Download as PDF, PPTX







![Bilofsky & Burks (1988)
Nucleic Acids Research v16 n5
“The author will provide the
accession number to the
PROCEEDINGS [PNAS]
office to be included in a
footnote to the published
paper.”
1989](https://image.slidesharecdn.com/openconmouncedata-141115074152-conversion-gate02/75/The-State-of-Open-Research-Data-9-2048.jpg)


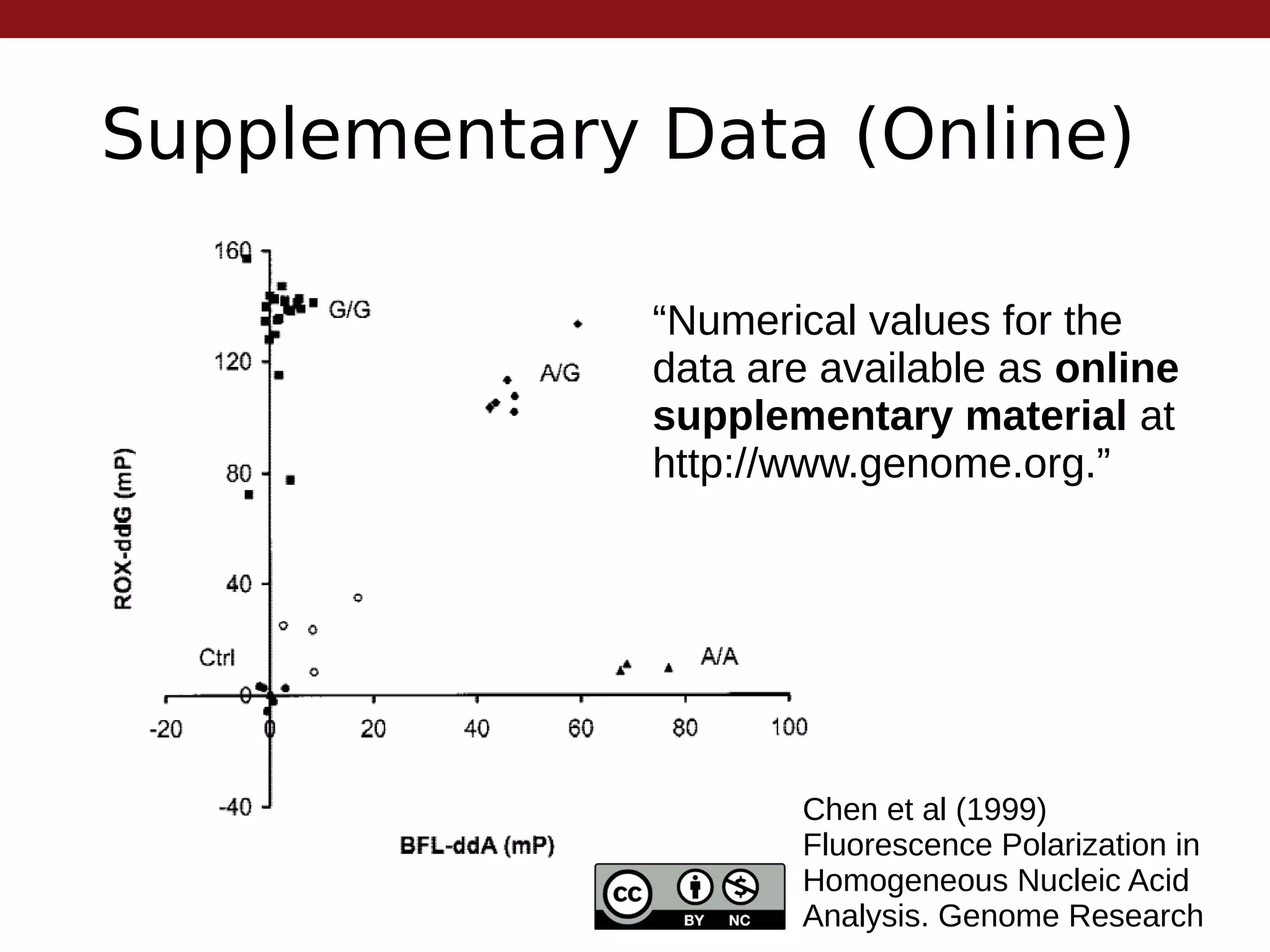







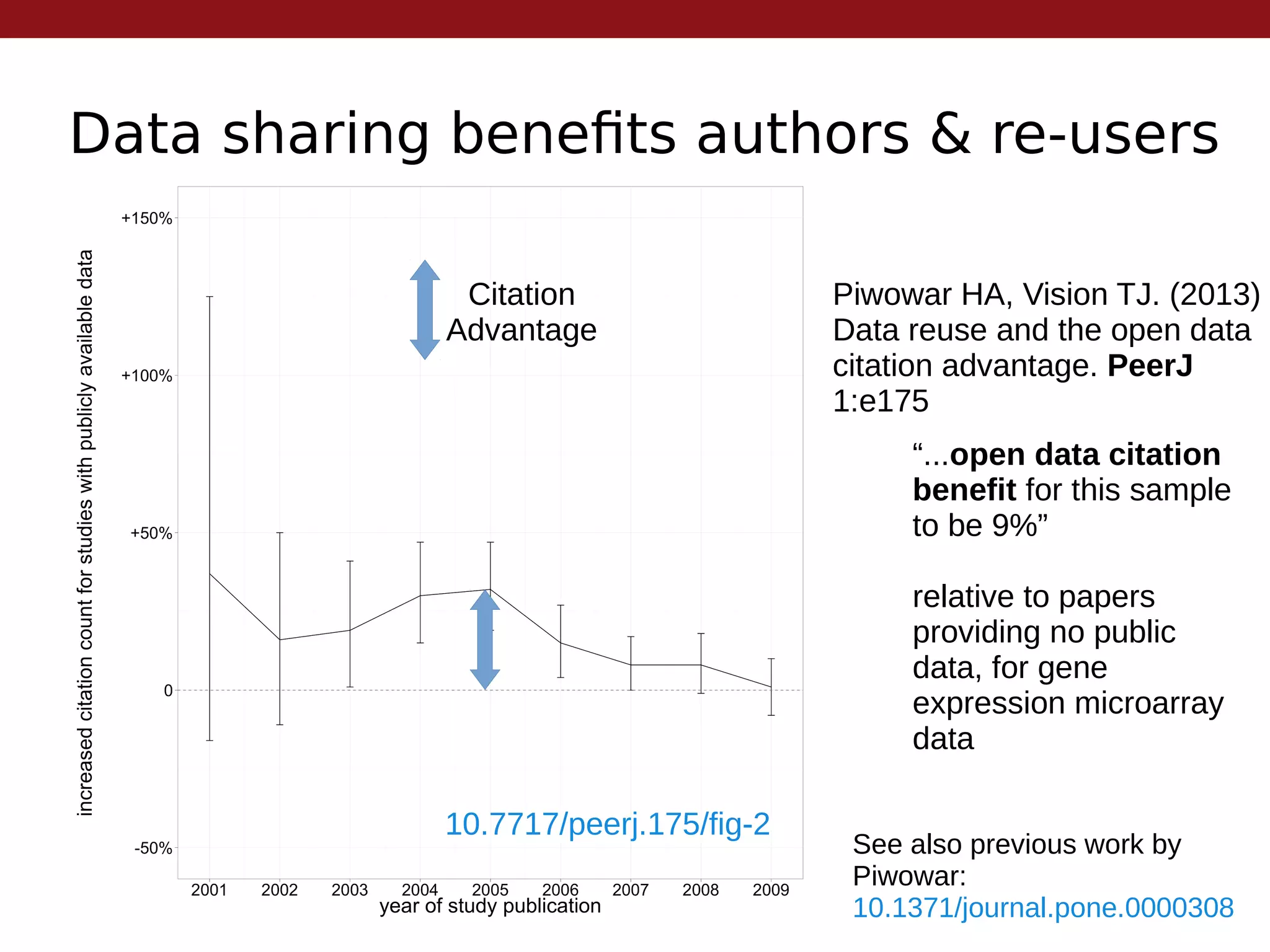



