Download as PDF, PPTX




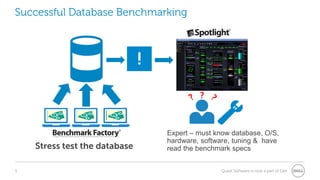





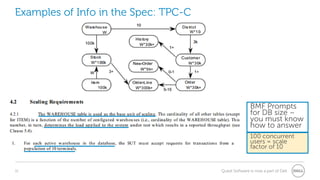





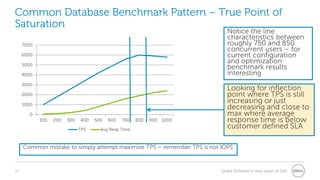
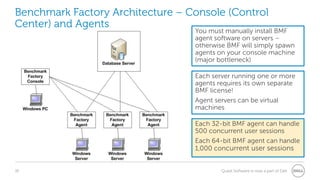
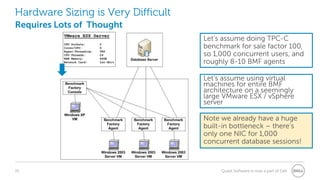
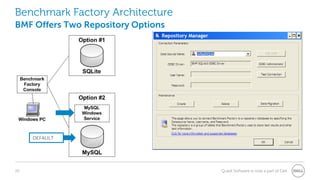
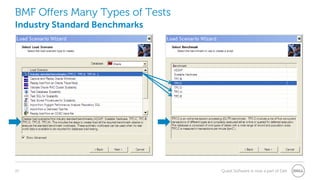
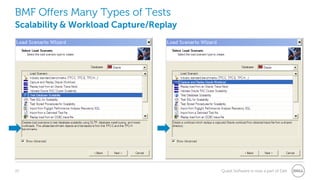
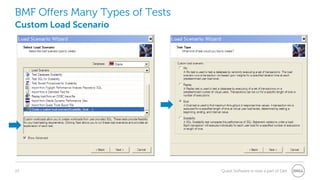

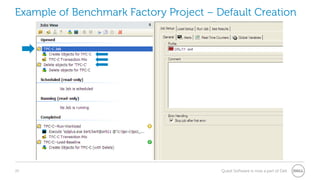
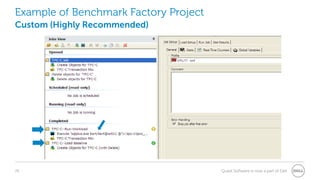
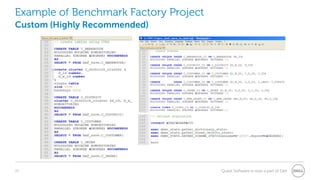
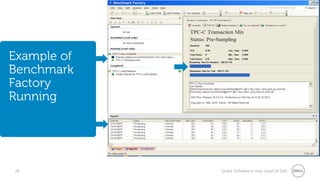
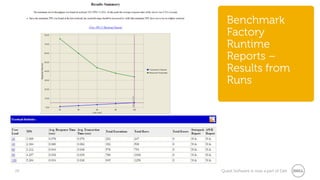





The document provides a comprehensive overview of database benchmarking using Benchmark Factory, highlighting the importance of expertise in database management, tools, and preparation to avoid common mistakes. It discusses industry-standard benchmarks, metrics, and the architecture of Benchmark Factory, emphasizing the need to optimize for average response time rather than just transactions per second. Additionally, it offers resources for further learning and insights into benchmarking best practices.


























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








