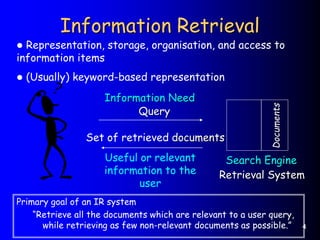
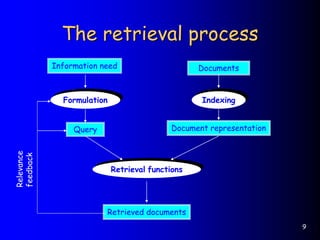
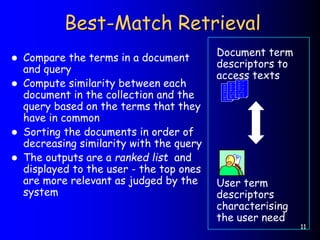
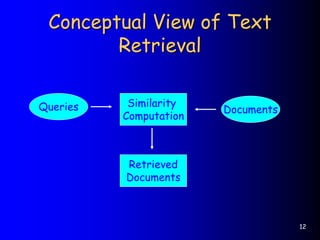
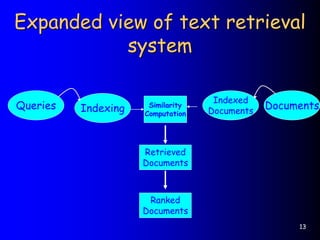
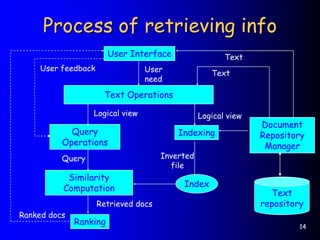
This document provides an introduction to information retrieval. It defines information retrieval as representing, storing, organizing, and accessing information items, usually based on keyword representations. The primary goal of an information retrieval system is to retrieve all documents relevant to a user's query while retrieving as few non-relevant documents as possible. The document outlines several key components of an information retrieval system including documents, queries, indexing, similarity computation, and ranking.









![16
Information Retrieval
vs Information Extraction
Information Retrieval
– Given a set of query terms and a set of document
terms select only the most relevant documents
[precision], and preferably all the relevant [recall].
Information Extraction
– Extract from the text what the document means.
IR systems can FIND documents but need not
“understand” them](https://image.slidesharecdn.com/irintroduction-230810174635-9a0a261f/85/IRintroduction-ppt-16-320.jpg)















































