
Download as PDF, PPTX






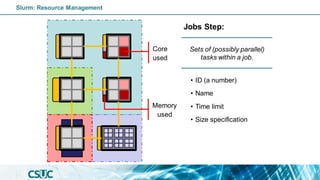
![Node
CPU
(Core)
CPU
(Thread)
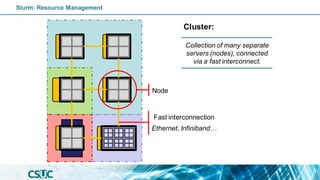
Nodes:
• pirineus[1-6]
• pirineus[7-50]
• pirineus[51-69]
• canigo[1,2]
• pirineusgpu[1-4]
• pirineusknl[1-4]
GPGPU
(GRES)
Individual computer
component of an HPC
system.
Slurm: Resource Management](https://image.slidesharecdn.com/introslurm-221220122340-16fa1314/85/Introduction-to-Slurm-8-320.jpg)


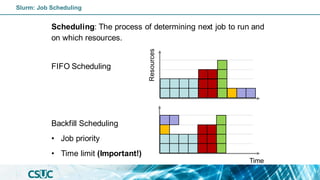
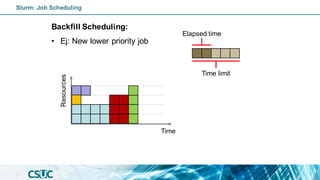
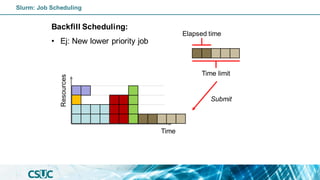
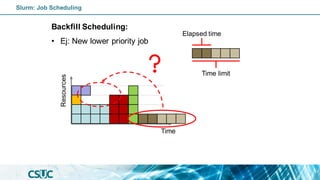
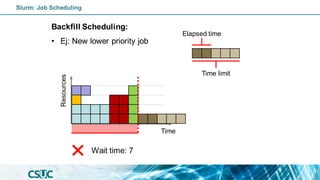
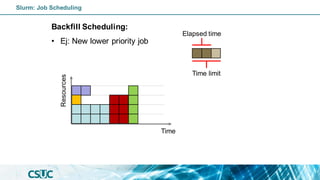



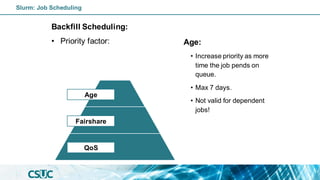
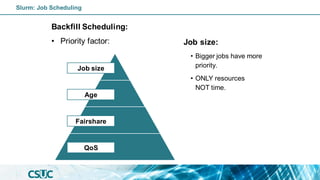