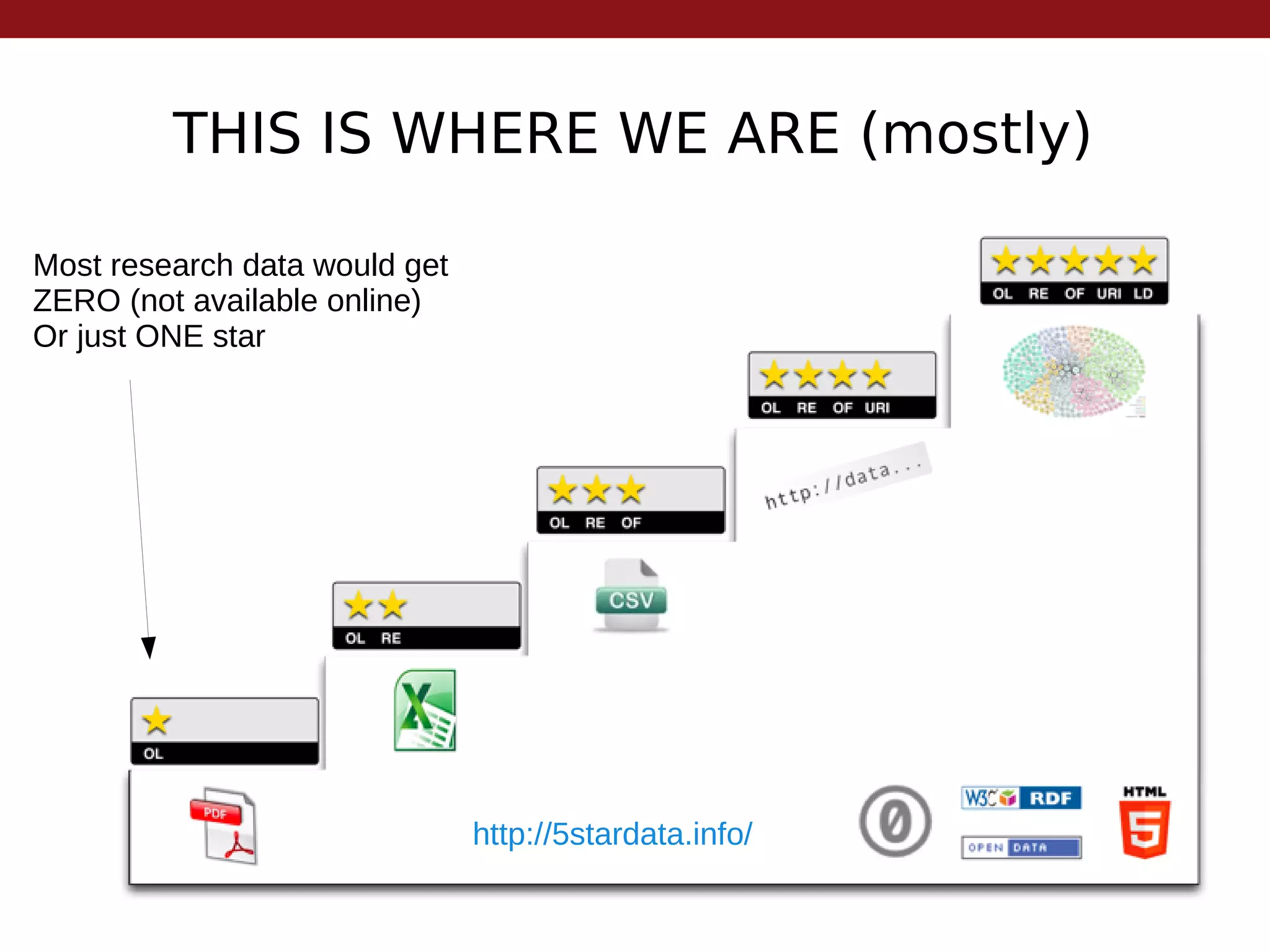





This document summarizes the state of open research data by outlining its evolution over time. It begins with centralized data centers in the 1960s and progresses to more collaborative models of data sharing through community agreements and online supplementary materials. The benefits of open data are discussed, including increased reproducibility and citation advantages for authors who share. While open data is ideal, achieving 3-star open standards according to the 5 star scheme is currently realistic. The future may bring stricter funding and publishing requirements to encourage more widespread data sharing.






![Open scholarship [a FOSTER open science talk]](https://cdn.slidesharecdn.com/ss_thumbnails/openscholarshipfoster-140904081612-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













































































