



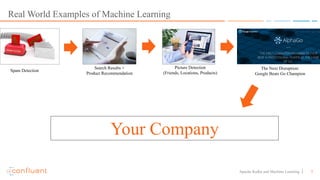
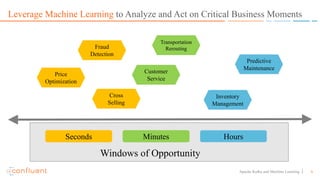
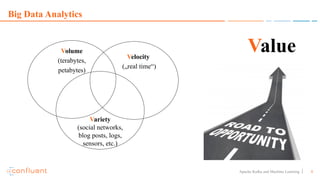

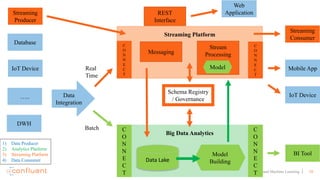

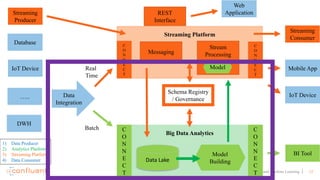
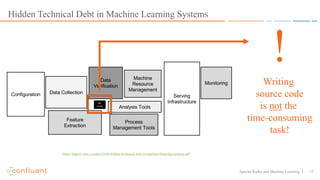


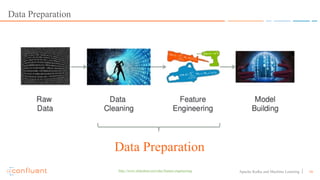


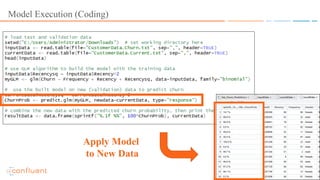





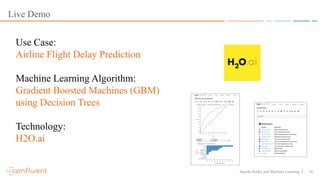




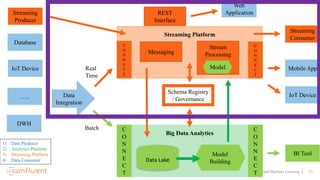
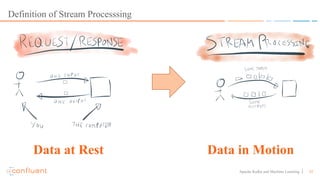
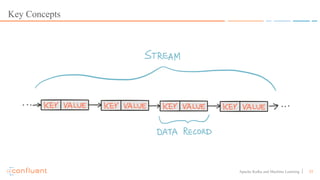
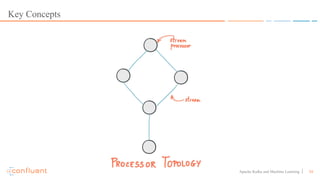
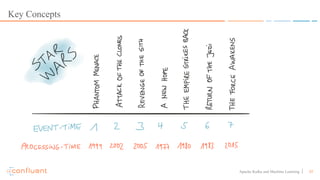
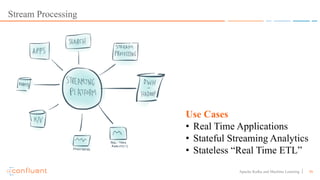
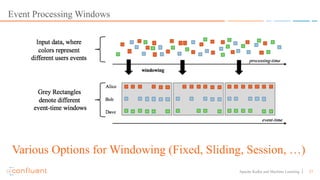

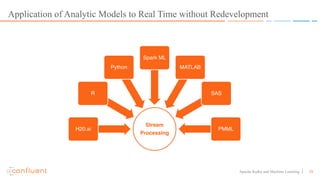
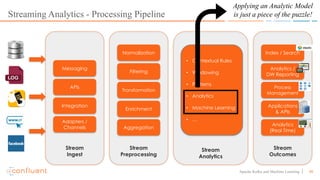
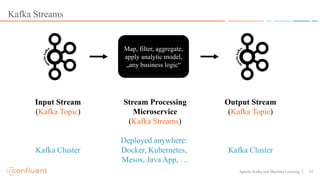
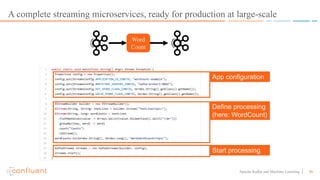
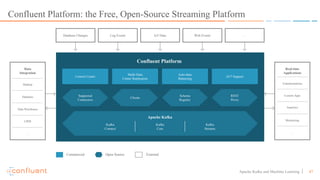
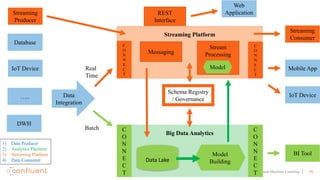
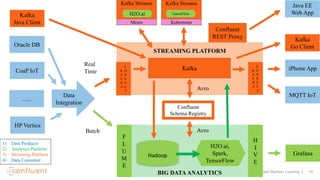


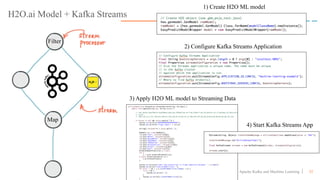
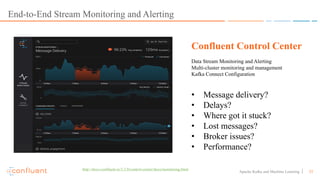




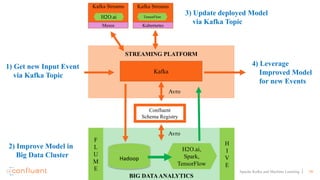




This document discusses applying machine learning models to real-time stream processing using Apache Kafka. It covers building analytic models from historical data, applying those models to real-time streams without redevelopment, and techniques for online training of models. Live demos are presented using open source tools like Kafka Streams, Kafka Connect, and H2O to apply machine learning to streaming use cases like flight delay prediction. The key takeaway is that streaming platforms can leverage pre-built machine learning models to power real-time analytics and actions.





























































































