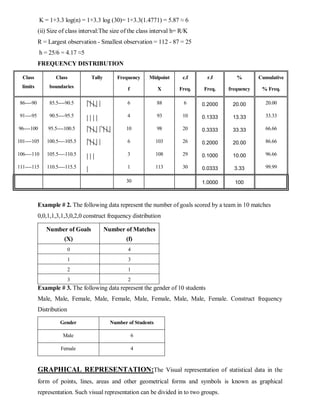
This document provides an introduction to statistics, including definitions, reasons for studying statistics, and the scope and importance of statistics. It discusses how statistics is used in fields like insurance, medicine, administration, banking, agriculture, business, and sciences. It also outlines the main functions of statistics and its branches, including theoretical, descriptive, inferential, and applied statistics. Finally, it covers topics related to data representation, including methods of presenting data through tables, graphs, and diagrams.











![De-Merits of Arithmetic Mean:
It is not an appropriate average for highly-skewed distribution.
It is greatly affected by by extreme values.
It cannot be calculated for open-end classes.
It may be a value which is usually not present in the data.
It cannot be computed accurately even one item is missing.
Aleast one value will be greater and atleast one will be less than mean.
Geometric mean and Harmonic mean are useful measure of central tendency for averaging
rates and ratios.
Geometric mean:- The geometric mean is the nth
root of the product of n positive values.
For ungrouped data )
X
X
X
(X
=
G n
1
n
*
...
*
*
* 3
2
1 OR
n
X
Antilog
=
G
n
X
=
n
]
X
...
x
+
x
[
=
G k
2
1
log
log
log
log
log
Log
For grouped data f
f
n
f
f
f n
X
X
X
X
=
G
1
3
2
1 )
(
*
...
*
)
(
*
)
(
*
)
( 3
2
1
Where, n denote total number of classes OR
f
X
f
Antilog
=
G
f
X
f
=
f
...
f
+
f
+
f
X
f
...
X
f
+
X
f
+
X
f
=
G
n
3
2
1
n
n
3
3
2
2
1
1
log
log
log
log
log
log
Log
Merits of Geometric Mean:
It is clearly defined by mathematical formula.
It is based on all the observations.
It is least affected by extreme values.
It is suitable for further algebraic treatments.
It gives equal weights to all the values.
It is an appropriate average for averaging rates of change and ratios.
De-Merits of Geometric Mean:
It is neither easy to calculate nor simple to understand.
It cannot be calculated if any value is zero or negative in the data.
It cannot be calculated in case of open-end frequency distribution.
Example # 10. Find the Geometric mean of the values 3, 5, 6, 6, 7, 10, 12.
X 3 5 6 6 7 10 12 Total
log(X) .4771 .6989 .7782 .7782 .8451 1.000 1.0792 5.65677](https://image.slidesharecdn.com/introtostatisticaltheory-231117051817-7228d1f7/85/INTRO-to-STATISTICAL-THEORY-pdf-12-320.jpg)










































































