Start of the specified jobs.
• afterany:<jobid>[:<jobid>...]
Termination of the specified jobs.
• afternotok:<jobid>[:<jobid>...]
Failing of the specified jobs.
• singleton
All jobs with the same name
and user have ended.
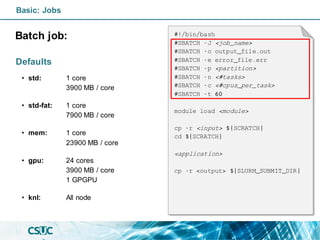
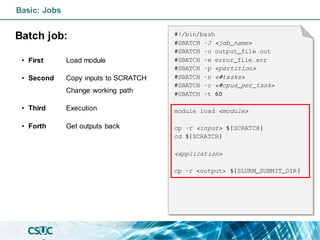
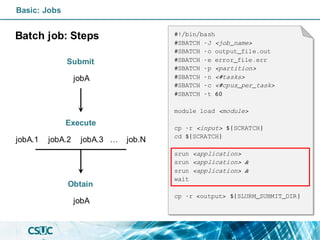
#!/bin/bash
#SBATCH -J <job_name>
#SBATCH -o output_file.out
#SBATCH -e error_file.err
#SBATCH -p <partition>
#SBATCH -n <#tasks>
#SBATCH -c <#cpus_per_task>
#SBATCH -t 60
#SBATCH --dependency=afterok:<jid>
module load <module>
cp -r <input> ${SCRATCH}
cd ${SCRATCH}
<application>
cp -r <output> ${SLURM_SUBMIT_DIR}](https://image.slidesharecdn.com/formacioslurm-211217092552/85/Introduction-to-SLURM-40-320.jpg)
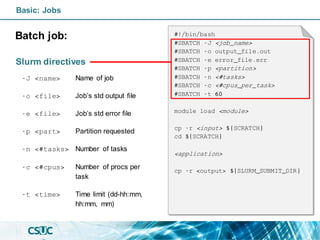
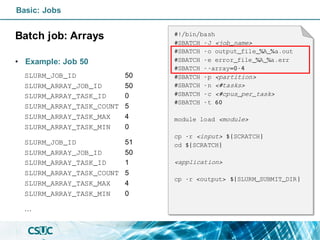
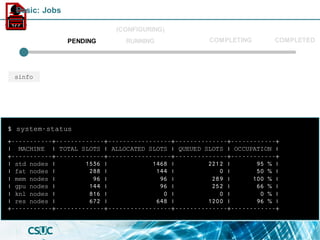
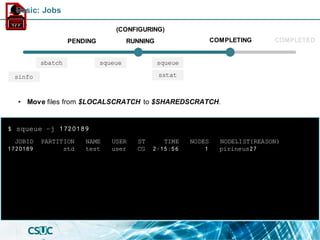
![PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
std* up infinite 19 mix pirineus[7,34-35,37-40,45]
std* up infinite 25 alloc pirineus[8,11-17,19-33,36,41-44,46-50]
std-fat up infinite 1 mix pirineus45
std-fat up infinite 5 alloc pirineus[46-50]
gpu up infinite 4 idle~ pirineusgpu[1-4]
knl up infinite 4 idle~ pirineusknl[1-4]
mem up infinite 2 mix canigo[1-2]
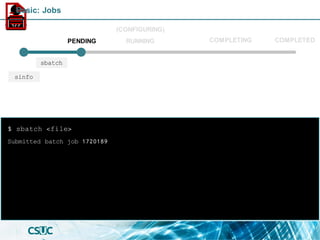
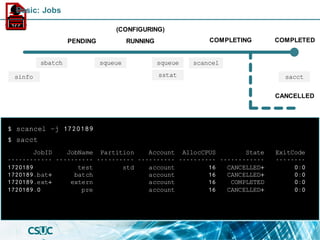
$ sinfo
PENDING
(CONFIGURING)
RUNNING COMPLETED
sinfo
COMPLETING
Basic: Jobs](https://image.slidesharecdn.com/formacioslurm-211217092552/85/Introduction-to-SLURM-42-320.jpg)


The document provides an introduction to SLURM, a resource manager and job scheduler for Linux clusters, detailing its role in managing resources, scheduling jobs, and handling job dependencies. It covers essential SLURM concepts, including clusters, nodes, partitions, job submission, job arrays, and various scheduling techniques. Additionally, it includes examples of batch job scripts, commands, and SLURM directives for efficient job execution.























































































