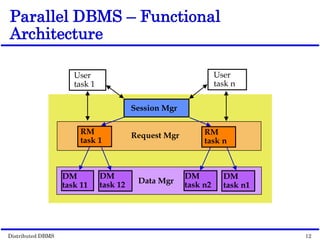
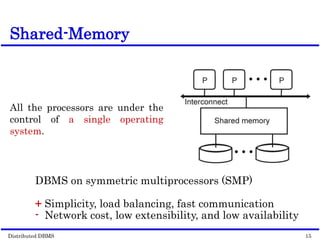
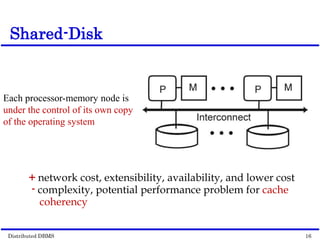
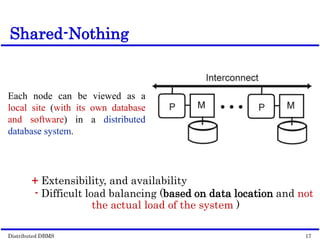
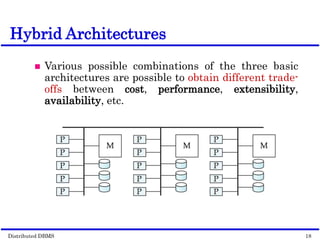
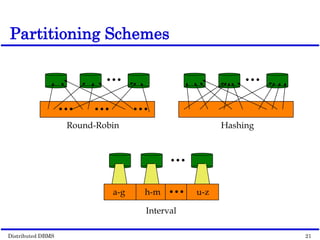
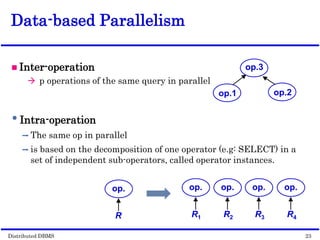
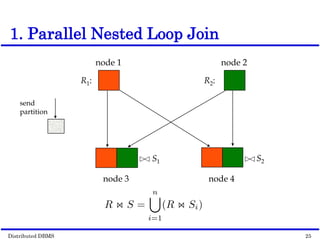
This document discusses parallel database management systems (DBMS) and distributed DBMS. It covers topics like the database problem of handling large volumes of data, solutions like data partitioning and parallel data access. It describes objectives of parallel DBMS like high performance and availability. It discusses hardware architectures for parallel DBMS like shared memory, shared disk and shared nothing. It also covers techniques for parallel DBMS including data placement, parallel query processing and optimization, and challenges of load balancing.
















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
















