










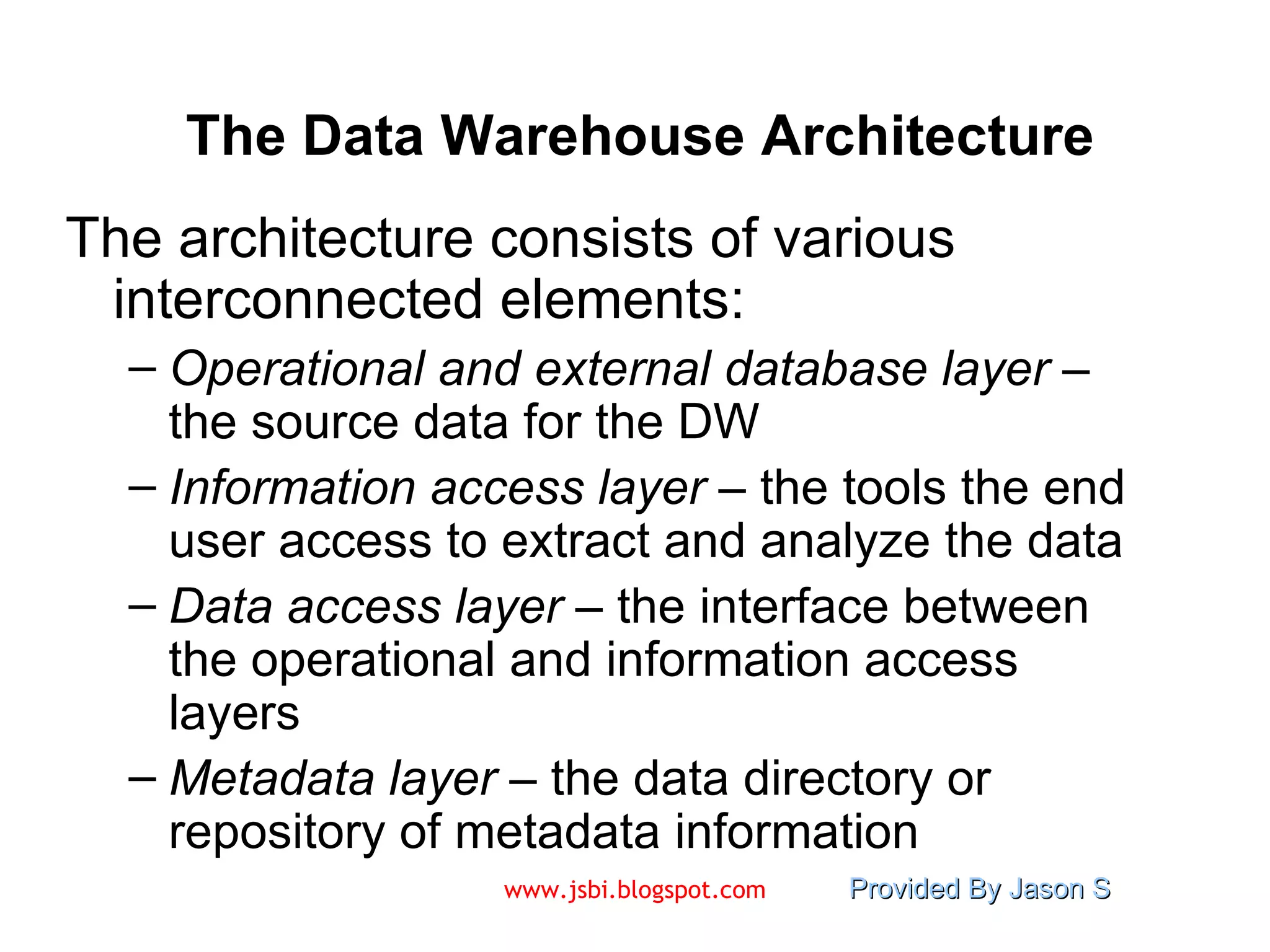

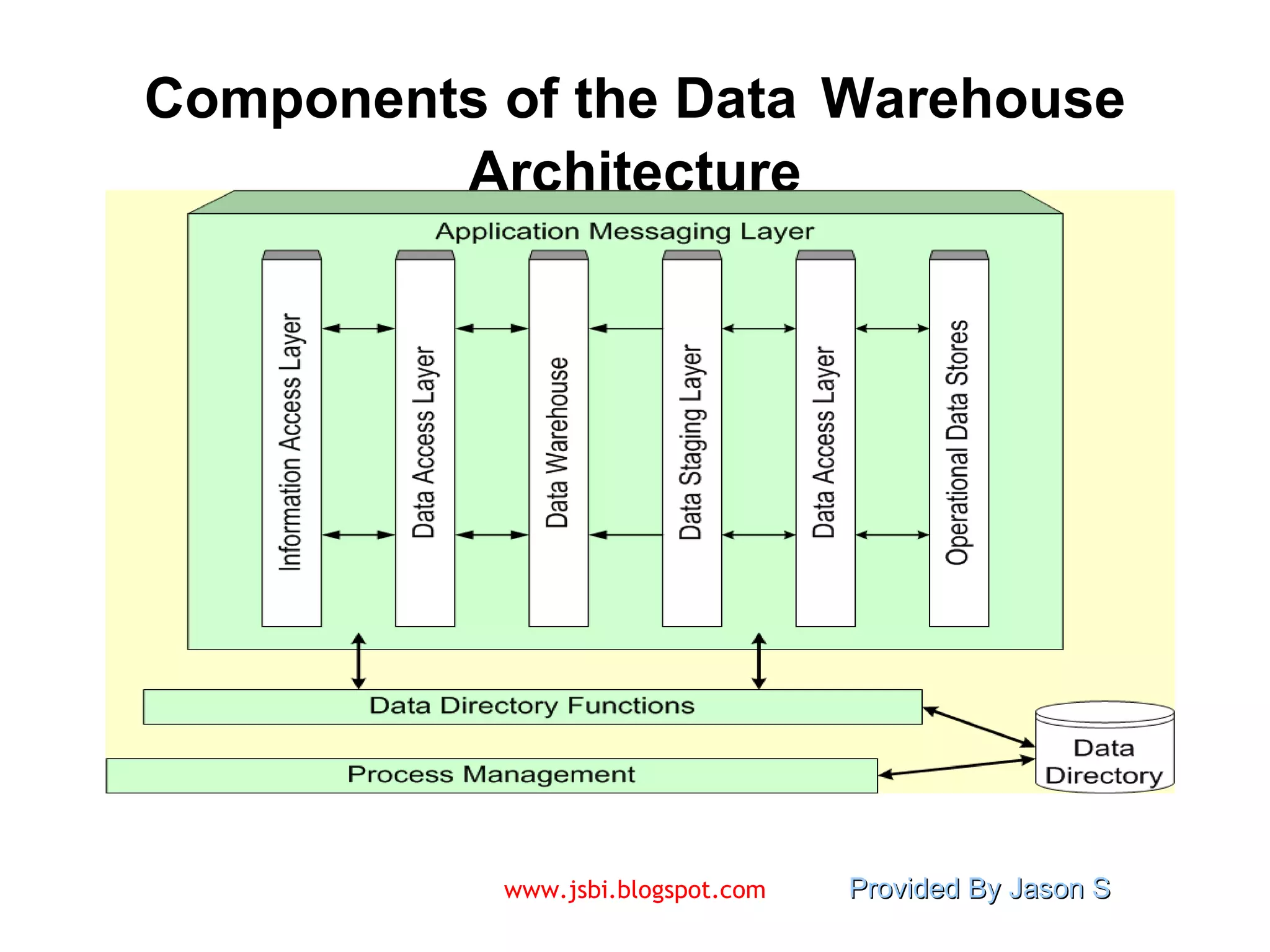







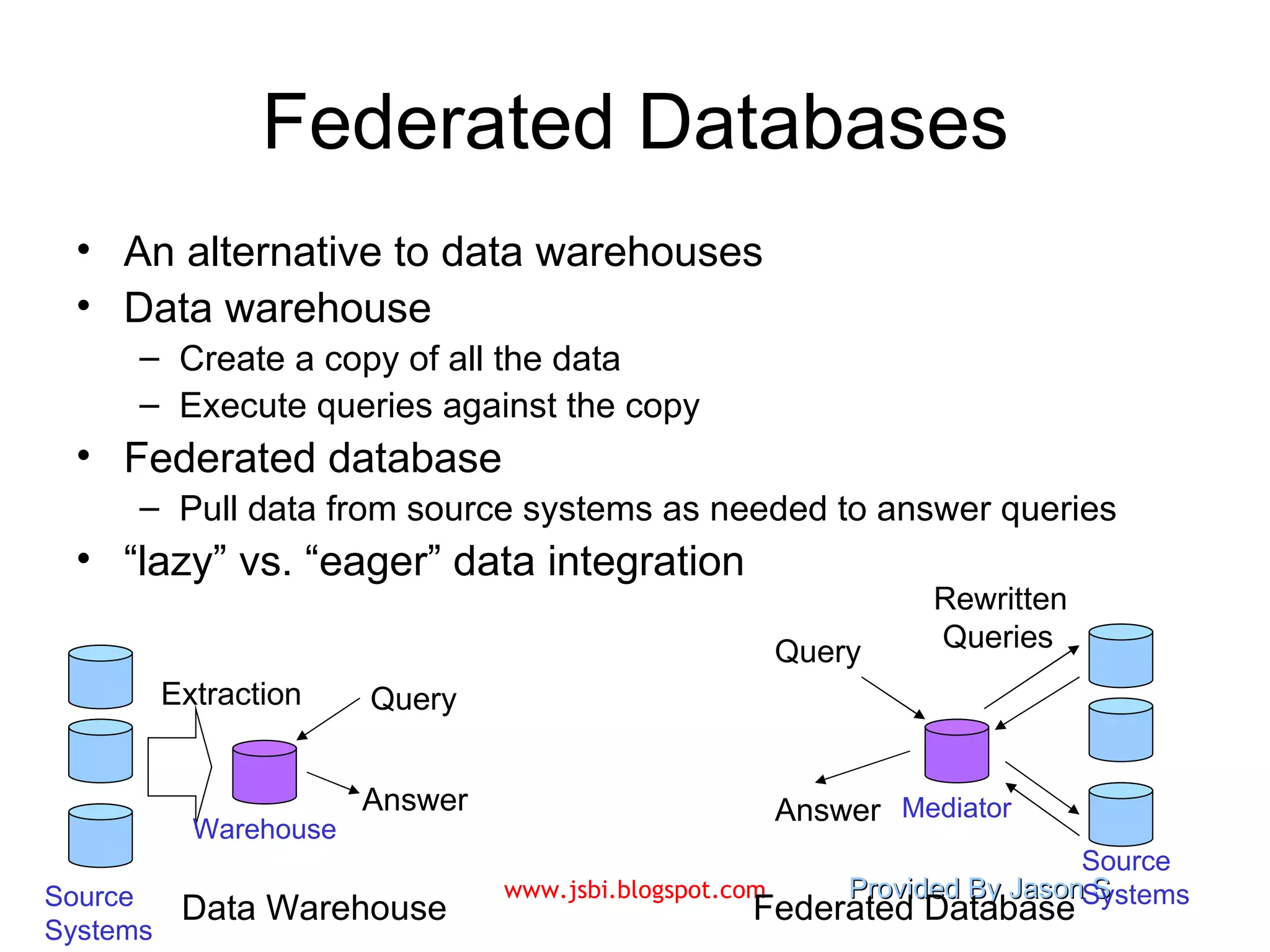

![Visit www.jsbi.blogspot.com for more slides/information!! Mail : [email_address]](https://image.slidesharecdn.com/introduction-to-data-warehousing-9609/75/Introduction-to-Data-Warehousing-28-2048.jpg)

The document provides an overview of data warehousing and decision support systems. It discusses how data warehouses evolved from databases used for transaction processing to integrated databases designed for analysis and decision making. Key points include: - Data warehouses store historical data from multiple sources to support analysis and decision making. - They address limitations of transactional databases that are optimized for real-time queries rather than complex analysis. - Effective data warehousing requires resolving data conflicts, documenting assumptions, and learning from mistakes in the implementation process.























































































