Download to read offline











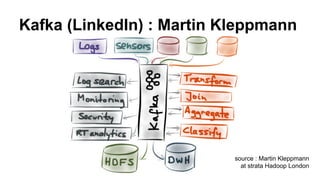




This document provides an agenda for a StreamProcessing.be meetup event on hosted solutions for stream processing and machine learning. The agenda includes presentations on Azure Stream Analytics and ML, Google Cloud DataFlow, and Amazon AWS ML. It also announces the next meetup focused on Apache Kafka, Akka Streams, Kinesis, and Spark Streaming. Additionally, it introduces the organizer Peter Vandenabeele and discusses his views on why stream processing is important for real-time big data processing and allowing data to serve as the system of record.




















































