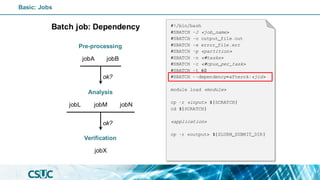
![Batch job: Dependency
• after:<jobid>[:<jobid>...]
Start of the specified jobs.
• afterany:<jobid>[:<jobid>...]
Termination of the specified jobs.
• afternotok:<jobid>[:<jobid>...]
Failing of the specified jobs.
• singleton
All jobs with the same name
and user have ended.
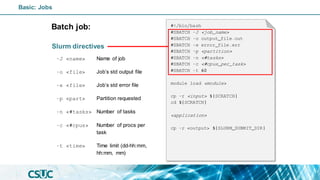
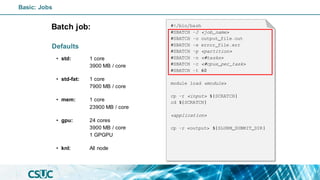
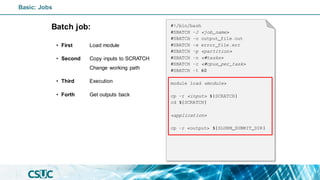
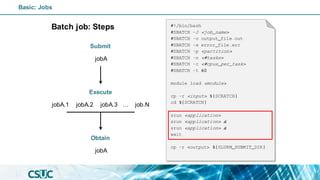
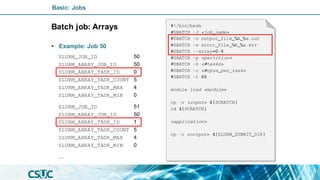
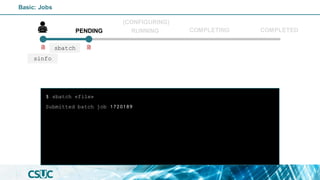
#!/bin/bash
#SBATCH -J <job_name>
#SBATCH -o output_file.out
#SBATCH -e error_file.err
#SBATCH -p <partition>
#SBATCH -n <#tasks>
#SBATCH -c <#cpus_per_task>
#SBATCH -t 60
#SBATCH --dependency=afterok:<jid>
module load <module>
cp -r <input> ${SCRATCH}
cd ${SCRATCH}
<application>
cp -r <output> ${SLURM_SUBMIT_DIR}
Basic: Jobs](https://image.slidesharecdn.com/introslurm-221220122340-16fa1314/85/Introduction-to-Slurm-41-320.jpg)
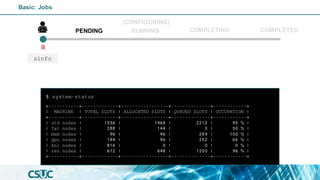
![PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
std* up infinite 19 mix pirineus[7,34-35,37-40,45]
std* up infinite 25 alloc pirineus[8,11-17,19-33,36,41-44,46-50]
std-fat up infinite 1 mix pirineus45
std-fat up infinite 5 alloc pirineus[46-50]
gpu up infinite 4 idle~ pirineusgpu[1-4]
knl up infinite 4 idle~ pirineusknl[1-4]
mem up infinite 2 mix canigo[1-2]
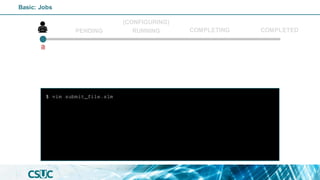
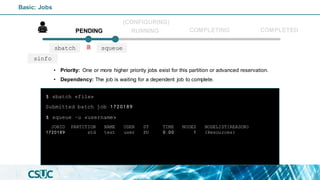
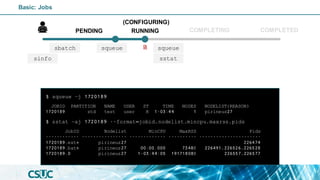
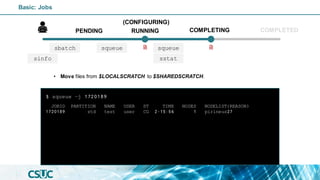
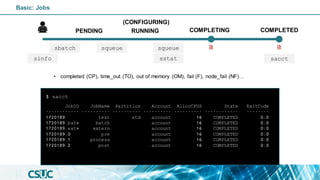
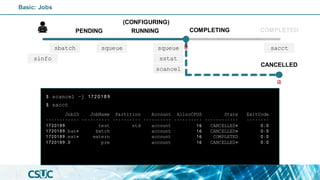
$ sinfo
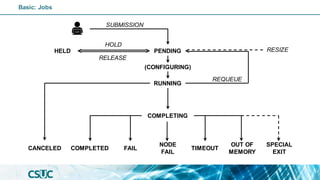
PENDING
(CONFIGURING)
RUNNING COMPLETED
COMPLETING
Basic: Jobs
sinfo](https://image.slidesharecdn.com/introslurm-221220122340-16fa1314/85/Introduction-to-Slurm-43-320.jpg)



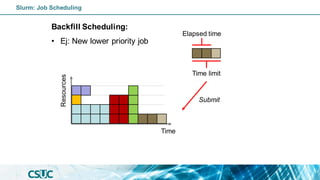
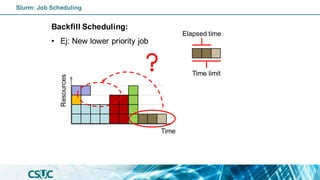
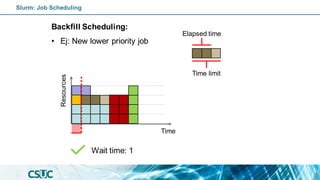
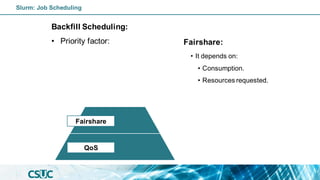
The document serves as an introduction to SLURM, an open-source resource manager and job scheduler for managing compute clusters. It outlines SLURM's functionalities, including resource allocation, job scheduling strategies, and detailed commands for job submission and management. Additionally, it explains how to use SLURM efficiently, covering various job types, scheduling priorities, and resource management in a high-performance computing (HPC) environment.























































































